
1. 자연어 처리 (NLP; Natural Language Processing) 란
자연어 처리 (NLP; Natural Language Processing) [1] 분야는 인공지능의 한 분야로서 사람과 사람 간 지식, 의견, 정보 등을 전달하는 소통 수단인 언어를 컴퓨터가 이해할 수 있도록 변환하여 처리하는 분야이다. 자연어 처리 기술을 응용한 대표적인 서비스 사례로 기계 번역(Machine Translation), 챗봇(Chatbot), 문법 자동 수정, 전체 텍스트 검색, 요약(summarization) 서비스 등을 생각할 수 있다. 또는 대량의 텍스트 데이터를 분석하고 이해하는 데에도 자연어 처리가 응용된다. 회사가 고객과의 상담 내용을 텍스트 데이터로 변환한 다음 자연어 처리하여 고객의 만족 및 불만족 사유를 분석하는 것도 한 예시로 볼 수 있다.
자연어 처리에는 텍스트 인식, 음성 인식 등이 포함된다. 음성 인식(speech recognition)의 경우 음성을 기호나 텍스트로 변환하는 작업을 거쳐 이해한다.
2. 자연어 처리 시 유의점
컴퓨터는 자연어를 그대로 이해하는 것이 아니라 단어 또는 문장을 기계가 이해할 수 있는 숫자의 나열인 벡터로 변환(임베딩)[2]한 것을 연산 및 처리한다. 즉 컴퓨터는 말이나 글을 숫자로 구성된 벡터로 바꾸어 이해한다. 임베딩은 언어의 통계적 패턴을 반영하여 벡터에 단어/문장 간 관련도, 의미 및 문법적 정보 등을 함축하는 방법이다. 이때 자연어의 정보를 임베딩에 함축시키는 과정에서 정보 손실을 최소화해야 한다.
자연어 처리 분야는 이미지 분류 분야나 정형 데이터 처리 분야와 다르게, 데이터가 단어 간 순서 및 상호 정보가 반영된 시퀀셜(sequential) 데이터라는 점이 큰 특징이자 장벽으로 작용한다. 그 밖에도 자연어 처리에 있어서 유의해야 하는 데이터의 특징에는 다음과 같은 것이 있다. 먼저, 자연어에는 동음이의어, 다의어, 동형어 등이 존재하여 같은 형태의 단어라도 문맥에 따라 다양한 의미를 전달할 수 있다.
예를 들어, 한국어로 “배에서 배를 많이 먹었더니 배가 부르다”는 말을 영어로 전달하려고 한다고 하자. 이를 각 한국어 지원 기계 번역 서비스로 결과를 도출해 본 결과는 다음 표와 같다.
[표 1] 한국어-영어 번역 결과
| Papago[3] | I’m full because I ate a lot from my stomach. |
| Kakao translator[4] | I ate a lot of boats on the boat and my stomach is full. |
| Bing translator[5] | I ate a lot of pears on the boat, and the boat called. |
| Google Translator[6] | I ate a lot of pears on the boat and I am full. |
결과를 보면, 실제 의미에 맞게 번역된 경우도 있고, 일부의 경우 표현이 누락되거나 다른 표현으로 오역하기도 하였다. 오역의 사례를 보면 단어의 중의적 의미 때문에 해석에 모호성이 생겼음을 알 수 있다.
이 외에도 문장이 단편적이거나 문장 내에 정보가 부족해서 해석에 모호성이 생기기도 한다. 예를 들어 “대신 부탁했다.” 는 문장은 누가 누구에게 무엇을 부탁했다는 것인지에 대한 정보가 누락되어 있어 정확한 번역 결과가 나오지 않는다. 특히 영어와 다르게 한국어는 주어를 생략해도 문법적으로 정상인 문장을 구성할 수 있다. 인간의 소통 과정에서는 주어가 생략되는 경우 문맥 정보를 활용하여 생략된 정보를 메꾸어 이해하지만 기계 번역에서는 문장의 정확한 의미를 파악하기가 어렵다.
나아가, 똑같은 현상에 대해서도 다양하게 표현할 수 있고, 각각의 표현에 미묘한 의미의 차가 존재하는 표현의 다양성에서 기인하는 문제가 있다. 예를 들어 이미지 데이터는 한 픽셀의 RGB 값이 바뀐다고 해도 이미지 전체의 시각적 의미에는 큰 변화가 없는 반면, 단어는 약간의 변화가 문장 전체의 의미를 완전히 다르게 할 수 있다. 같은 단어의 조합인데 어순에 따라 다른 의미를 전달하기도 한다. 이는 자연어 데이터를 정규화 하는 작업을 매우 어렵게 한다.
3. 한국어 자연어 처리의 유의점
언어학적 특성에 따라 고립어로 분류되는 영어, 중국어 등과 다르게 한국어는 교착어에 해당한다. 영어, 중국어 언어 체계는 어순에 따라 단어의 문법적 기능이 영향을 받아서 문장의 의미를 해석할 때 단어의 어순이 중요하게 여겨진다. 그러나 한국어는 어간에 접사가 붙어 단어의 의미와 문법적 기능이 구체화되고, 어순의 중요성이 상대적으로 낮다.
한국어를 자연어 처리할 때는 다음과 같은 한국어의 언어적 특징을 유의해서 처리할 필요가 있다. 첫째, 하나의 어근에 접사가 붙어 다양한 형태의 단어가 파생된다. 이는 한국어의 형태소 분석을 어렵게 하는 원인이 된다.
둘째, 접사에 따라 단어의 역할이 정해지므로 어순은 상대적으로 덜 중요하다. 동일한 의미의 문장을 다양한 어순으로 표현할 수 있고, 어순을 바꾸어도 문법적으로 정상인 문장 사례가 다양하게 존재한다. 예를 들어, “먹으러 가려고 밥을”, “밥을 먹으러 가려고”, “가려고 밥을 먹으러”, 모두 같은 의미의 문장이다.
나아가, 영어는 평서문과 의문문의 어순이 다르므로 문장의 형태로 이를 구분할 수 있다. 중국어의 경우도 의문문에만 사용되는 단어를 통해 평서문과 의문문을 구분할 수 있다. 그러나 한국어는 평서문과 의문문의 문장 형태가 같은 경우가 적지 않고, 물음표 부호가 없으면 이를 구분하기 어렵다. 예를 들어 “점심 먹었어”가 점심을 먹었다는 의미의 평서문인지, 점심을 먹었냐는 의문문인지 물음표가 없다면 알기 어려운 것이다. [7][8]
4. 자연어 처리 관련 개념
4.1. 어휘 분류 사전
단어의 중의성 문제를 개선하기 위해 사용할 수 있는 방법으로 어휘 분류 사전을 활용하는 방법이 있다. 일례로 레스크 알고리즘(Lesk Algorithm)이 있다.[9] 레스크 알고리즘은 Wordnet DB 등 사전(dictionary)을 기반으로 해서 단어를 학습한다. Wordnet DB는 영어 단어에 대해 단어 별로 가능한 의미를 정리하고 이들에 번호를 매겨놓은 DB이다. 동의어 집합 또한 제공한다. 이 데이터를 지도학습(supervised learning) 하여 사용한다. Wordnet은 Python NLTK 모듈에 포함되어 임포트하여 사용할 수 있다.
한국어 단어에 대해서는 KorLex, Korean Wordnet(KWN) 등을 참고할 수 있다.
한편 자연어 처리에 순환 신경망(RNN) 모델, 딥러닝(Deep Learning) 기법 등이 활용되기 시작하면서 단어의 모호성 처리 문제는 많이 개선되고 있다.
4.2. TF-IDF
단어를 벡터로 변환할 때, 단어의 특징을 효과적으로 추출하고 특징 별 수치를 벡터로 표현하는 방법을 ‘특징 벡터’ 표현법이라고 한다. 단어에서 특징을 추출하는 데는 TF-IDF (Term Frequency-Inverse Document Frequency) 값을 이용한다. TF-IDF 값은 출연 빈도를 사용하여 특정 단어가 특정 문서 내에서 얼마나 중요한지를 나타내는 수치이다. 이 값이 높을수록 해당 단어는 해당 문서를 잘 대표하는 특징적인 성질을 띤다고 해석할 수 있다. TF-IDF는 TF값과 IDF값을 곱한 값이다. TF는 단어가 문서 내에 출연한 빈도를 계산한다. IDF는 특정 단어가 출연한 문서의 수를 계산하여 대다수의 문서에서 자주 출연하는 부사나 정관사와 같은 단어에 대해 역수를 취하여 페널티를 부여한다.
5. 자연어 처리 방법
자연어 처리 임베딩 방법은 단어 수준 임베딩과 문장 수준 임베딩으로 구분된다.
5.1. 단어 수준 임베딩; 문맥 독립 임베딩
Word2vec, GloVe, FastText 등은 단어 수준 처리 방법에 해당한다. 단어 수준 임베딩은 벡터에 단어의 문맥적 의미를 함축한다. 하지만 단어의 형태가 같을 경우 동음이의어를 분간하기 어렵고, 언어의 모호성이나 유의성을 처리하기 어려운 한계가 있었다. 이와 같은 같은 모델을 문맥을 고려하지 않는 문맥 독립(context-free) 임베딩 모델이라고도 한다.
형태소를 음절로 분할하여 키워드의 빈도를 도출하는 과제 등은 단어 수준 임베딩에서 할 수 있는 자연어 처리 과제의 일례이다.
5.1.1. Word2vec
Word2vec[10]은 Mikolov 등이 2013년 논문에서 제안한 임베딩 방법으로, 함께 쓰이는 단어들이 유사할수록 비슷한 벡터 값을 갖을 것이라고 가정하였다. 특정 단어를 기준으로 주변 단어들을 사용하여 단어를 임베딩 한다. 구체적인 임베딩 방법은 크게 CBOW(Continuous Bag of Words)와 Skip-gram 두가지 방식이 있다. CBOW 방법은 주변에 나타나는 단어를 벡터로 입력 받아 해당 단어를 예측한다. Skip-gram은 대상 단어를 벡터로 입력 받아 주변에 나타나는 단어를 예측하는 네트워크를 구성하여 단어 임베딩 벡터를 학습한다. 이 가운데 Skip-gram이 좀 더 널리 쓰이고 있다.
[그림 1] Skip-gram 알고리즘
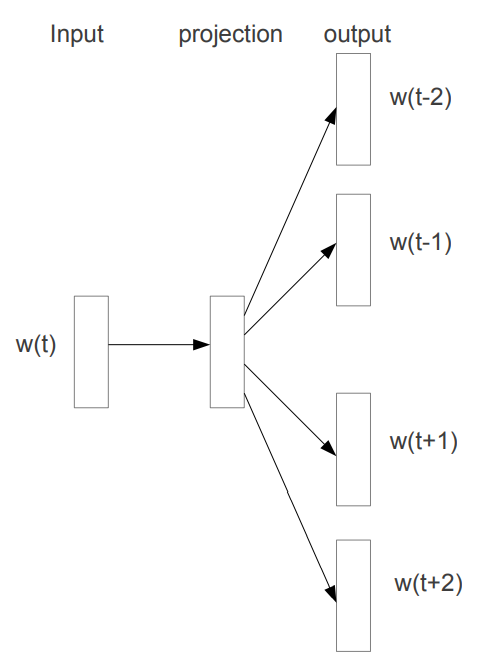
5.1.2. GloVe
또다른 단어 수준 임베딩 방법에는 GloVe (Global Vectors for Word Representation)[11]가 있다. GloVe는 코퍼스(corpus) 문서에서 특정 단어와 함께 사용된 단어의 사용 또는 출현 빈도를 회귀 방법을 통해 예측한다.
Word2vec의 skip-gram과의 차이점은, skip-gram은 코퍼스(corpus) 문서 내에서 주변 단어를 예측하는 반면, GloVe는 코퍼스(corpus) 문서에서 각 단어마다 동시 출현 빈도를 분석하고 빈도 행렬을 생성한다. 그리고 이 행렬을 활용하여 동시 출현 빈도를 예측한다. 이러한 방법으로 GloVe는 대상 단어와 주변 단어에 대한 학습 과정을 반복하는 skip-gram보다 학습 속도가 빠르다.
5.2. 문장 수준 임베딩; 문맥 기반 임베딩
한편 단어 수준 임베딩은 순서 정보를 담고 있는 시퀀스 데이터를 다루기에 적합하지 않았다. 자연어는 단어/문장의 순서 및 단어/문장 간 상호 정보를 고려해야 하는 시퀀스 데이터이므로 순서 정보를 사용하는 시퀀셜 모델링(sequential modelling) 이 고안되었다. 이는 문장 수준 임베딩, 문맥 기반(context-based) 임베딩 모델이라고도 불린다.
문장 수준 임베딩 기법을 통해 단어의 시퀀스 정보를 함축하고, 동음이의어를 문맥에 따라 분리하는 것이 좀더 용이해지고 자연어 처리의 성능이 더욱 향상되었다. 문장 수준 임베딩 방법으로 처리할 수 있는 과제의 일례로는 기계 번역, 감성 분석(sentiment analysis) 등이 있다.
5.2.1. 순환 신경망 (RNN; Recurrent Neural Network)
대표적으로 순환 신경망 (RNN) 아키텍쳐가 시퀀셜 모델링에 활용된다.
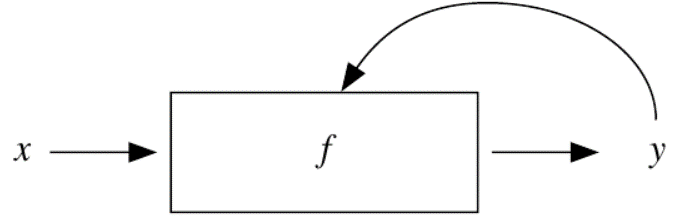
기존 신경망(NN; Neural Network)과 순환 신경망(RNN; Recurrent Neural Network)의 차이는 다음과 같다. 기존 신경망 구조는 정해진 입력 X를 받아 Y를 출력하는 구조였다.
[그림 2] 기존 신경망 아키텍처

하지만 RNN은 입력 X와 직전의 은닉상태(hidden state)를 참조하여 현재의 상태를 결정하는 작업을 재귀적으로 여러 time-step에 걸쳐 수행한다. RNN은 기존 신경망과 달리 이전 time-step의 자기 자신을 참조하여 현재의 상태를 결정하기 때문에 각 단계마다 네트워크 가중치 파라미터가 공유되었다. 각 time-step별 은닉상태는 출력 값이 될 수 있다. RNN을 하나의 은닉층이라고 보고 RNN 층이 사용된 모형을 RNN 모형이라고 하기도 한다.
[그림 3] RNN 아키텍처
RNN 기반 모형에는 seq2seq[12] 이 있다. seq2seq는 인코더-디코더(-생성자) 구조를 하고 있으며, 앞서 배치된 RNN이 인코더 역할을 하고, 그 다음 RNN이 디코더 역할을 한다.
[그림 4] Seq2seq 알고리즘
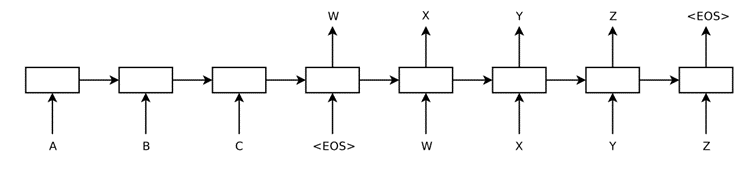
** ABC는 입력된 문장이고, WXYZ는 출력된 문장이다.
그러나 RNN 방식은 time-step이 길어지면 기울기 소실 등의 문제가 잘 발생하고, 은닉 상태를 통해 과거의 정보를 저장할 때 문장의 길이가 길어지면 앞의 과거 정보가 마지막 시점까지 전달되지 못하는 문제가 있었다. 이러한 문제를 장기 의존성 문제(long-term dependency)라고도 부른다. 이에 RNN은 긴 시퀀스 데이터를 효과적으로 처리하지 못하는 한계가 있었다.
5.2.2. LSTM (Long Short-Term Memory)
장기 의존성 문제에 대처하기 위해 기존 RNN 모형을 일부 수정한 LSTM[13]이 고안되었다. LSTM은 은닉상태 외에 셀 스테이트(cell state)라는 변수를 추가로 이용했다. 그리고 여러 게이트를 열고 닫아 정보의 흐름을 조절하여 데이터를 더 오래 기억하고 더 긴 길이의 데이터도 좀 더 효과적으로 처리할 수 있게 하였다.
그러나 파라미터가 많아진 만큼 LSTM의 구조는 더 복잡해졌고, 훈련시간이 증가했다. 그리고 LSTM도 문장의 길이가 길어질수록 장기 의존성 문제(long-term dependency)가 나타나는 한계를 여전히 가지고 있었다.
LSTM과 유사한 구조의 모델로 GRU(Gated Recurrent Unit)이 있다.
5.2.3. Transformer
RNN, LSTM, GRU 네트워크의 장기 의존성 문제를 극복하기 위해 Transformer[14]라는 딥러닝 아키텍처가 고안되었다. Transformer는 현재 자연어 처리 과제에서 가장 최신 기술로서 사용된다. Transformer가 등장한 뒤로 자연어 처리 분야에서 응용되던 RNN, LSTM 네트워크 등은 Transformer로 빠르게 대체되었다. Transformer 네트워크를 적용한 자연어 처리 모델에는 최근 자연어 처리 성능을 크게 향상시킨 BERT(Bidirectional Encoder Representations from Transformers)[15], GPT (Generative Pre-trained Transformer), T5 등이 포함된다.
Transformer는 2017년 Google에서 제안한 Attention 기반의 인코더-디코더 모형 알고리즘이다. RNN 네트워크에서 사용한 순환 방식을 사용하지 않고 Attention방법을 사용한다.
Attention은 RNN 기반 모델이 갖는 장기 의존성 문제을 보완하기 위해 고안되었다. RNN기반 모델, seq2seq의 주요한 문제점은 입력된 시퀀스 데이터에 대해 마지막 은닉상태(hidden state)만을 디코더에 전달한다는 점이었다. 이 때문에 입력된 모든 단어의 정보가 디코더에 제대로 전달되지 못하고, 입력된 단어가 많을수록 앞쪽에서 입력된 단어는 거의 전달이 되지 않았다.[16]
하지만 Attention 기법은 각 단어에 대한 은닉상태 정보를 모두 디코더로 전달한다. 이전 단어들의 정보를 기반으로 다음 단어를 예측하는데, 예측하고자 하는 단어와 관련이 높은 단어에 더 많은 주의(attention)를 기울여 가중치를 부여한다고 하여 Attention 기법이라는 이름이 붙게 되었다.
Transformer모델은 N개의 인코더가 쌓인 형태를 한다. 가장 마지막에 있는 인코더의 결과값이 디코더에 전달된다. Attention 기법을 소개한 Vaswani et al. 2017 논문에서 인코더는 N=6개였지만, N은 다양한 값으로 지정할 수 있다.
[그림 5] Attention 기반 Transformer의 인코더-디코더 구조
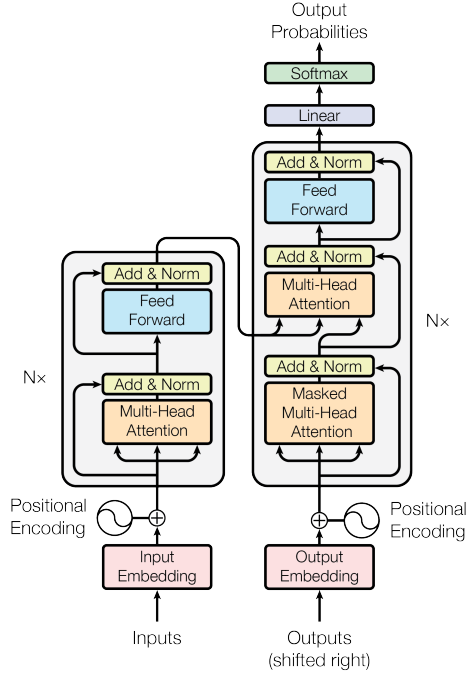
[참고 학습 자료]
– The Stanford Natural Language Processing Group, https://nlp.stanford.edu/
– Stanford University, CS224N: Natural Language Processing with Deep Learning, Winter 2019, Lecture 1-22, on Youtube, https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z
– Kyunghyun Cho, https://sites.google.com/site/deepernn/home/blog/lecturenotebriefintroductiontomachinelearningwithoutdeeplearning
– Kyunghyun Cho, https://github.com/nyu-dl/Intro_to_ML_Lecture_Note
[참고 문헌]
[1] Thomas Erl, Wajid Khattak and Paul Buhler 공저, 조성준 외 역, 빅데이터 기초: 개념, 동인, 기법, 시그마프레스, 2017, 201-202.
[2] Yoshua Bengio, Réjean Ducharme, Pascal Vincent and Christian Jauvin, A Neural Probabilistic Language Model, 2003, https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
[4] https://translate.kakao.com/
[7] 김기현, 김기현의 자연어처리 딥러닝 캠프: 파이토치 편, 한빛미디어, 2019
[8]이기창 저, NAVER Chatbot Model 감수, 한국어 임베딩: 자연어 처리 모델의 성능을 높이는 핵심 비결, 에이콘출판, 2019
[9] M. Lesk, Automatic sense disambiguation using machine readable dictionaries: how to tell a pine cone from an ice cream cone. In SIGDOC ’86: Proceedings of the 5th annual international conference on Systems documentation, 1986, 24-26,http://portal.acm.org/citation.cfm?id=318728&dl=GUIDE,ACM&coll=GUIDE&CFID=103485667&CFTOKEN=64768709
; Satanjeev Banerjee and Ted Pedersen, An Adapted Lesk Algorithm for Word Sense Disambiguation Using WordNet, Lecture Notes in Computer Science, 2002, Vol. 2276, 136 – 145, https://www.cs.cmu.edu/~banerjee/Publications/cicling2002.ps.gz
[10] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado and Jeffrey Dean, Distributed Representations of Words and Phrases and their Compositionality, 2013, https://arxiv.org/abs/1310.4546
[11] J. Pennington, R. Socher and C. Manning, GloVe: Global Vectors for Word Representation, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, 1532-1543, https://doi.org/10.3115/v1/D14-1162
[12] Ilya Sutskever, Oriol Vinyals and Quoc V. Le, Sequence to Sequence Learning with Neural Networks, 2014, https://arxiv.org/abs/1409.3215; D. Bahdanau, K. Cho and Y. Bengio, Neural Machine Translation by Jointly Learning to Align and Translate, ICLR, 2015, https://arxiv.org/abs/1409.0473
[13] Sepp Hochreiter and Jürgen Schmidhuber, Long Short-Term Memory, Neural Computation 9 (8): 1735–1780, doi:10.1162/neco.1997.9.8.1735, https://direct.mit.edu/neco/article-abstract/9/8/1735/6109/Long-Short-Term-Memory?redirectedFrom=fulltext
[14] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, Attention is all you need, Advances in neural information processing systems, 2017, 5998-6008, https://arxiv.org/abs/1706.03762
[15] Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018, https://arxiv.org/abs/1810.04805
[16] Sudharsan Ravichandiran, 전희원 외 옮김, 구글 BERT의 정석 – 인공지능, 자연어 처리를 위한 BERT의 모든 것(Getting Started with Google Bert), 한빛미디어, 2021
*해당 콘텐츠는 저작권법에 의해 보호받는 저작물입니다.
*해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.