순환신경망(RNN: Recurrent Neural Networks) 기반 자연어 처리
1. 자연어의 분산 표현
기계 학습을 통해 자연어, 텍스트 데이터를 처리할 때는 단어를 벡터로 변환, 벡터화(vectorization)하여 연산한다. 구체적으로는, 기계가 학습하는 자연어 데이터에서 특정 단어 주변(또는 맥락; context)에서 함께 사용된 단어들을 활용하여 단어를 밀집 벡터(dense vector)로 나타낸다. 이를 임베딩(embedding) 또는 분산 표현(distributed representation; distributional representation)이라고도 한다.
이는 언어학적으로 분포 의미론 (distributional semantics) 또는 분포 가설 (distributional hypothesis)에 근거하고 있다. 20세기 언어학자 J.R. Firth는 언어의 의미와 단어의 배치에 관하여 다음과 같이 설명하였다, ‘단어가 곁에 두는 친구를 보면 그 단어를 알 수 있다. (You shall know a word by the company it keeps.)’ [1] 즉 단어의 의미가 주변 단어들에 의해 형성된다는 것이다.
2. 통계적 자연어 처리
과거에는 자연어 처리에 자연어 데이터를 한꺼번에 일괄적으로 학습, 즉 배치 학습(batch learning)하여 각 단어 당 주변 단어 분포를 등장 빈도(frequency)에 따라 동시 발생 행렬(co-occurrence matrix)로 표현하는 방법을 사용하였다. 구체적으로는 동시 발생 행렬(co-occurrence matrix)을 만든 다음 문장 고유의 의미에 기여하는 정도가 낮고 단독으로 자주 사용되는 단어를 제하기 위하여 단어 간 상호정보량 (Mutual Information)을 계산한 PPMI 행렬 (Positive Pointwise Mutual Information Matrix)로 변환한다. 그리고 PPMI 행렬을 분산 표현으로 나타낸다.
이를 통계 기반 자연어 처리(statistical NLP)라고도 한다. 그러나 이러한 방식은 학습 데이터가 커질수록 행렬의 크기와 계산량이 기하급수적으로 증가한다는 단점이 있었다. 이를 보완하기 위해 핵심적인 정보는 유지하면서도 단어 벡터의 차원을 줄이기 위해 특잇값 분해 (Singular Value Decomposition; SVD) 방법을 사용하였다. 행렬의 크기가 클수록 SVD 계산에도 많은 시간이 소요되어, 일반적으로Truncated SVD 등을 통해 특잇값이 작은 부분은 제하고 계산한다.
3. 추론적 자연어 처리
한편 신경망 기반 자연어 처리 기법에서는 학습 데이터를 작게 나누어 일부 데이터, 즉 ‘미니 배치(mini-batch)’를 기계가 순차적으로 학습하는 방법을 사용한다. 이 때 기계는 맥락(context) 또는 주변 단어들이 주어졌을 때 특정 위치에 등장할 단어를 추론하는 문제를 반복해서 학습하고, 추론 성능을 개선해 나간다. 따라서 이러한 방법을 ‘추론 기반 자연어 처리’라고도 한다. 미니 배치 학습(mini-batch learning) 방법을 사용할 경우 여러 머신을 병렬적으로 운영하는 병렬 계산이 용이해 져 대규모 데이터를 빠르게 처리할 수 있게 되는 장점이 있다.
4. 자연어 처리 알고리즘의 발전
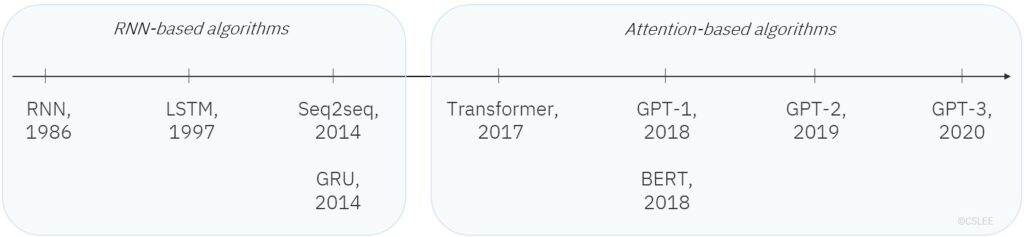
아래 그림은 신경망 기반 자연어 처리 알고리즘의 최근 발전 동향을 시간 순으로 개괄한 것이다: RNN 1986[2],LSTM 1997[3], Seq2seq 2014[4], GRU 2014[5], Transformer 2017[6], GPT-1 2018[7], BERT 2018[8], GPT-2 2019[9], GPT-3 2020[10]
LSTM(Long Short-Term Memory) 1997, GRU(Gated Recurrent Unit) 2014, Seq2seq(Sequence-to-sequence) 2014는 순환신경망 (RNN: Recurrent Neural Networks)을 기반으로 하는 처리 기법으로, 기본적인 RNN 메커니즘을 일부 수정하거나 응용한 버전이다. 그러나 최근 자연어 처리 분야에서는 Attention 이 기존 알고리즘들을 대체하거나 수정하고 최신 기술로 사용되고 있다. RNN 에서는 하나의 고정 길이 벡터에 문장의 정보가 일괄적으로 저장되고, Attention 에서는 입력된 시퀀스 전체를 사용한다는 점에서 기본적인 차이점이 있다.
[그림 1] NLP 알고리즘 발전 동향
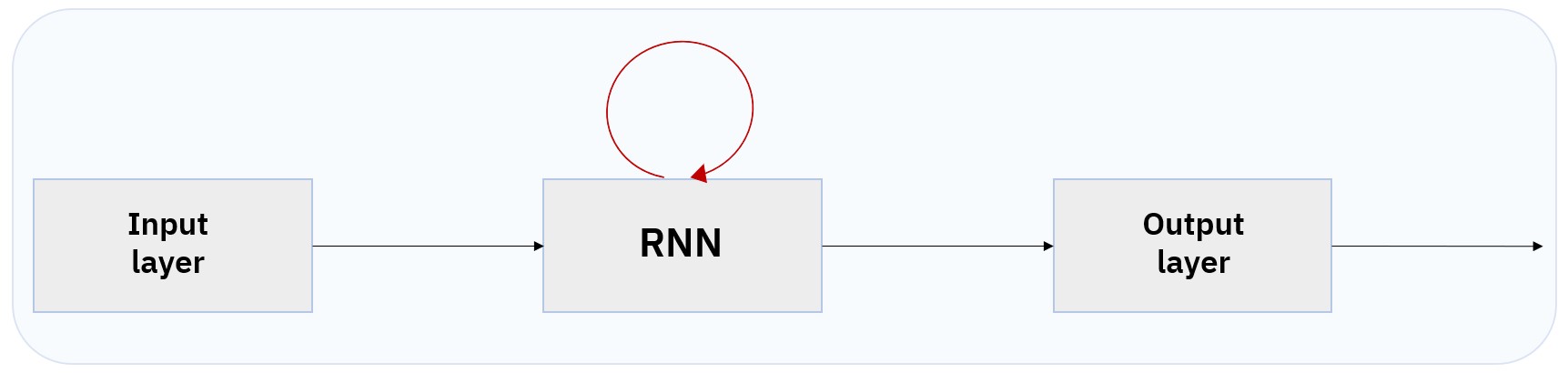
5. 순환신경망 (RNN: Recurrent Neural Networks)
순환신경망(Recurrent Neural Networks; 이하 RNN)은 단방향(Feed Forward) 신경망과 달리 데이터가 닫힌 경로를 따라 순환한다는 특징을 갖는 알고리즘이다. 단방향(Feed Forward) 신경망에서는 신호가 한 층에서 다음 층으로, 한 방향으로 전달된다.
[그림2] 신경망 구조
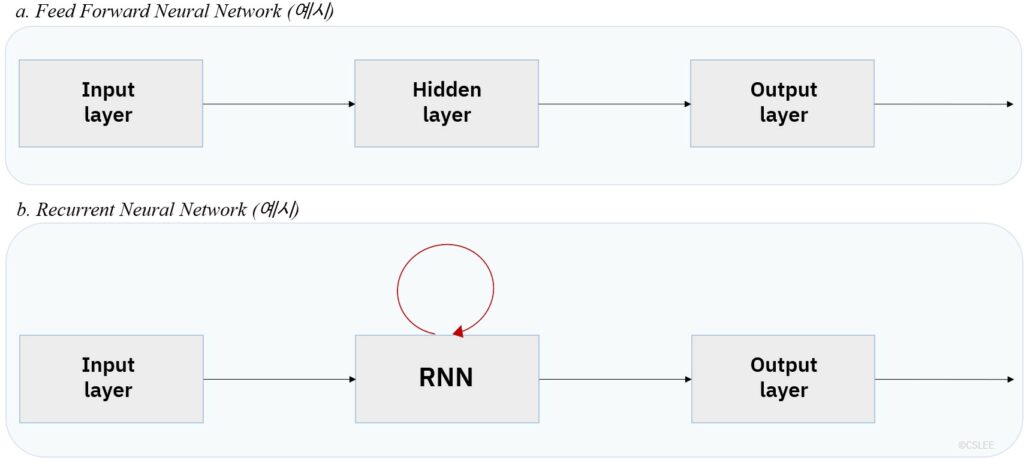
RNN은 순서에 따라 의미가 달라지는 데이터, 순서 정보를 갖고 있는 데이터, 시퀀스 데이터(sequence data)를 처리하기에 적합하다. 문장, 비디오 등이 시퀀스 데이터에 해당한다. 문장은 단어들이 순서를 가지고 나열되어 있으며, 비디오는 이미지들의 순서를 가지고 연결되어 있다. RNN 은 하나의 문장을 단어의 순서적인 조합으로 인식하고, 단어 간 관계와 문맥 정보에 기반한 (context-based) 자연어 처리를 지원한다.
RNN을 이용하여 풀 수 있는 자연어 처리 문제로는 기계 번역(machine translation), 문장이나 문서에 담겨 있는 의견(opinion mining) 또는 감성에 대한 분석(sentiment analysis), 주어진 문맥에서 빈 공간에 들어갈 단어를 예측하는 문제(language model) 등이 있다.
입력층에서 입력 신호를 받는 RNN층을 가정하고 신호가 전달되는 순전파(Forward Propagation) 과정을 순차적으로 전개하면 아래 [그림 3]과 같다. 서로 다른 층이 여러 개 존재하는 것이 아니며, 하나의 RNN 층이 여러 번 사용된다. 그림에서 붉은 선은 RNN층에서 신호가 순환하는 순환(Recurrent) 경로를 나타내고 t는 문장에 존재하는 단어의 개수이다. 역전파 (Backpropagation) 과정에서는 위 흐름이 역순으로 진행된다.
RNN 을 응용한Seq2seq 알고리즘의 경우 인코더(encoder) 역할을 하는 RNN 층과 디코더(decoder) 역할을 하는 RNN 층, 총 2개의 RNN 층을 갖는다. 따라서 아래 그림과 같은 구조의 인코더 RNN 층에서 전달받은 은닉 상태 값을 출력층으로 전달하는 RNN 층이 하나 더 존재한다.
[그림 3] RNN 구조
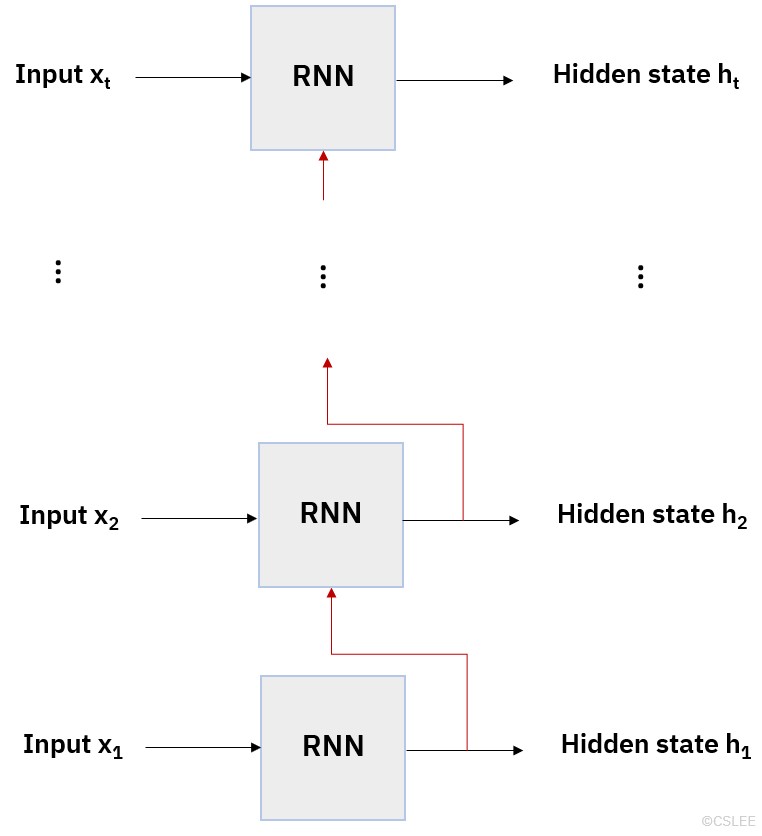
첫번째 순서 (time step)에서는 RNN에 입력층을 통해 전달받은 벡터 값만이 입력되지만, 두번째 순서 (time step) 부터는 RNN에 입력층에서 전달된 벡터x와 그 직전 단계에서 순환 경로를 통해 전달된 은닉 상태 벡터h가 동시에 입력된다. 즉 입력 벡터 x의 길이가 n이고 은닉 상태 벡터 h의 길이가 m이라면 두번째 순서(time step) 부터는 RNN 은닉층의 입력값에 n+m의 노드가 사용된다.
RNN 알고리즘에서 벡터의 길이는 초기 랜덤 값에서 시작하여 기계 학습 과정에서 최적의 값으로 설정된다. 입력층에는 벡터의 차원의 수만큼 입력 노드가 존재한다. RNN층에서의 은닉 노드 수는 사용자가 결정하여 설정한다.
예를 들어 “식사 전에 손을 씻었다.” 는 문장을 학습하는 경우 t=4이고, “식사”, “전에”, “손을”, “씻었다” 라는 단어가 순서대로 입력층에 입력된다. 단어 벡터의 길이가 10이라면 입력 노드의 수는 10개이고, “식사” = (a1, a2, …. a10) 일 때 입력층의 각 노드에 a1, a2, … a10이 입력된다.
사용자가 RNN층의 은닉 노드 개수를 m개로 설정했다면 “식사”라는 단어에 대한 은닉 벡터 h1 값은 h1=(h1.1, h1.2, …. , h1.m) 이다. 이 h1 값은 순환 경로를 따라 다시 RNN 층에 입력된다.
RNN에서 다음 층으로 전달되는 값은 마지막에 도출된 은닉 상태(hidden state) ht 이다. 즉 하나의 고정된 벡터에 입력된 시퀀스 데이터의 문장의 모든 정보가 담겨 전달된다. 이 벡터에는 순차적으로 앞서 입력된 값들의 정보가 포함되지만, 시퀀스 데이터의 길이가 길어질수록 앞서 입력된 정보가 마지막 순서(time step)까지 충분히 전달되지 못하는 장기 의존성 문제(long-term dependency)가 발생한다.
Attention 에서는 RNN 과 달리 입력 시퀀스 전체의 정보를 사용하고 성능을 크게 개선하였다. 인코더와 디코더로 구성된Attention에서는 인코더에서 도출된 모든 은닉 상태 값 (h1, h2, …ht)이 디코더(decoder)로 전달된다. 출력값, 즉 예측하고자 하는 단어와 관련 있는 중요한 단어들에 더 많은 주의(attention)을 기울이고 가중치(weight)를 부여하여 계산한다.
6. 순환신경망 기반 Seq2seq 모델 예제
여기서는 RNN 기반 모델의 하나인 Seq2seq알고리즘을 적용해 언어 간 기계 번역 모델을 구현해보자. 통상적으로 기계 번역은 단어(word) 단위로 번역되는데, 예시는 문자(character) 단위 기계 번역 모델에 해당한다. 단어(word) 단위 번역과 달리 일반적으로 번역 서비스에서 사용하는 방법은 아니며, 단어(word) 단위 기계 번역은 Attention과 Transformer 모델 소개에서 함께 다루도록 한다.
6.1. 환경 셋업 (set-up)
딥러닝 기반 자연어 처리에서 널리 사용하는 플랫폼으로 Tensorflow, Pytorch 등이 있다. 여기서는 Tensorflow 를 사용한다. 신경망 기반 머신 러닝 API로 Keras[13]를 사용한다. Keras는 Python으로 작성된 오픈 소스 라이브러리이다. 이 글에서 언급한 소스 외에도 데이터 처리 환경과 요구 사항 등에 따라 그에 맞는 플랫폼, 라이브러리, API를 다양하게 사용할 수 있다.
| import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers |
6.2. 데이터 저장
대상 텍스트 데이터를 정제(cleansing), 전처리(preprocessing)하고 저장하는 단계에 관한 설명은 생략한다. 텍스트 데이터를 이미 전처리(preprocessing)하여 코퍼스(corpus)를 예컨대 data_path=”language.txt” 로 분석 경로에 저장해 놓은 상태라고 가정한다. 텍스트 데이터를 벡터로 변환(vectorization)하는 과정에 대한 설명도 생략한다.
6.3. 모델 구축 (building)
Seq2seq 모델은 인코더(encoder)와 디코더(decoder)로 구성되며, 각 부분에 RNN 층이 있어 총 2개의 RNN이 사용된다. 여기서는 인코더(encoder) 및 디코더(decoder)의 RNN 알고리즘으로 Keras에서 제공하는 LSTM 라이브러리를 사용하였다. Keras에서는 빌트인 RNN 로 Simple RNN, GRU, LSTM 의 세가지 라이브러리를 제공한다.
먼저 인코더(encoder) 입력층을 정의해 주자.
| encoder_inputs = keras.Input(shape=(None, num_encoder_tokens)) encoder = keras.layers.LSTM(latent_dim, return_state=True) encoder_outputs, state_h, state_c = encoder(encoder_inputs) encoder_states = [state_h, state_c] |
다음으로 디코더(decoder)를 정의한다. 디코더에서 입력 받는 값은 인코더 부분에서 전달된 은닉 상태 값이다.
| decoder_inputs = keras.Input(shape=(None, num_decoder_tokens)) |
디코더(decoder)에도 LSTM 알고리즘을 사용한다. 기계 번역은 분류(classification) 문제이므로, 출력층에서 활성화 함수(Activation function)로 소프트맥스 함수(Softmax function)을 사용한다. 소프트맥스 함수(Softmax function)는 입력 받은 값을 정규화 하여 출력시키는 역할을 한다.
이때 return_sequences=True 는 모든 순서(time step)에서의 은닉 상태 벡터를 반환하도록 하는 구문이다. 이외에 마지막 은닉 상태 벡터만을 반환하게 할 수도 있다.
| decoder_lstm = keras.layers.LSTM(latent_dim, return_sequences=True, return_state=True) decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states) decoder_dense = keras.layers.Dense(num_decoder_tokens, activation=”softmax”) decoder_outputs = decoder_dense(decoder_outputs) model = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs) |
최적화 함수(optimizer)로는 RMSprop을 사용하고, 분류(classification) 문제의 손실(Loss) 함수인 교차 엔트로피 오차 (cross entropy error) 계산을 통해 모델의 정확도(accuracy)를 측정하기로 한다.
| model.compile( optimizer=”rmsprop”, loss=”categorical_crossentropy”, metrics=[“accuracy”]) |
6.4. 구성 (configuration)
사용자는 모델 학습에 앞서서 학습에 사용할 데이터의 배치 사이즈(batch size), 학습할 샘플의 수, 반복할 학습 횟수(epoch), 인코더(encoder) 부분에 함축된 벡터 차원(dimensionality) 등을 적절하게 결정하여 설정해준다.
여기서는 모델 학습에 사용할 데이터의 배치 사이즈(batch size)를 64, 학습할 샘플의 수는 10,000개, 학습 횟수(epoch)는 100번, 인코더(encoder) 부분의 벡터 차원(latent dimensionality)을 256 이라고 설정하였다.
| batch_size = 64 num_samples = 10000 epochs = 100 latent_dim = 256 |
6.5. 모델 학습 (training)
다음으로 위와 같이 설정한 배치 사이즈(batch size)와 학습 횟수(epochs)를 거쳐 모델을 학습시킨다. 학습을 평가하기 위한 테스트 데이터(validation data)는 0.2의 비율로 분리하여 피팅하였다.
| model.fit( [encoder_input_data, decoder_input_data], decoder_target_data, batch_size=batch_size, epochs=epochs, validation_split=0.2,) model.save(“seq2seq”) |
6.6. 모델 구동 (Run)
이제 위와 같이 구축하여 “seq2seq”이라는 이름으로 저장한 모델을 구동 시킨다.
| model = keras.models.load_model(“seq2seq”) encoder_inputs = model.input[0] encoder_outputs, state_h_enc, state_c_enc = model.layers[2].output encoder_states = [state_h_enc, state_c_enc] encoder_model = keras.Model(encoder_inputs, encoder_states) decoder_inputs = model.input[1] decoder_state_input_h = keras.Input(shape=(latent_dim,)) decoder_state_input_c = keras.Input(shape=(latent_dim,)) decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c] decoder_lstm = model.layers[3] decoder_outputs, state_h_dec, state_c_dec = decoder_lstm( decoder_inputs, initial_state=decoder_states_inputs) decoder_states = [state_h_dec, state_c_dec] decoder_dense = model.layers[4] decoder_outputs = decoder_dense(decoder_outputs) decoder_model = keras.Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states) reverse_input_char_index = dict((i, char) for char, i in input_token_index.items()) reverse_target_char_index = dict((i, char) for char, i in target_token_index.items()) def decode_sequence(input_seq): states_value = encoder_model.predict(input_seq) target_seq = np.zeros((1, 1, num_decoder_tokens)) target_seq[0, 0, target_token_index[“\t”]] = 1.0 stop_condition = False decoded_sentence = “” while not stop_condition: output_tokens, h, c = decoder_model.predict([target_seq] + states_value) sampled_token_index = np.argmax(output_tokens[0, -1, :]) sampled_char = reverse_target_char_index[sampled_token_index] decoded_sentence += sampled_char if sampled_char == “\n” or len(decoded_sentence) > max_decoder_seq_length: stop_condition = True target_seq = np.zeros((1, 1, num_decoder_tokens)) target_seq[0, 0, sampled_token_index] = 1.0 states_value = [h, c] return decoded_sentence |
[참고 학습 자료]
– The Stanford Natural Language Processing Group, https://nlp.stanford.edu/
– Stanford University, CS224N: Natural Language Processing with Deep Learning, Winter 2019, Lecture 1-22, https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z
– Kyunghyun Cho, https://sites.google.com/site/deepernn/home/blog/lecturenotebriefintroductiontomachinelearningwithoutdeeplearning
– Kyunghyun Cho, https://github.com/nyu-dl/Intro_to_ML_Lecture_Note
[참고 문헌]
[1] J.R. Firth, A synopsis of linguistic theory 1930-1955, In: Studies in linguistic analysis, Oxford : Blackwell, 1957, 1-32.
[2] David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams, Learning representations by back-propagating errors. Nature 323, 1986, 533–536. https://doi.org/10.1038/323533a0, https://www.nature.com/articles/323533a0
[3] Sepp Hochreiter and Jürgen Schmidhuber, Long Short-Term Memory, Neural Computation 9 (8), 1997, 1735–1780. doi:10.1162/neco.1997.9.8.1735, https://dl.acm.org/doi/10.1162/neco.1997.9.8.1735
[4] Ilya Sutskever, Oriol Vinyals & Quoc V. Le, Sequence to Sequence Learning with Neural Networks, 2014, arXiv:1409.3215, https://arxiv.org/abs/1409.3215 ; Dzmitry Bahdanau, Kyunghyun Cho & Yoshua Bengio, Neural Machine Translation by Jointly Learning to Align and Translate, ICLR, 2015, https://arxiv.org/abs/1409.0473
[5] Kyunghyun Cho et al., On the Properties of Neural Machine Translation: Encoder-Decoder Approaches, 2014, https://arxiv.org/abs/1409.1259 ; Kyunghyun Cho et al., Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014, https://arxiv.org/abs/1406.1078
[6] Ashish Vaswani et al. Attention is all you need, In: Advances in neural information processing systems, 2017, 5998-6008, https://arxiv.org/abs/1706.03762
[7] Alec Radford et al., Improving Language Understanding by Generative Pre-Training, OpenAI, 2018, https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
[8] Alec Radford et al., Language models are unsupervised multitask learners, OpenAI, 2019, https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf ;GPT-2: 1.5B Release, OpenAI. 2019, https://openai.com/blog/gpt-2-1-5b-release/
[9] Jacob Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018, https://arxiv.org/abs/1810.04805v2
[10] Tom B. Brown et al., Language Models are Few-Shot Learners, OpenAI, 2020, https://arxiv.org/abs/2005.14165
[11] 사이토 고키, 밑바닥부터 시작하는 딥러닝, 2017, 한빛미디어 ; Saito Goki, Deep Learning from Scratch, 2016, O’Reilly
[12] 사이토 고키, 밑바닥부터 시작하는 딥러닝 2, 2019, 한빛미디어 ; Saito Goki, Deep Learning from Scratch 2, 2018, O’Reilly
[13] Keras, API references, Recurrent Layers, https://keras.io/api/layers/recurrent_layers/ ; Keras Developer Guides, Working with RNNs, https://keras.io/guides/working_with_rnns/; Keras Team, Guides, https://github.com/keras-team/keras-io/blob/master/guides/
*해당 콘텐츠는 저작권법에 의해 보호받는 저작물입니다.
*해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.