-

MSA 아키텍처에서 CQRS 패턴: 개념부터 실전 적용까지
by
I. 서론 기업들이 모놀리식 아키텍처에서 마이크로서비스 아키텍처(MSA, Microservices Architecture)로 전환하면서, 데이터 관리에 대한 근본적인 재고가 필요해지고 있다. MSA에서는 각 서비스가 독립된 데이터베이스를 보유하므로(Database per Service), 여러 서비스에 걸친 데이터 조회가 복잡해지고 읽기/쓰기 워크로드의 독립적 확장이 어려워진다. 이 문제를 해결하기 위해 … 더 보기
-

생성 모델의 발전 과정과 이상탐지 분야에서의 활용
by
생성 모델(Generative Model)은 데이터의 확률 분포를 학습하여 새로운 데이터를 생성하는 모델입니다. 생성형 AI의 핵심 기술로 주목받고 있으며, 이미지 생성뿐만 아니라 이상탐지(Anomaly Detection), 데이터 증강(Data Augmentation) 등 다양한 산업 분야에서 활용되고 있습니다. AI 도입이 기업 전반으로 확대되면서 생성 모델의 활용 범위 … 더 보기
-

공간 데이터, 연결되어 보인다고 연결된 게 아닙니다
by
네트워크 통합부터 E2SFCA 접근성 분석까지 들어가며 공간 데이터를 다루다 보면 한 번쯤 이런 경험을 하게 됩니다. QGIS나 지도 화면에서 보면 도로가 분명히 이어져 있는데, 파이썬에서 경로 분석을 돌려보면 엉뚱한 결과가 나옵니다. 두 지점 사이에 분명히 도로가 있고, 거리도 가까운데, 알고리즘은 … 더 보기
-
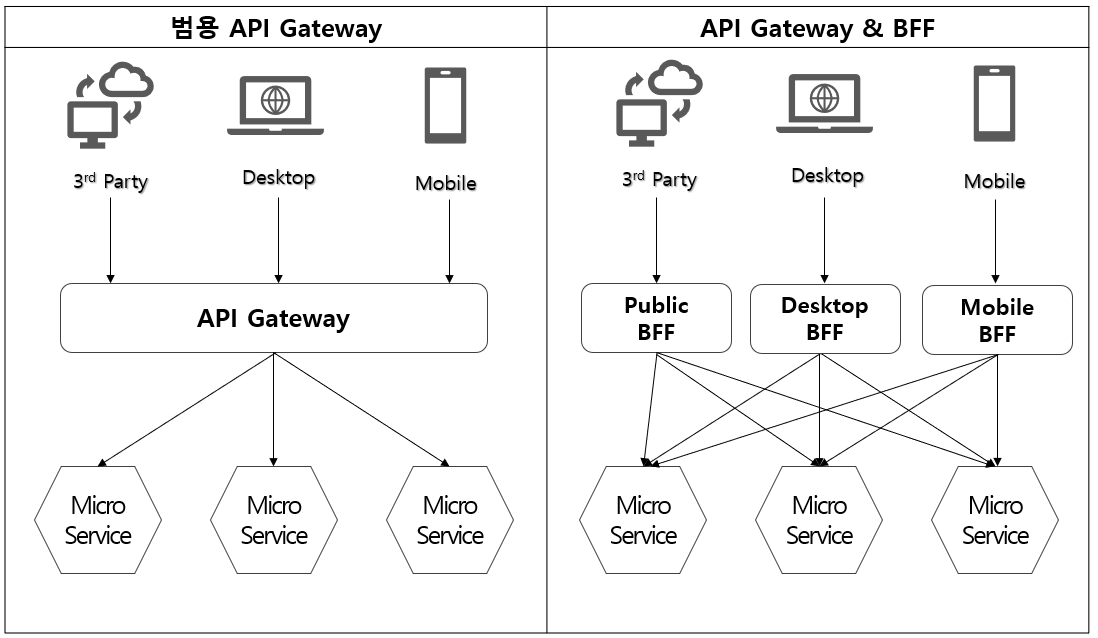
MSA기반 시스템의 성능저하의 주요요인과 이를 해결하기 위한 방법
by
Microservices Architecture(MSA)는 확장성과 유연성을 제공하는 현대적 시스템 구조이지만, 실제 운영 환경에서는 구조적 특성으로 인해 다양한 성능 저하 문제가 발생한다. 이러한 문제는 단순한 구현 수준의 이슈가 아니라, 서비스 분산에 따른 네트워크, 데이터, 호출 방식, 장애 전파 구조 등에서 기인한다. 따라서 각 … 더 보기
-
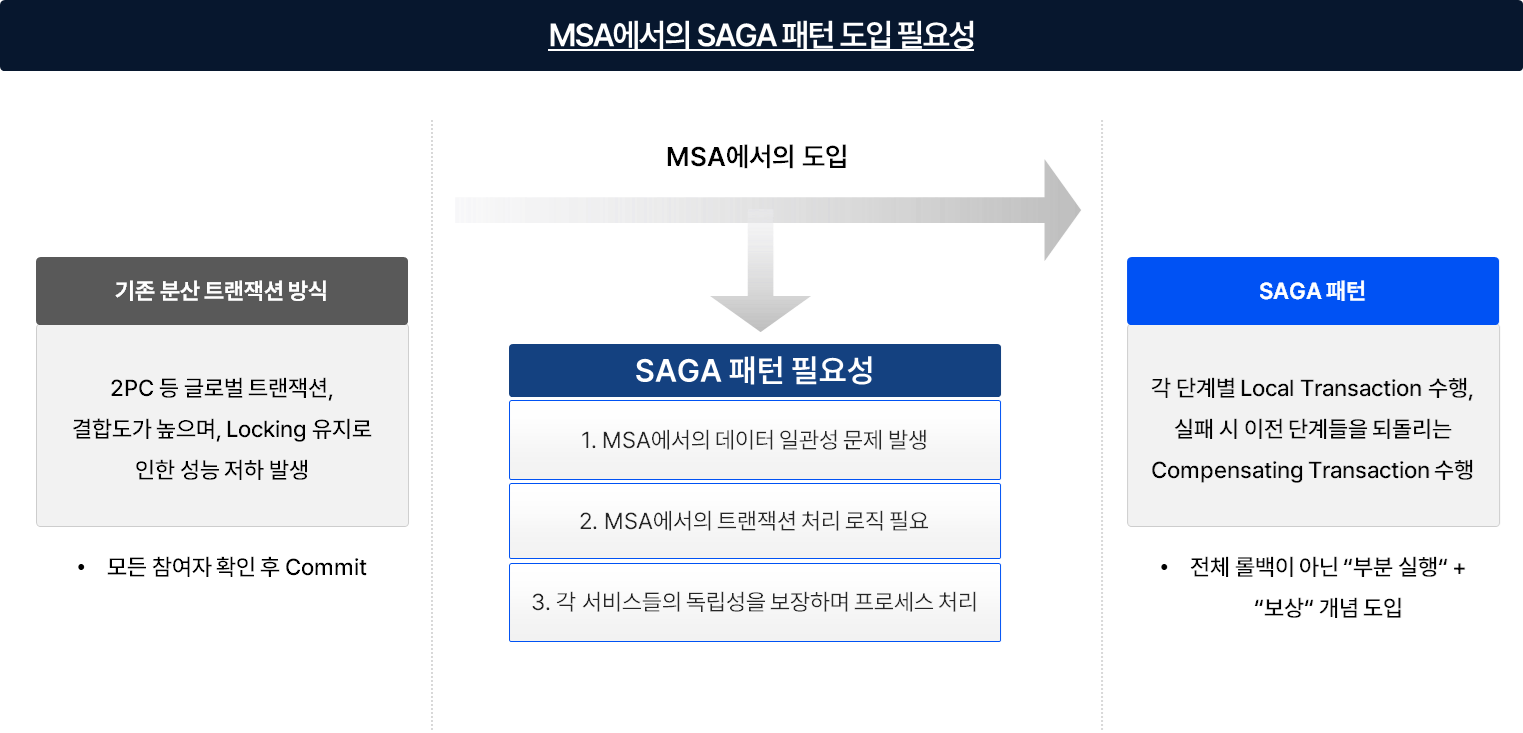
MSA 아키텍처에서 SAGA 패턴: 개념, 활용 방법, 사례 및 고려사항
by
1. 서론 최근 디지털 서비스 환경은 빠른 변화와 확장성을 요구받고 있으며, 이에 따라 마이크로서비스 아키텍처(MSA, Microservice Architecture)가 주요 설계 방식으로 자리잡고 있다. MSA는 서비스 단위를 작게 나누어 독립적으로 개발, 배포, 확장이 가능하다는 장점을 가지지만, 동시에 데이터 일관성과 트랜잭션 처리라는 새로운 … 더 보기
-
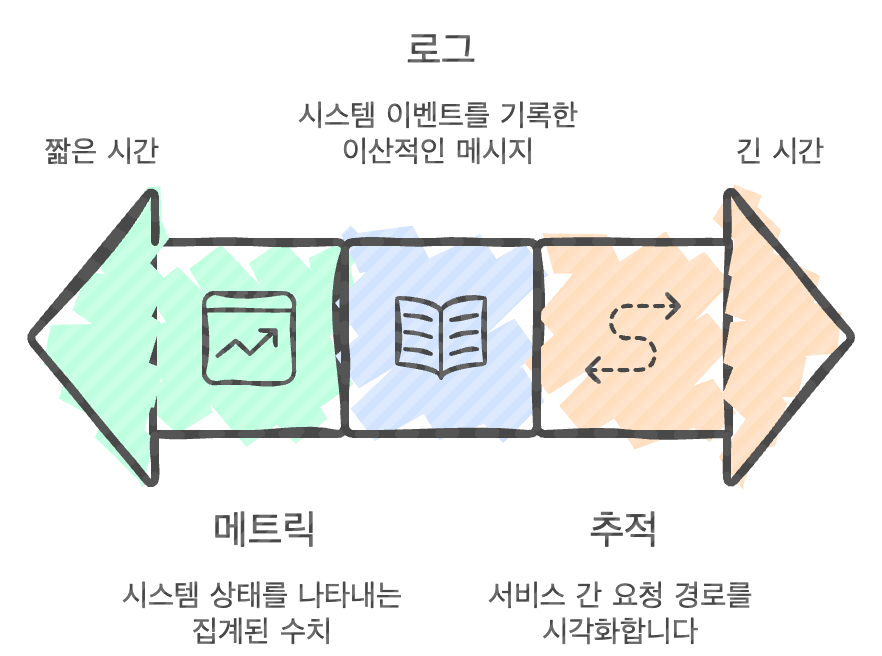
MSA와 DDD 관점에서 바라본 운영의 Observability 표준 (Logs/Metrics/Tracing)
by
마이크로서비스 아키텍처(MSA)의 확산은 도메인별 독립 배포와 무중단 확장이라는 강력한 이점을 제공하는 동시에, 수십·수백 개 서비스가 맞물린 환경에서 “로그는 남는데 원인은 알 수 없는” 운영 복잡성이라는 근본적인 과제를 안겨주고 있다. 이 과제의 해법으로 주목받는 관찰 가능성(Observability)은 단순한 모니터링을 넘어, 로그(Logs)·메트릭(Metrics)·분산 추적(Tracing)이라는 … 더 보기
-
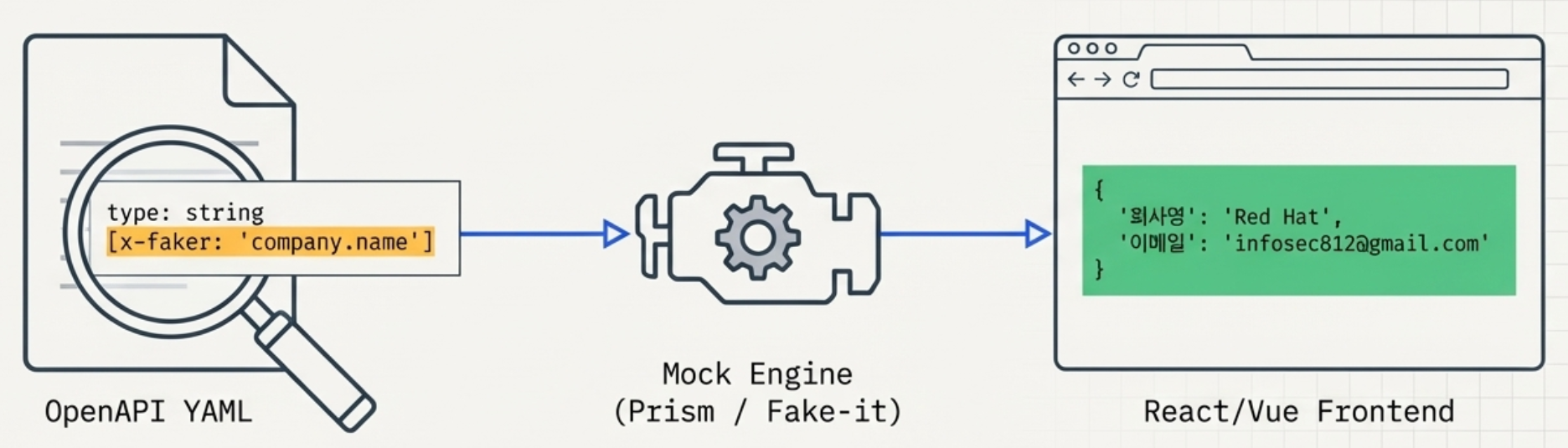
Code-First에서 Contract-First로 : OpenAPI와 AsyncAPI
by
역사는 반복된다 – WSDL에서 REST, 그리고 다시 계약으로 현대의 소프트웨어 아키텍처는 수많은 마이크로서비스와 외부 시스템이 얽힌 거대한 복잡한 생태계를 구성하고 있습니다. HTTP 기반 웹 환경에서 API(Application Programming Interface)는 가장 널리 쓰이는 통신 방식으로, 복잡한 디지털 인프라 환경에서 시스템 간 연결을 … 더 보기
-
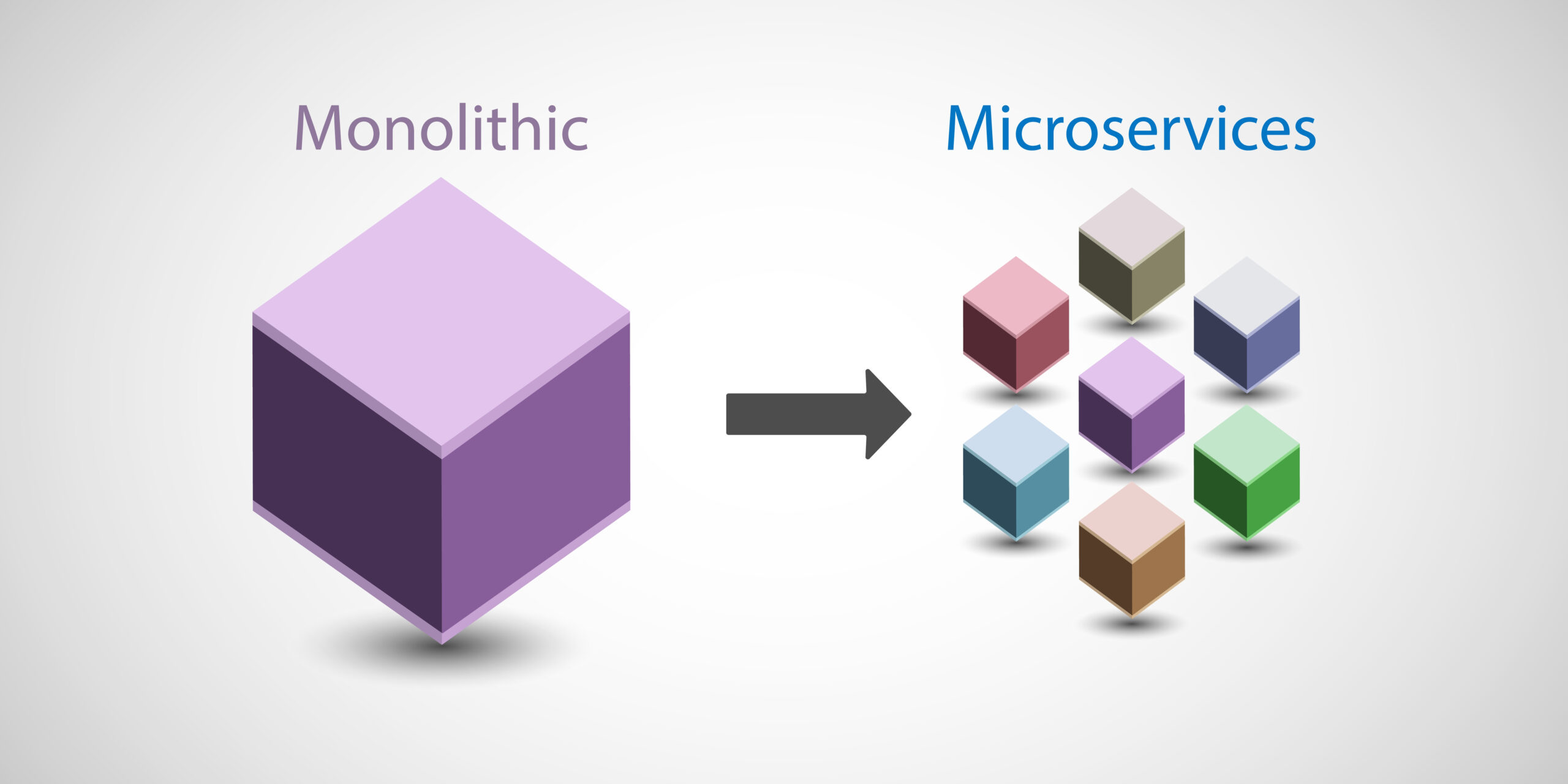
MSA 기반 시스템의 성능저하의 주요 요인과 이를 해결하기 위한 방법
by
2010 년대 초반, 아마존, 넷플릭스, 구글 등 글로벌 테크 기업들은 대규모 트래픽 처리와 빠른 서비스 배포를 위해 모놀리식(Monolithic) 아키텍처에서 마이크로서비스 아키텍처(MSA)로의 전환을 시작하였다. 2014 년 이후 MSA 개념이 대중화되었고, 한국에서는 2016 년 파스타 (PaaS-TA) 오픈을 기점으로 카카오, 네이버, 쿠팡, 배달의 … 더 보기
-
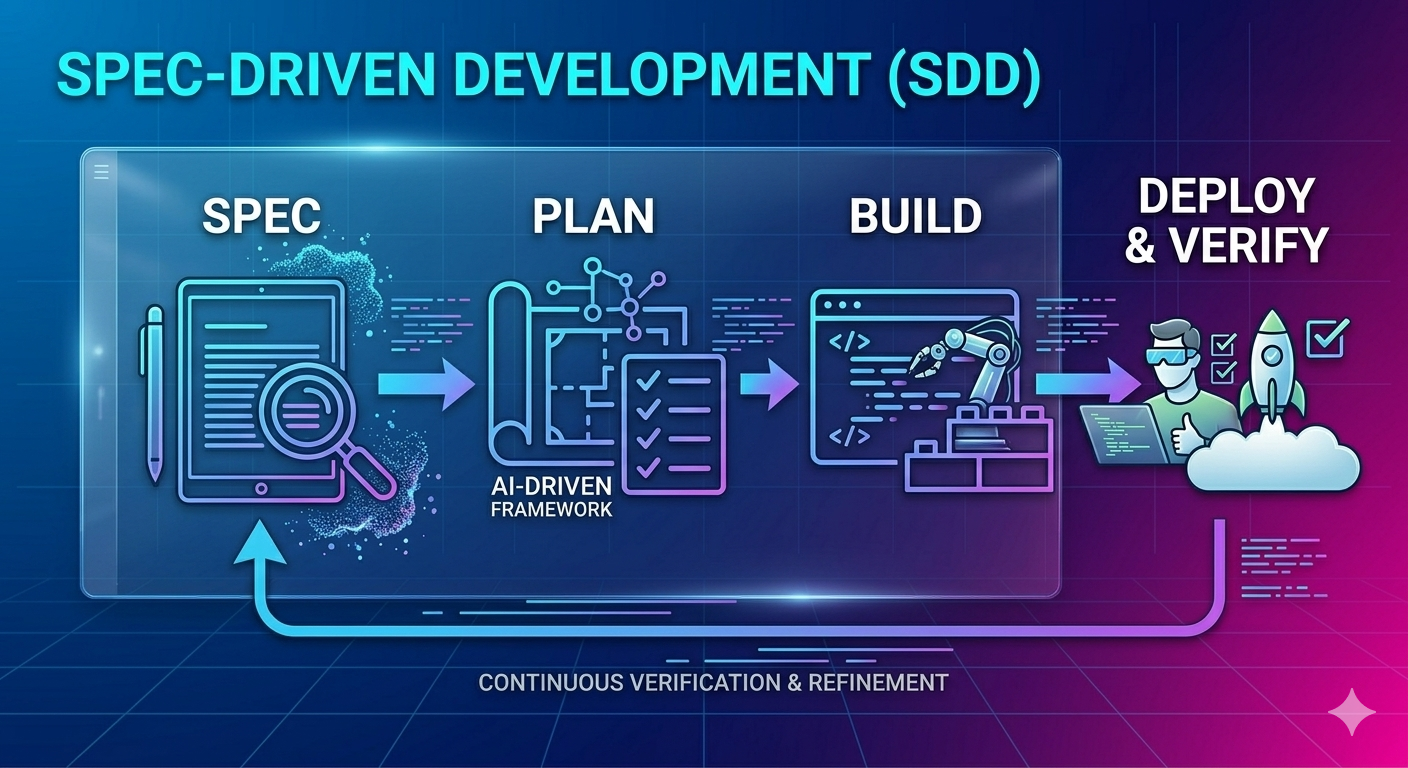
명세 주도 개발(Spec-Driven Development) : AI 코딩 시대, “Less is More”의 개발 설계 원칙
by
AI 코딩 도구가 코드를 “생성”하는 것은 이제 놀랍지 않다. 진짜 문제는 그 코드가 의도한 대로 동작하게 만드는 것이다. 이 글은 AI 코딩의 현실적 한계에서 출발하여, “Less is More” 원칙에 기반한 명세 주도 개발(SDD, Spec-Driven Development)의 개념, 구현 전략, 그리고 엔터프라이즈 … 더 보기
-
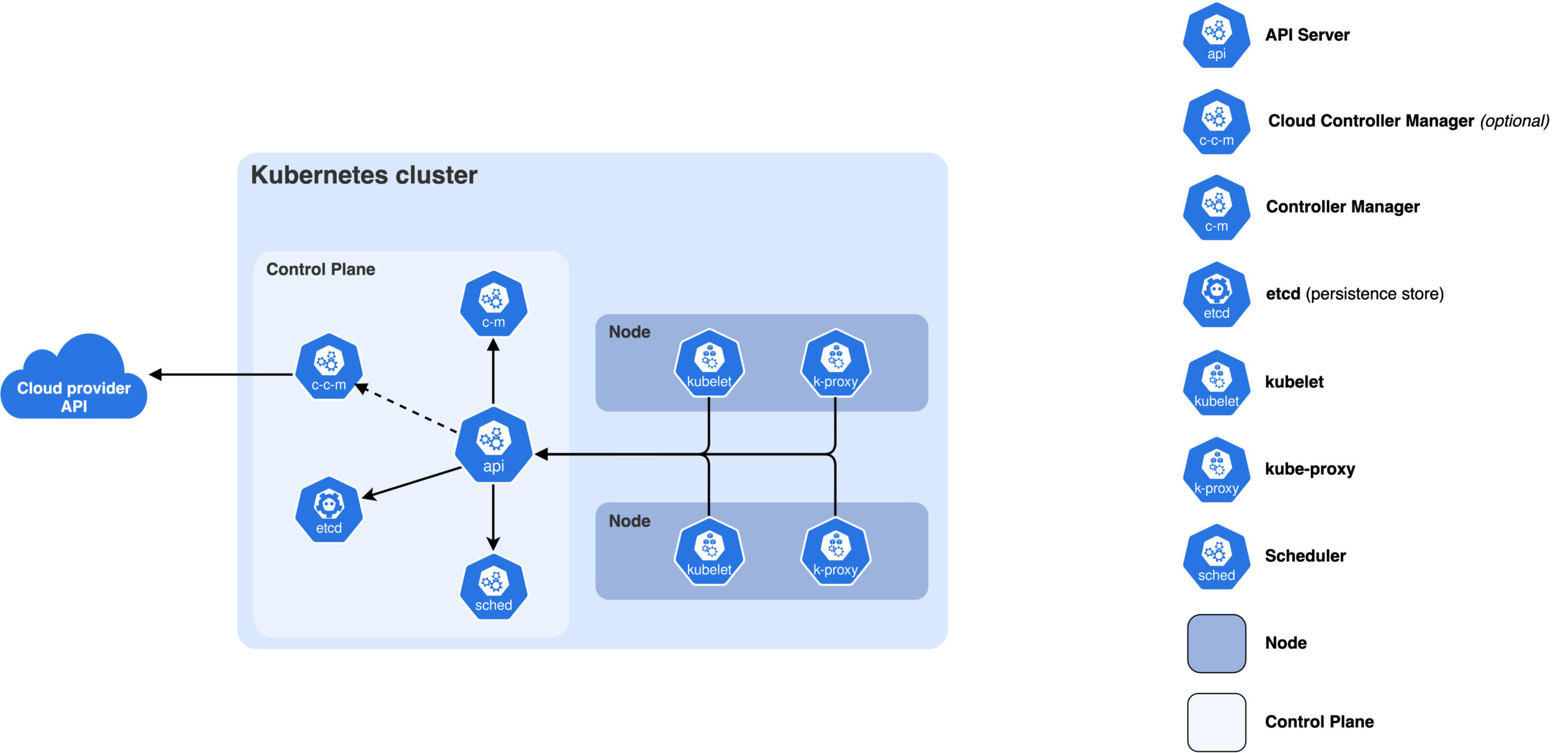
Minikube로 시작하는 쿠버네티스
by
개념부터 실전 운영까지 — AI·데이터 직군을 위한 실습 정리 Kubernetes Cluster Architecture (출처: kubernetes.io) “로컬에서는 잘 되는데 서버에서만 안 돼요…” “환경이 달라서 재현이 안 됩니다…” AI·빅데이터 업무를 하다 보면 한 번쯤 겪어봤거나 들어봤을 상황입니다. 이런 문제를 줄이기 위해 등장한 것이 … 더 보기