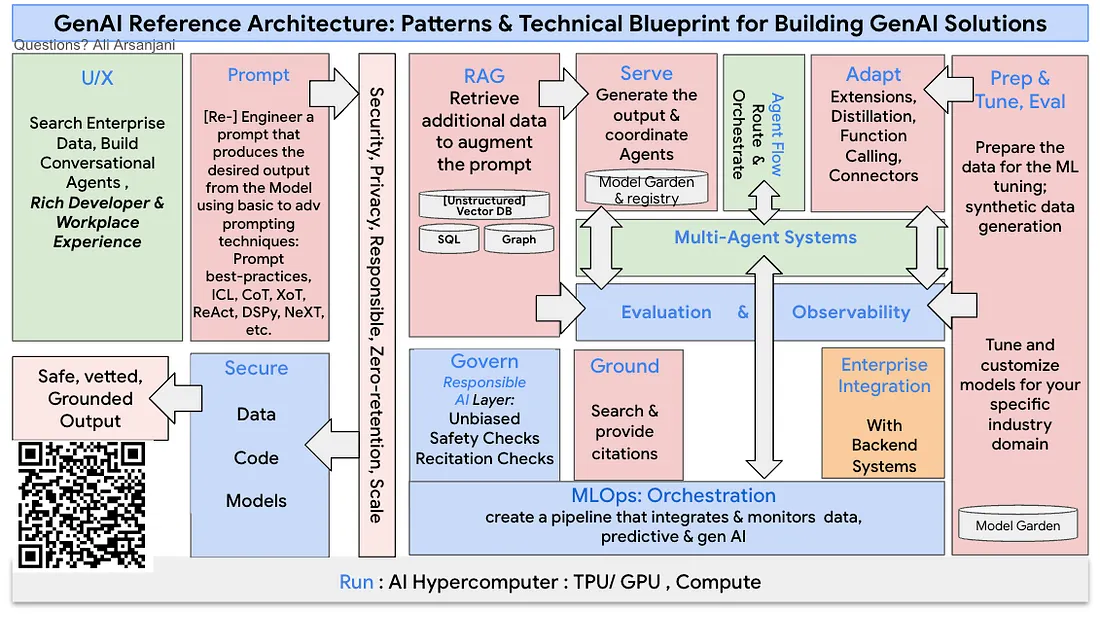
생성형 인공지능(이하 생성형 AI)은 최근 문장, 이미지 등의 다양한 컨텐츠를 자동으로 만들어 낼 수 있는 기술로 주목받고 있다. 챗봇, 디자인, 코딩 등에서 광범위하게 활용되며 일상과 산업 전반에 빠르게 확산되고 있다. 본고에서는 이러한 생성형 AI의 활용을 위해서 집이나 회사에서 거대언어모델(이하 LLM)에 대해서 빠르고 쉽게 아키텍처를 구현할 수 방법에 대해 설명하고자 한다. 아키텍처 구현절차를 간단하게 살펴보고 직접 생성형AI를 구현해보도록 하겠다.
1. 생성형 AI 아키텍처 구현절차
생성형 AI 아키텍처는 목적과 구현 방식에 따라 다양하지만 일반적으로 아래와 같은 절차로 이루어 진다. 모니터링, 로깅, 배포 절차 등 운영 시에 요구되는 절차는 제외하였다.
1). 요구사항 정의
용도에 대해서 정확하게 설정한다. 응답속도, 사용자 수, 품질 등에 따라 요구되는 H/W, 애플리케이션의 수준이 달라지게 된다.
2). 인프라 구축
생성형 AI의 인프라의 구축 방법에는 클라우드를 이용하는 방법과 온프레미스(로컬 서버) 로 직접 구축하는 방법이 있다. 사용 용도와 예산 등 요구사항에 따라 선택하도록 한다. 대표적인 클라우드 플랫폼으로는 AWS SageMaker, Azure Machine Learning, Google Vertex AI Platform 등이 있다. 클라우드를 이용하면 별도의 하드웨어 없이 빠르게 구축할 수 있으나 장기적으로 활용 시에는 비용부담이 크다. 공공, 금융 등의 망분리 환경이나 보안이 중요시되는 사용 환경에서는 자체 서버에 모델을 구축하는 방식을 추천한다. 사용자 수가 100명 이내라면 RTX 4090 24GB 정도의 그래픽카드 2장으로도 충분히 서비스가 가능하다. GPU 카드는 CUDA (엔비디아 소프트웨어 스택) 환경을 지원할 경우 자체적으로 구축하기에 용이하다. OpenML이나 OpenCL을 지원하는 GPU 카드도 구축이 가능하나 지원하지 않는 도구들이 많으므로 되도록이면 CUDA가 지원되는지 확인하도록 한다. AI 모델 중에서 파라미터가 적은 경우 일반 CPU로도 수행이 가능하므로 테스트 용도로 시도해볼 수 있다.
3). 모델 선택
오픈 모델을 그대로 사용할 지 미세조정(Fine Tuning)을 수행할 지 결정한다. 처음부터 생성형 AI를 학습시켜 모델을 생성하기에는 천문학적인 비용이 요구되므로 이미 만들어진 모델을 이용하는 것이 효율적이다. 무료로 사용할 수 있는 공개된 모델들이 많이 있으므로 이를 활용하자.
| 모델명 | 개발사 | 파라미터 크기 | 특징 |
|---|---|---|---|
| LlaMA4 | 메타 | 17B | 멀티모달 |
| Gemma3 | 구글 | 1B, 4B, 12B, 27B | 다국어 지원 |
| Qwen3 | 알리바바 | 32B, 235B | 하이브리드 추론 |
| DeepSeek-R1 | DeepSeek | 7B, 14B, 70B 등 | 추론기반 응답 |
[표1] 주요 오픈소스 LLM 목록
4). AI 서비스 인터페이스 구성
모델을 사용자와 연결하는 API 서버를 구성한다. 이때 캐싱, 스트리밍, 비동기 처리 등을 고려한다. 이러한 역할을 하는 도구들 역시 오픈소스로 제공되고 있으며 구축하고자 하는 요구사항과 상황에 맞게 선택하도록 한다.
| 도구명 | Github 주소 | 특징 |
|---|---|---|
| Ollama | https://github.com/ollama | 모델관리, 오프라인모드 가능 |
| Ramalama | https://github.com/containers/ramalama | 컨테이너 실행 |
| Vllm | https://github.com/vllm-project | 고속 추론 라이브러리 |
[표2] 주요 AI 서비스 인터페이스 도구 목록
5). 응용 계층 구현
사용자 인터페이스(UI)를 연동한다. 사용자 관리, 인증 등의 구성도 포함되어야 한다. 주로 웹 환경에서 제공되는 오픈소스 UI 들이 존재하며 대부분 ChatGPT API 호출을 지원한다.
| 이름 | 홈페이지 주소 | 특징 |
|---|---|---|
| Open WebUI | https://openwebui.com | Ollama 기반 |
| Hugging ChatUI | https://huggingface.co | Hugging Face 기반 |
| AnithingLLM | https://anythingllm.com | 지식베이스와 LLM 결합 |
[표3] 주요 오픈소스 LLM UI
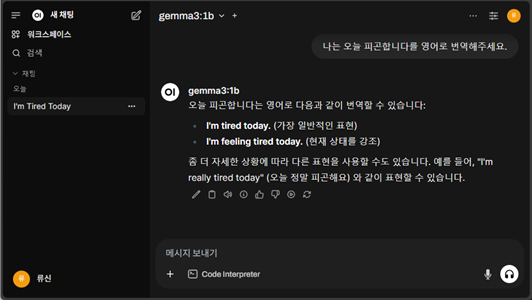
2. 생성형 AI 아키텍처 구현
쉽게 접근하기 위하여 클라우드가 아닌 온프레미스 구축으로 가정하고 리눅스 컨테이너 환경을 기반으로 설명한다. Ollama를 이용하여 AI 서비스 레이어를 만들고 Open WebUI를 이용하여 사용자 인터페이스를 구현한다. AI 모델은 별도의 학습 없이 한글 표현이 잘되는 Gemma3를 이용하겠다. 리눅스는 가장 널리 쓰이는 RHEL을 기준으로 한다. 컨테이너 명령어는 podman으로 진행하나 docker로 바꾸어도 무방하다.
1). 사전 준비
- AI 서버
오픈 모델중에서 1B 파라미터는 일반 CPU만을 이용해서도 느리지만 테스트를 해볼 수 있다. 다만, 서버의 메모리는 16GB이상을 추천한다. Windows 환경에서도 구현이 가능하지만 컨테이너 환경에서 매우 쉽게 구축이 가능하므로 리눅스 환경에서 진행하도록 한다. Windows 밖에 없다면 WSL2를 이용해도 된다. GPU가 있는 환경이라면 GPU 메모리 용량에 따라서 적절한 AI 모델의 파라미터 수를 선택하도록 한다. 만일 서버의 메모리가 충분하고 GPU 메모리가 24GB 이상이라면 Gemma3의 27B 도 실행이 가능하다. - 생성형 AI 모델 선정
요구사항에 맞는 모델을 선정한다. Ollama에서는 AI 모델을 마치 컨테이너처럼 관리할 수 있으므로 인터넷이 되는 환경이라면 쉽게 여러 모델을 바로 테스트해 볼 수 있다. 모델의 파라미터 수가 많을수록, 최근에 업데이트된 모델일수록 더 빠르고 품질이 좋은 모델일 가능성이 높다. - 컨테이너 환경
Docker 나 Podman 등의 컨테이너 환경이 필요하므로 관련 리눅스 패키지를 설치하도록 한다.
sudo dnf install -y podman2). Ollama 설치
생성형AI 모델의 관리와 API 제공을 위해서 Ollama를 서버에 설치한다.
curl -fsSL https://ollama.com/install.sh | sh설치가 완료되었다면 아래의 명령으로 Ollama 서비스를 실행할 수 있다.
ollama serve만일, Ollama도 컨테이너 환경으로 설치한다면 아래와 같이 수행한다. -v 옵션에서 ollama는 적절한 저장소 위치로 지정해준다. -p 옵션에서 ollama를 서비스할 포트도 변경해줄 수 있다.
podman run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaOllama의 기본 서비스 포트는 11434이다. 환경변수를 설정하여 서비스 포트를 변경해줄 수 있다. 별도의 서버와 연동하는 경우 127.0.0.1이 아닌 0.0.0.0과 같이 인터페이스 IP를 변경해주도록 한다.
export OLLAMA_HOST=0.0.0.0:114343). LLM 모델 설치
생성형AI 모델을 설치한다. 아래는 Gemma3:1B를 모델을 설치하는 예제이다. 설치가 가능한 모델 목록은 https://ollama.com/search 위치에서 검색해볼 수 있다. 컨테이너 환경에 Ollama를 설치했다면 컨테이너 내부에서 명령을 수행하도록 한다.
ollama pull gemma3:1b명령행에서 모델을 가져오고 직접 테스트를 해볼 수도 있다.
ollama run gemma3:1b4). Open WebUI 설치
사용자 인터페이스를 위해서 Open WebUI를 설치한다. RAG와 여러 플러그인을 지원하므로 손쉽게 기능을 확장할 수 있으며, 아래의 명령으로 간단하게 설치 및 실행이 가능하다. -p 옵션에서 실제 서비스할 포트를 지정해준다. 여기에서는 3000번으로 지정하였다. 환경변수 옵션으로 지정된 OLLAMA_BASE_URL은 이전 Ollama 설치 시에 환경변수를 별도로 지정하였다면 그에 맞게 변경한다. -v 옵션은 로컬 볼륨을 지정하는 옵션으로 open-webui 볼륨명 대신 특정 디렉터리를 절대경로로 지정할 수 있다.
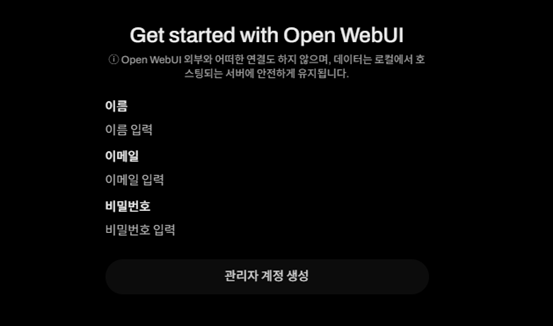
podman run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainOpen WebUI 설치를 마지막으로 LLM 모델을 실행해볼 수 있는 환경이 구축되었다. 별도의 PC 웹브라우저에서 해당 서버 주소 및 포트(http://서버주소:3000)로 접속을 해서 정상적으로 접속되는지 확인해보자. 성공한다면 Get started 화면이 나오게 되며, 해당 문구를 클릭할 경우 관리자를 생성하는 화면이 표출된다. 이름과 이메일, 비밀번호를 입력하게 되면 다음 접속부터는 로그인 화면만 표시되게 된다. 이 정보로 로그인하게 되면 관리자 권한을 가지므로 Open WebUI의 모든 설정을 변경할 수 있다.

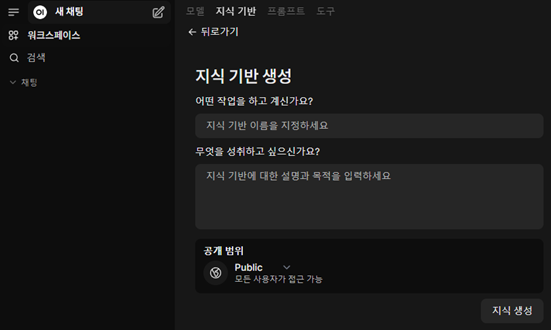
로그인 후에는 ChatGPT와 유사하게 Ollama에서 설치된 모델을 수행해볼 수 있다. 우측상단의 동그란 아이콘을 클릭하여 관리자 패널로 들어갈 수 있으며, 사용자 및 평가, 함수, 설정 등의 메뉴가 표시된다. 사용자는 수동으로 추가해줄 수 있으며, 설정 일반 탭에서 새 회원가입 활성화를 클릭하여 개별로 신청을 받을 수도 있다. 설정 모델 탭에서 Ollama에 설치되어 있는 모델에 대해 상세 설정을 해줄 수 있다. 모델의 표시되는 이름과 시스템 프롬프트 등을 여기에서 설정한다. 그리고 지식기반 설정을 이용하여 간단하게 RAG를 구현할 수 있다. 이 항목에서 설정하는 지식기반은 좌측 워크스페이스의 지식기반에서 생성할 수 있다. 생성된 지식기반에 여러 파일이나 디렉터리를 설정하여 모델에서 답변 생성 시에 해당 내용을 참조하도록 할 수 있다.
5). 인터넷 사용이 불가능한 환경에서의 고려사항
공공, 금융 등의 망분리 환경에서 아키텍처를 구현하기 위해서는 별도로 인터넷 환경에서 컨테이너 이미지를 저장하고, 내부망으로 반입 후에 컨테이너에 불러온다. 아래의 명령으로 쉽게 이미지를 tar 파일로 저장할 수 있다.
| podman save -o open-webui.tar ghcr.io/open-webui/open-webui:main |
내부망에서 불러올 때는 load 명령으로 컨테이너로 tar 이미지를 불러올 수 있다.
| podman load -i open-webui.tar |
AI모델 역시 인터넷 환경에서 내려 받은 후에 내부망으로 반입하여야 한다. Ollama에서 내려받은 모델은 $HOME/.ollama/models 위치에 존재하므로 동일위치로 복사하면 된다. 복사한 후 ollama list 명령을 수행하여 설치 여부를 확인한다.
3. 마치며
별도의 AI 관련 지식 없이 쉽게 생성형AI 아키텍처를 구현할 수 있는 방법을 간단하게 살펴보았다. 별도의 큰 비용을 지출하지 않고서도 ChatGPT와 유사한 환경을 구축할 수 있으며 이를 활용하여 업무용 챗봇이나 코딩 보조업무로 활용할 수 있다. 나만의 생성형 AI를 구축하고 여러가지 프로젝트에 활용해보자.