1. Databricks와 Lakehouse Platform
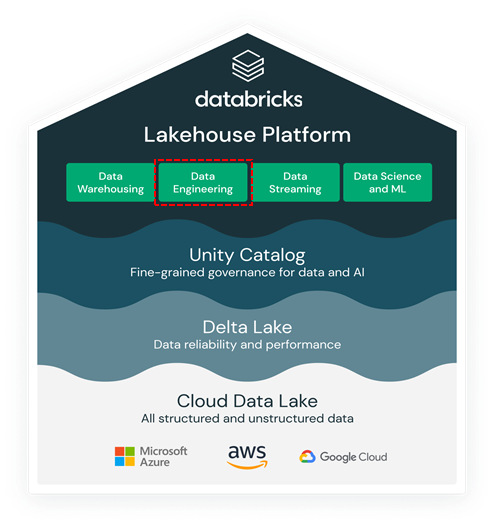
4. Databricks Data Engineering Workload
5. Databricks Data Warehousing Workload
6. Databricks Data Science and ML Workload
이번 시간에는 Databricks 네번째 소개시간으로 Databricks Engineering Workload에 대해서 이야기해 보고자 합니다.
오늘날의 기업들은 value있는 데이터가 회사의 수익을 증가시키고, 고객의 경험을 향상시키며, 제품 및 서비스의 효율적인 운영이 가능하게 하는 전략적인 자산으로 사용되고 있음을 잘 인지하고 있습니다.
데이터는 이러한 모든 작업의 원동력이 되고 있습니다. 오늘날, 데이터는 서로 다른 데이터 소스에서 스트리밍되고, 수집되며, 때로는 데이터 교환으로 획득되거나 다양한 방식으로 사용되고 있습니다. 시간이 갈수록 데이터는 자산화가 되어지고 있습니다.
데이터팀은 분석, data science, 머신 러닝을 위해서 right 시간에 right한 데이터를 얻기 위해 노력하지만 데이터 엔지니어링을 위한 요구사항을 충족 하기가 쉽지 않은 상황입니다.
[ Data Engineering이 어려운 이유 ]
– 조직 전반에 걸쳐 점점 더 복잡해지는 데이터에 액세스 하고, 데이터를 관리하는 것이 가장 큰 도전이 되고 있습니다.
– 복잡성의 대부분은 데이터 볼륨과 타입이 폭발적으로 증가함에 따라 발생하며, 약 80%의 데이터가 비정형 or 반정형의 데이터입니다.
– 이러한 형식의 데이터를 변환하고 처리하기 위해 파이프라인을 관리하는 것은 오랜 시간이 걸리고 어려우며, 점점 더 많은 비용을 소모하게 됩니다.
1) Complex data ingestion methods: 데이터 수집은 다양한 소스에서 다양한 형식으로 배치 및 스트리밍 데이터를 획득하는 것을 의미합니다. 아파치 카프카와 같은 항상 실행되는 스트리밍 플랫폼을 사용하거나 아직 수집되지 않은 파일을 추적할 수 있어야 하기에 수집하는 것이 어렵고 복잡합니다. 데이터 엔지니어는 반복적이고 오류가 발생하기 위한 데이터 수집 작업에 많은 시간을 투자해야 합니다.
2) Data engineering principles: 데이터 엔지니어링은 민첩한(agile) 소프트웨어개발 방법론을 기반으로 합니다.
3) Third-party tools: ELT/ETL과 같은 자동화를 위한 orchestration을 위한 서드-파티 툴을 사용하는 경우가 있습니다. 타사도구를 사용하면 운영 오버헤드가 증가하고 시스템의 신뢰성이 저하됩니다.
4) Performance tuning: 모든 파이프라인과 워크플로우가 작성된 상태에서 데이터 엔지니어는 SLA를 충족하기 위해서 지속적으로 성능 튜닝에 집중해야 합니다.
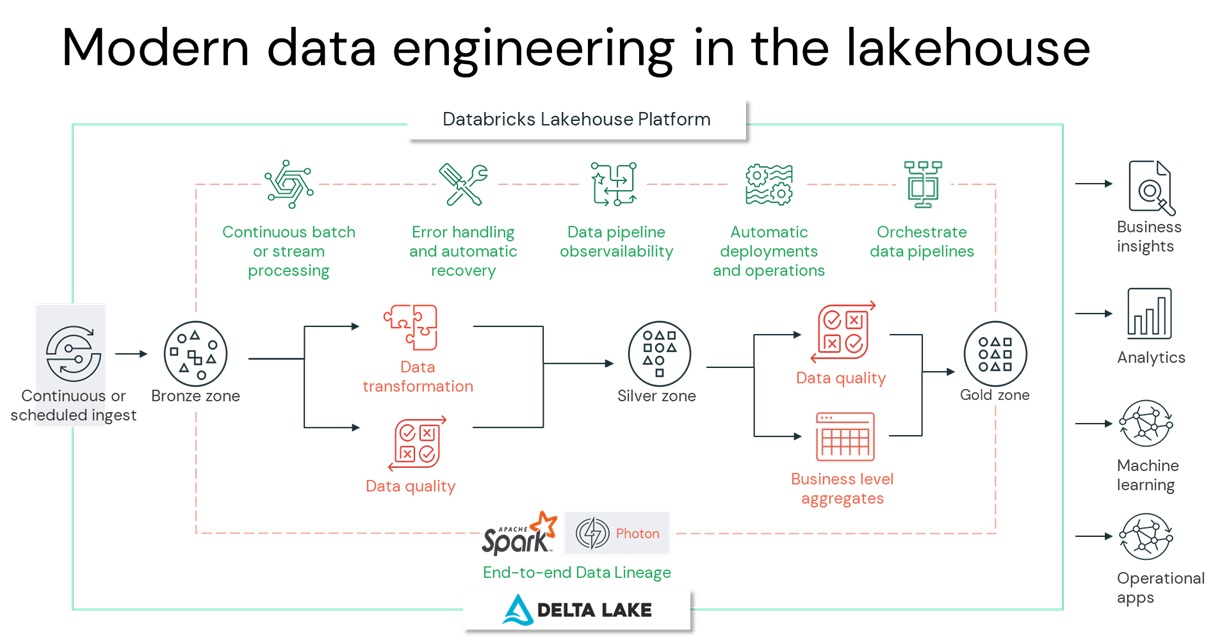
[ Databricks makes modern data engineering simple ]
– Data Lakehouse는 Unified data platform으로 모든 종류의 workflow 지원가능한 플랫폼입니다. ( managed data ingestion, schema detection, enforcement, auto-scaling data flow등)
– 데이터 엔지니어는 Databricks Lakehouse 플랫폼을 통해서 데이터를 수집, 변환, 처리, 스케줄링, delivering 할 수 있는 솔루션을 제공하고 있습니다.
– 복잡한 파이프라인 구축 및 관리를 자동화하고 ETL워크로드를 데이터 레이크에서 직접 실행하여 데이터 엔지니어가 품질과 신뢰성에 집중하여 가치 있는 insight를 이끌어 내도록 지원합니다.
– 데이터팀이 간소화된 아키텍처에서 배치 및 스트리밍 작업을 통합하는 것을 가능하게 하고, 스트리밍 데이터 파이프라인 개발, 테스팅, 신뢰성 있는 데이터, 분석 및 AI 워크플로우 구축이 가능한 환경을 제공합니다.
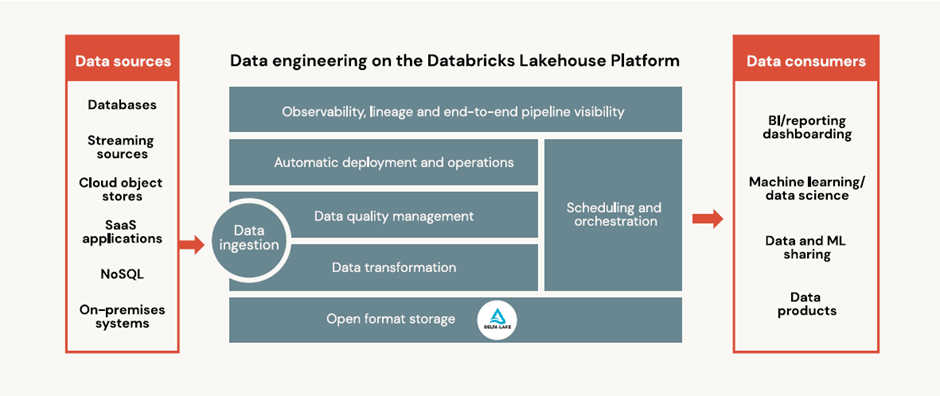
[ Benefits of data engineering on the lakehouse ]
1) Easy data ingestion: 데이터 엔지니어는 페타바이트 단위의 데이터 수집할 수 있는 기능을 통해 빠르고 안정적이며 확정성이 뛰어나며 자동화 가능한 기능을 제공받음.
2) Automated ETL pipelines: 데이터 엔지니어는 개발시간과 노력을 줄이고, SQL 및 Python을 사용하여 비즈니스 로직 구현 및 파이프라인 품질 검사에 더 집중할 수 있음.
3) Data quality checks: 데이터 팀은 데이터 품질을 정의하고 오류를 자동으로 해결하는 기능을 통해 데이터 신뢰성을 향상시킬 수가 있음.
4) Batch and streaming: 데이터 엔지니어가 복잡한 스트림 프로세싱을 모르고 복구 로직을 구현하지 않아도 비용 제어를 통해 데이터 지연 시간 설정 가능.
5) Automatic recovery: 빠르고 확장 가능한 내결함성을 통해 파이프라인 작동 중에 발생할 수 있는 가장 일반적인 오류조건에 대해 일시적인 오류를 처리하고 자동 복구 사용이 가능함.
6) Data pipeline observability: dataflow 그래프 대시보드에서 전체 데이터 파이프라인 상태를 모니터링하고 성능, 품질, 상태 및 지연에 대한 end-to-end 파이프라인 상태를 시각적으로 추적가능
7) Simplified operations: 프로덕션에 쉽게 자동 데이터 파이프라인을 배포하거나 파이프라인을 롤백 하고 가동중지 시간을 최소화해서 분석 및 기계 학습 사용 사례에 대한 안정적이고 예측 가능한 데이터 제공을 보장함
8) Scheduling and orchestration: Databricks 컴퓨팅 클러스터에서 방향성 비순환 그래프(DAG)를 통해 비대화형 작업 실행가능. 데이터 및 머신 러닝 파이프라인을 위한 데이터 프로세싱 Task를 단순화, 명확하며 안정적으로 orchestration이 가능함.
[Data engineering is all about data quality]
– 데이터 엔지니어링의 목표는 다운스트림 분석 및 AI에 적합한 품질로 데이터를 정제하는 것입니다.
1) 기술수준에서는 데이터 저장 및 수집을 위한 enforcing and evolving 스키마를 통해 데이터 품질을 보장하는 것
2) 아키텍처 수준에서는 메달리온 아키텍처를 구현해서 데이터 품질을 달성함. 메달리온 아키텍처는 각 레이어(브론즈, 실버, 골드 layer 테이블)를 통해 데이터가 흐를 때 데이터의 구조와 품질을 점진적으로 개선한다는 목표를 가지고 레이크 하우스 데이터를 논리적으로 구성하는 데 사용되는 데이터 디자인 패턴임.
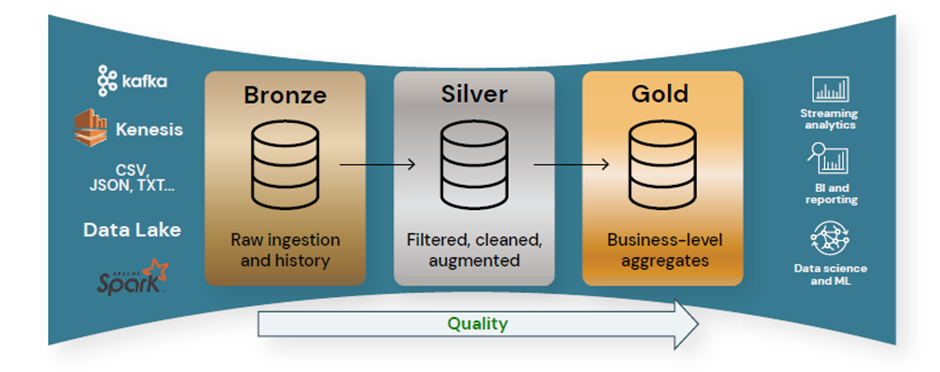
3) Databricks Unity Catalog에는 내장된 품질관리, 테스팅, 모니터링을 통해서 강력한 품질 관리 기능이 제공이 됨. 다운스트림 BI, analytics 및 머신 러닝 워크로드에 정확하고 유용한 데이터를 사용 할 수 있도록 보장함.
[ Data Ingestion ]
– Databricks Lakehouse 플랫폼을 사용하면 데이터 엔지니어는 스트리밍 및 배치 모드에서 강력한 확장가능한 수집 파이프라인을 구축할 수 있습니다.
– 클라우드 스토리지에 새로운 데이터 파일이 도착하면 Incremental 하게 데이터 증분 처리가 가능함 (상태정보를 관리 할 필요가 없음 )
– 엔지니어는 디렉토리에 파일을 나열하지 않고도 새파일을 효율적으로 추적이 가능함
– 원본데이터에서 자동으로 스키마를 추론하고 데이터가 Delta lake로 로드 할 때 스키마를 검사
1. What is Auto Loader?
– Auto Loader는 Databricks Lakehouse에 구축된 클라우드 스토리지에 새로운 데이터 파일이 도착할 때 이를 점진적으로 효율적으로 처리하는 최적화된 데이터 수집 도구입니다.
– 데이터의 스키마를 감지하고 적용할 수 있으므로 데이터 품질을 보장합니다.
– 새파일이나 마지막 새 데이터가 처리된 이후 변경된 파일은 자동으로 식별되어 수집됩니다.
– [trigger once] option을 사용하여 자동으로 꺼지는 작업으로 전환 가능함.
[사용예제]
stream = (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", checkpoint)
.load(rawDataSource)
.writeStream
.option("path", table)
.option("checkpointLocation", checkpoint)
.option("mergeSchema", True)
.table(tableName)
)2. Ingestion for data analysts: COPY INTO
– Databricks SQL을 사용하는 데이터 분석가 및 분석 엔지니어의 수집이 훨씬 쉬워졌습니다.
– COPY INTO는 하나의 폴더 location에서 Delta Lake table로 데이터를 로드 하는 간단한 SQL 명령입니다.
– COPY INTO는 예약 가능하며 job으로 반복적으로 호출될 수 있습니다. 실행하면 소스위치에 있는 새로운 파일만 처리가 되어집니다.
[사용예제]
%sql
CREATE TABLE IF NOT EXISTS my_table
[COMMENT <table-description>]
[TBLPROPERTIES (<table-properties>)];
COPY INTO my_table
FROM '/path/to/files'
FILEFORMAT = <format>
FORMAT_OPTIONS ('mergeSchema' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true');[ What is Delta Live Tables ]
– DLT (Delta Live Tables) 신뢰할 수 있는 데이터 파이프라인을 구축하기 위해 간단한 선언적 접근 방식을 사용하는 최초의 ETL 프레임 워크입니다.
– DLT는 인프라를 자동으로 확장하여 데이터 분석가와 엔지니어가 tooling에 더 작은 시간을 활용하고 데이터에서 더 많은 가치를 얻는데 집중할 수 있도록 지원합니다.
– 엔지니어는 데이터를 코드로 처리하고 테스팅, 오류처리, 모니터링, 문서화와 같은 최신 소프트웨어 엔지니어링 모범 사례를 적용하여 안정적인 파이프라인을 대규모로 구축할 수 있습니다.

– DLT는 Python 및 SQL을 지원하며, 스트리밍 및 배치 워크로드 지원합니다.
– DLT를 사용하여 SQL 노트북에 Delta Live Table을 작성하고 워크플로우 아래에 파이프라인을 생성한 후 [Start] 단순히 클릭하면 됩니다.
– DLT는 개발을 가속화하고 복잡한 운영 작업을 자동화하여 구현 시간을 단축합니다.
– DLT는 일반 SQL을 사용할 수 있기 때문에 데이터 분석가가 프로덕션 파이프라인을 생성하고 자주 논의되는 “분석 엔지니어”로 전환할 수도 있습니다.
– 실행 DLT는 Photon을 적용하여 파이프라인 실행속도를 높일 수 있습니다.
– DLT는 자동으로 컴퓨팅을 확장하여 최소 및 최대 인스턴스 수를 설정하고 DLT가 클러스터 활용도에 따라 클러스터 크기를 조정할 수 있는 옵션을 제공합니다.
– orchestration과 같은 Task, 에러 핸들링, 복구작업, 성능 최적화 등의 작업을 자동으로 처리합니다.
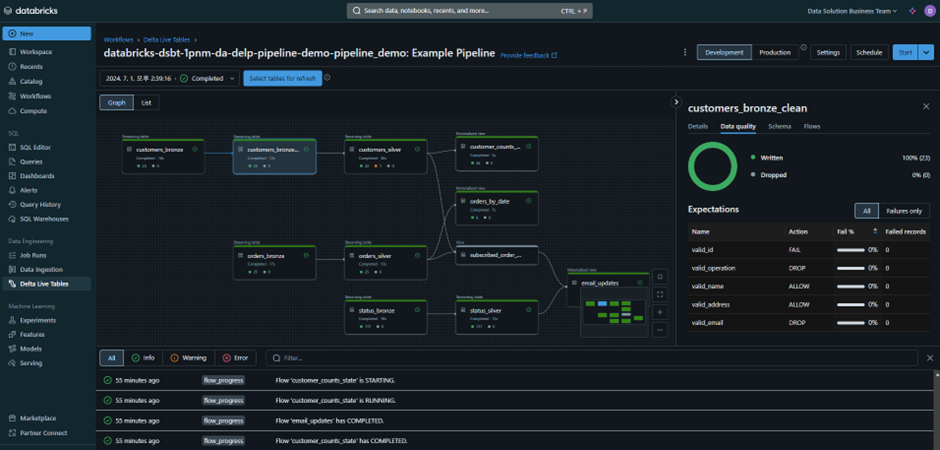
– 코드의 기대치는 불량 데이터가 테이블로 유입되는 것을 방지하고 시간 경과에 따른 데이터 품질을 추적하며 세분화된 파이프라인 관찰 가능성으로 불량 데이터를 해결하는 tool을 제공합니다
[ What is Databricks Workflows? ]
– Databricks Workflow는 데이터 팀이 모든 클라우드에서 안정적인 워크플로우를 구축할 수 있도록 지원하는 최초로 완전히 관리되고 통합되는 Lakehouse Orchestration 서비스입니다.
– 워크플로우를 사용하면 DLT 또는 dbt로 작성된 데이터 흐름 파이프라인뿐만 아니라 기계 학습 파이프라인, 노트북, Python wheel 과 같은 다양한 Task를 관리할 수 있습니다.
– 데이터 엔지니어는 운영 오버헤드를 제거하여 고객의 업무에 집중할 수 있습니다.
– 워크플로우는 인프라를 관리하는 것 아닙니다. 전문 스킬을 소유하지 않는 사람들도 쉽게 사용할 수 있는 point-and-click 경험을 제공합니다.
– 최종 사용자를 위한 중앙 집중적인 모니터링 기능을 제공하고 있습니다.
– 멀티플 Task에 대해서 job cluster를 공유하면 하나의 job에 소요되는 시간이 단축되며, 오버헤드를 제거해서 비용이 절감되며, 병렬 task로 클러스터 활용도를 높일 수 있습니다.
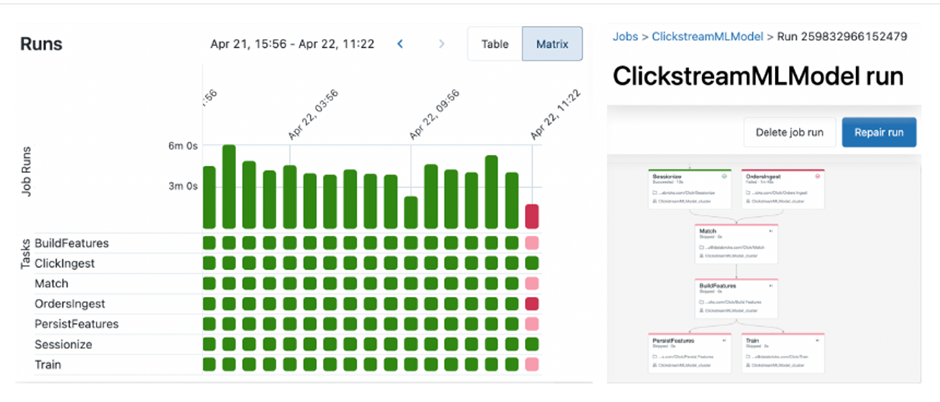
– 위의 그림은 그래프를 통해서 작업에 대한 실행 기록을 보여줍니다.
– 실패한 작업은 빨간색으로 표시가 되며, fail된 작업은 수정 후 다시 실행이 가능합니다. Fail된 task를 재실행하면 모든 dependency가 있는 task는 검색되고 실행됩니다.
– UI뿐만 아니라 Databricks Workflow API 또는 Apache Airway와 같은 외부 오케스트레이터를 통해서 워크플로우 생성이 가능합니다. 외부 오케스트레이터를 사용하는 경우에도 모니터링은 외부에서 트리거된 워크플로우를 단일 창으로 작동합니다.
– DLT는 Workflow의 많은 Task 유형중 하나입니다.(Notebook, Python Code, Databricks SQL, DLT Pipeline, Dbt Project, JAR file, Spark submit application)
이번시간에는 Data를 가지고 인사이트를 도출하기위한 일련의 준비작업을 제공하는 Databricks Engineering Workload (Data Pipeline 구축)에 대한 기본적인 지식을 알아보았습니다. 다음에는 Data Analysist에게 작업하는 환경을 제공하는 Databricks data warehousing에 대해서 알아보도록 하겠습니다.
[참고 문헌]
[1] Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia,Lakehouse: https://www.databricks.com/research/lakehouse-a-new-generation-of-open-platforms-that-unify-data-warehousing-and-advanced-analytics
[2] Bill Inmon, Ranjeet Srivastava, Rise of the Data Lakehouse
[3] Databricks, The Big Book of Data Engineering
[4] Databricks, The Data Team’s Guide to the Databric
[5] Databricks Documentation, https://docs.databricks.com/en/index.html
[6] Databricks Homepage, https://www.databricks.com
[7] Databricks Blog, https://www.databricks.com/blog