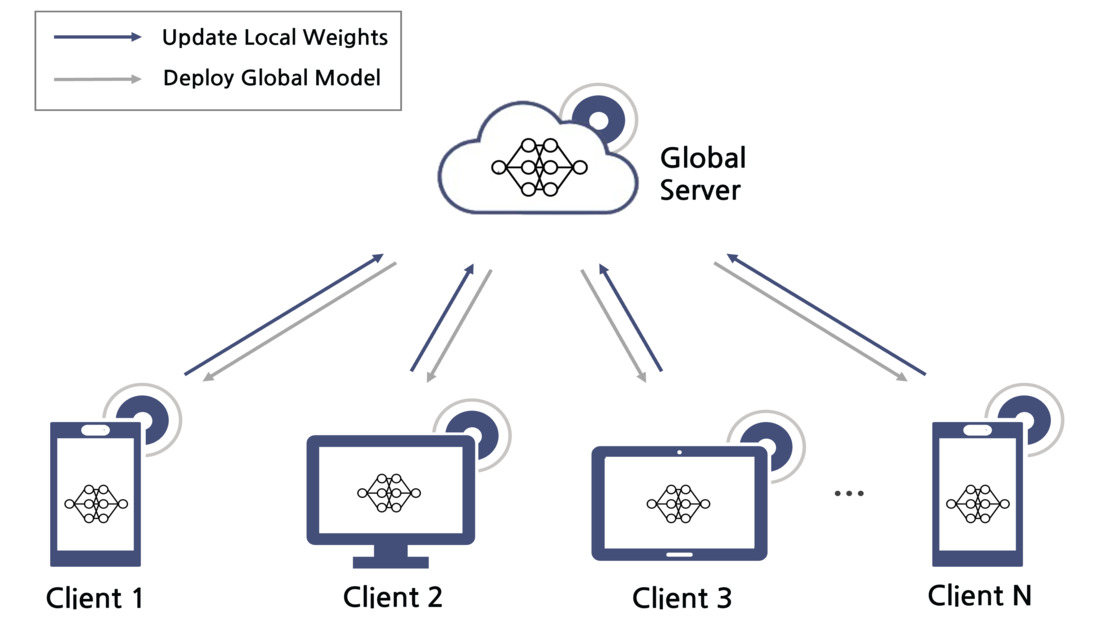
Intro
연합학습(Federated Learning)은 AI 시대에 데이터 보안과 데이터 분산 처리의 혁신적인 접근법으로 주목받고 있습니다. 이 접근법은 중앙 서버에 데이터를 저장하지 않고, 분산된 기기에서 보유한 데이터로 직접 학습을 수행한 후 연합하는 방법으로, 데이터의 프라이버시를 유지하면서도 효율적인 모델 학습을 가능하게 합니다. 이는 특히 개인정보 보호가 중요한 스마트폰, IoT 기기, 헬스케어 분야에서 각광받고 있습니다. 본 글에서는 연합학습의 개념과 작동 원리를 소개하고, 이 기술이 AI 시대의 데이터 보안과 분산 처리에 어떤 변화를 가져오는지 살펴보겠습니다.
▶AI 시대 문제점
AI 학습은 오늘날 다양한 분야에서 혁신을 이끌고 있지만, 그 과정에서 여러 가지 문제에 직면하고 있습니다. 대표적으로 세 가지 주요 문제점이 있습니다.
1) 대용량 데이터 처리를 위한 높은 컴퓨팅 리소스 비용
2) 개인정보보호와 프라이버시 문제
3) 개인 맞춤형 인공지능 서비스의 필요성
끊임없이 증가하는 데이터 양과 복잡한 모델을 처리하기 위해 고성능의 프로세서와 대용량 스토리지 등 막대한 컴퓨팅 자원이 필요하고, 이는 경제적 부담을 동반합니다. 또한 AI 학습을 위해 수집되는 데이터에는 종종 민감한 정보나 개인정보를 포함할 수 있고, 이로 인해 데이터 유출 및 악용의 위험이 높아지며 사용자의 프라이버시를 보호하는 것이 중요한 과제로 떠오르고 있습니다. 사용자 개개인의 요구와 선호에 맞춘 맞춤형 AI 서비스 제공이 점점 더 중요해지고 있습니다. 그러나 이를 실현하기 위해서는 개인 데이터의 수집과 분석이 필요하여, 앞서 언급한 프라이버시 문제와 맞물리게 됩니다. 이러한 문제들을 해결하기 위해 등장한 것이 연합학습(Federated Learning)입니다.
▶연합학습이란?
연합학습은 분산된 기기에서 직접 학습을 수행하는 분산 학습 방법입니다. 이 접근법은 데이터가 저장된 기기에서 직접 모델을 학습시키고, 각 기기에서 학습된 결과 데이터(가중치)만을 중앙 서버로 전송하여 글로벌 모델을 업데이트합니다. 이를 통해 데이터 전송 비용을 줄이고, 데이터 보안과 프라이버시를 강화할 수 있습니다. 연합학습은 특히 민감한 데이터를 다루는 경우에 유용하며, 데이터 유출의 위험 또한 줄일 수 있습니다.
▶기존 학습 방법과의 차이점
기존의 AI 학습과 모델 실행 방식에서는 사용자의 기기에서 데이터를 중앙 서버로 전달하여 처리하는 것이 일반적입니다. Figure 1은 기존 방식과 연합 학습 방식을 비교한 그림입니다. 기존 많이 사용되는 방식에서는 왼쪽 그림과 같이 중앙 서버에서 수집한 사용자의 데이터로 AI 모델을 학습시킨 후, 사용자가 API 호출을 통해 학습된 모델을 서버에서 직접 사용합니다. 이 과정에서 데이터 감청, 탈취, 무단 변조 등의 보안 위험이 존재하며, 특히 민감한 정보를 외부로 전송할 경우 개인 프라이버시 문제나 기업의 정보 유출 등 보안적 측면에서의 문제가 발생할 수 있습니다.
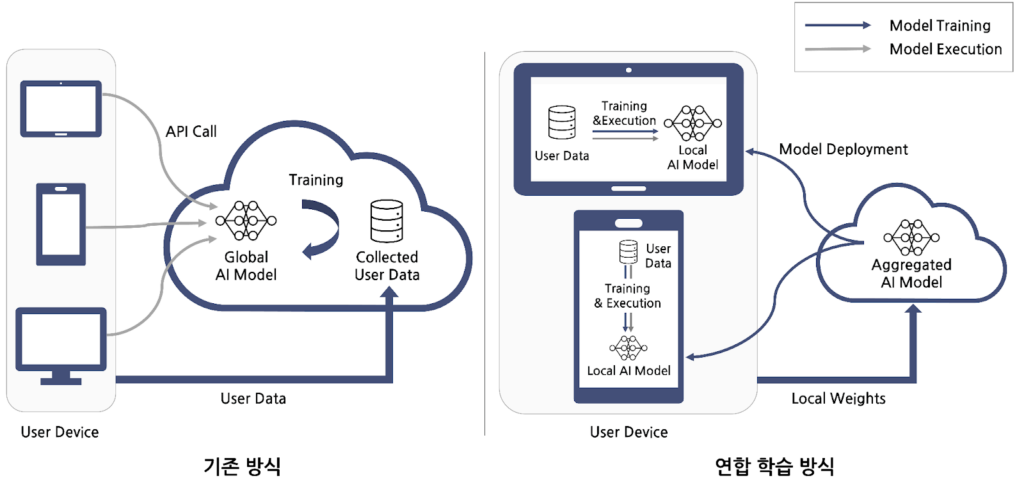
Figure 1. AI 학습과 모델 실행에서의 기존 방식과 연합 학습 방식 비교
이러한 문제점을 보완하기 위해 오른쪽 그림과 같은 연합 학습 방안이 등장했습니다. 연합 학습에서는 로컬 기기 내에서 데이터가 수집되고, 수집된 데이터를 이용해서 로컬 기기가 직접 AI 모델을 학습합니다. 각 기기에서 학습된 모델 업데이트만 중앙 서버로 전송해서 글로벌 모델을 업데이트합니다. 업데이트된 글로벌 모델이 다시 사용자의 기기로 배포되면 사용자는 기기 내에서 모델을 실행할 수 있습니다. 이를 통해 민감한 데이터를 중앙 서버로 전송하지 않고도 AI 모델의 학습과 실행을 수행함으로써 보안 위험을 줄이고, 데이터 전송량과 네트워크 트래픽을 줄이며 저장 공간 비용을 절감할 수 있습니다.
또한 네트워크 연결이 없거나 제한적인 환경에서도 실시간으로 작동할 수 있고, 사용자의 데이터를 직접적으로 학습하기 때문에 개인의 데이터 패턴에 따라 모델을 지속적으로 업데이트 하여 더욱 개인화된 결과를 제공할 수 있습니다.
▶연합학습 구조
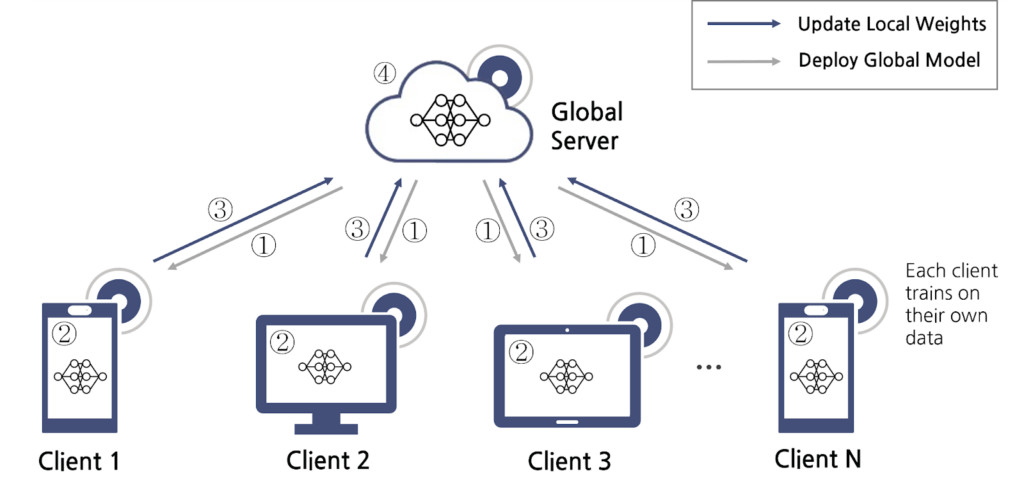
Figure2. 연합학습 프레임워크
① 서버가 글로벌 모델(Global Model)을 클라이언트에 배포
② 각 클라이언트에서 로컬 모델(Local Model) 학습
③ 로컬 모델의 학습된 결과(가중치값)만 서버로 전송
④ 서버는 받은 가중치를 집계하여 글로벌 모델 재학습
▶연합학습에서 사용되는 주요 알고리즘
연합학습 시스템에서 중앙 서버의 글로벌 모델을 업데이트하기 위해 여러 가지 알고리즘이 사용됩니다. 대표적인 알고리즘으로는 FedSGD(Federated Stochastic Gradient Descent)와 FedAvg(Federated Averaging)이 있습니다[1][2].
1) FedSGD (Federated Stochastic Gradient Descent)
– 동작 방식 : 클라이언트(사용자 기기)에서의 한 번의 학습 과정에서 산출된 가중치를 매번 중앙 서버로 업데이트
– 장점 : 계산이 간단하고 직관적
– 단점 : 통신 횟수가 많고 매우 많은 수의 학습 라운드 필요
2) FedAvg (Federated Averaging)
– 동작 방식 : 각 클라이언트(사용자 기기)에서 일정 횟수만큼 학습 반복한 후, 그 평균 가중치를 중앙 서버로 업데이트
– 장점 : 클라이언트 간 데이터의 비일관성이 큰 경우에도, 각 클라이언트가 충분한 로컬 학습을 통해 보다 정확한 모델을 만들 수 있음. FedSGD에 비해 통신 감소.
– 단점 : FedSGD에 비해 계산이 복잡함
▶연합학습 주요 활용 사례
연합학습의 많은 장점으로인해 다양한 분야에서 이를 적용하기 위한 연구가 활발하게 진행되고 있습니다.
1) 구글의 GBoard
구글은 자사의 키보드 서비스에 연합학습을 적용하여 사용자의 단어 입력 패턴을 학습하고 사용자 맞춤형 추천 서비스를 제공합니다[3]. 이를 통해 사용자가 자주 사용하는 단어와 유사한 단어를 추천받을 수 있습니다. 네이버와 라인 앱도 유사하게 사용자의 키보드 입력 패턴을 통해 개인별 이모지추천 기능을 제공하여 사용자 경험을 향상시키고 있습니다[4][5].
2) 의료 분야
의료 분야는 연합학습에 대한 연구가 가장 활발히 진행되는 분야 중 하나입니다. 과거에는 개인 의료 데이터가 프라이버시와 현행 의료법 등의 법적 규제로 인해 AI 활용이 극히 제한되었고, 의료 데이터가 여러 병원에 분산되어 저장되는 문제도 있었습니다. 이에 연합학습을 활용하면 여러 병원에 따로 저장되어 있는 특정 질환에 대한 각각의 환자 데이터나 임상 데이터를 직접 공유하지 않아도, 모든 데이터를 한 곳에 모아서 분석한 것과 유사한 결과를 얻을 수 있습니다[6].
3) 자율주행
자율 주행 차량은 차량 한 대에서도 대규모 데이터를 생성하는데, 이 데이터들을 모두 하나의 중앙 스토리지에 저장하는 것은 불가능하며 네트워크 문제도 발생할 수 있습니다. 하지만 연합학습을 활용하면 자율 주행 차량에서 실시간 데이터 학습과 업데이트가 가능해 집니다. 또한 각 차량은 개인의 운전 스타일과 지역 특성에 맞춘 맞춤형 학습을 통해 운행 성능을 최적화할 수 있습니다.
▶ 연합학습의 단점 및 한계
1) 학습 결과의 공정성과 일관성 문제
– 한정된 로컬 데이터로 인해 학습 효율성이 저하될 수 있으며, 학습 결과가 특정 사용자들의 속성에 편향될 경우 공정성과 일관성에 문제가 발생할 수 있습니다.
2) 통신 단계에서의 보안 취약점
– 연합학습 과정 중 모델의 가중치를 전송하는 통신 단계에서 중간자 공격의 위험이 존재하며, 이는 시스템의 보안성을 심각하게 위협할 수 있습니다.
3) 기기 간 호환성 문제
– 사용자 기기의 다양한 환경과 사양으로 인해 호환성 문제가 발생할 수 있으며, 기기 간의 성능 차이는 시스템의 전반적인 효율성에 영향을 미칠 수 있습니다.
4) 로컬 학습을 위한 고성능 사용자 기기 성능 필요
– 연합학습의 핵심인 기기 내 학습(On-Device 학습)은 고성능을 요구하는 복잡한 모델을 학습하기 위해 상당한 자원을 필요로 합니다. 자원이 한정된 환경에서는 이러한 고성능 모델의 학습이 어려워, 모델 경량화 등의 기술적 고도화가 필요합니다.
▶ 결론
AI 기술이 발전함에 따라 많은 기회가 열리고 있지만, 한편으로는 개인정보 보호와 데이터 보안에 대한 우려도 커지고 있습니다. 이러한 상황에서 연합학습은 강력한 AI 모델을 개발하면서도 데이터 보안을 유지할 수 있는 중요한 해결책으로 주목받고 있습니다. 하드웨어 성능이 향상되면서 연합학습의 효율성과 속도 또한 개선되어 더욱 복잡한 모델을 학습할 수 있게 되었습니다. 최근 개인정보 보호 관련 법규가 강화되고 데이터 보안에 대한 요구가 높아짐에 따라, 연합학습 기술의 활용 가치는 더욱 커지고 있습니다. 향후 연합학습 기술의 지속적인 발전과 다양한 분야에서의 활용을 통해 보다 안전하고 효율적인 AI 생태계가 구축될 것으로 기대됩니다.
[참고 문헌]
[1] H. Brendan McMahan, E. Moore, D. Ramage, S. Hampson, and Blaise, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” pp. 1273–1282, Apr. 2017.
[2] Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. In Proceedings of the 2020 International Conference on Learning Representations (2020 ICLR), Addis Ababa, Ethiopia, 26–30 September 2020.
[3] “Federated Learning for Mobile Keyboard Prediction,” research.google. https://research.google/pubs/federated-learning-for-mobile-keyboard-prediction-2/
[4] “다수의 연합학습을 지원하기 위한 LFL 클라이언트 플랫폼,” LINE ENGINGEERING. https://engineering.linecorp.com/ko/blog/lfl-client-platform-for-multiple-federated-learning-instances
[5] “NAVER Search & Tech : 네이버 블로그,” blog.naver.com. https://blog.naver.com/naver_search/222273156342
[6] “연합학습 기술 동향 및 산업적 시사점”, 한국전자통신연구원 지식공유플랫폼, June 2020.
[7] “TensorFlow Federated,” TensorFlow. https://www.tensorflow.org/federated.
[8] KONEČNÝ, Jakub, et al. Federated optimization: Distributed machine learning for on-device intelligence. arXiv preprint arXiv:1610.02527, 2016.