Databricks 비즈니스를 시작하면서 소개용으로 회사Blog에 시리즈로 연재하여 좀더 많은 사람들에게 알리고자 합니다.
Databricks 소개자료는 총 6회로 구성하고자 하며 다음과 같은 목차로 시작하고자 합니다.
1. Databricks와 Lakehouse Platform
4. Databricks Data Engineering Workload
5. Databricks Data Warehousing Workload
6. Databricks Data Science and ML Workload
오늘은 그 첫 번째로 Databricks와 Lakehouse Platform에 대해서 이야기를 해보고자 합니다.
[ Databricks 란 ]
Databricks는 The Data and AI Company 라고 소개하고 있습니다.
오픈소스에 기반을 둔 기업으로 2013년 Apache Spark, Delta Lake, ML flow를 개발한 주역들이 모여서 창업한 회사입니다. 본사(CEO: Ali Ghodsi)는 미국 샌프란시스코에 위치에 있으면 약 6,500명의 직원이 근무를 하고 있고, 한국지사(지사장: 장정욱 대표)는 2022년 4월에 공식 출범을 하였고 약 30명 이상의 Sales 및 SA분들이 근무를 하고 있습니다.
Databricks는 데이터 웨어하우스와 데이터 레이크의 장점만을 통합해서 Data Lakehouse Platform을 만든 개척자로서 하나의 플랫폼내에서 데이터와 AI를 복잡하게 하는 Data Silo를 제거하면서 모든 워크로드를 지원하는 플랫폼을 만들었으며, 이는 Cloud 환경 기반의 PaaS 플랫폼을 제공하고 있습니다.
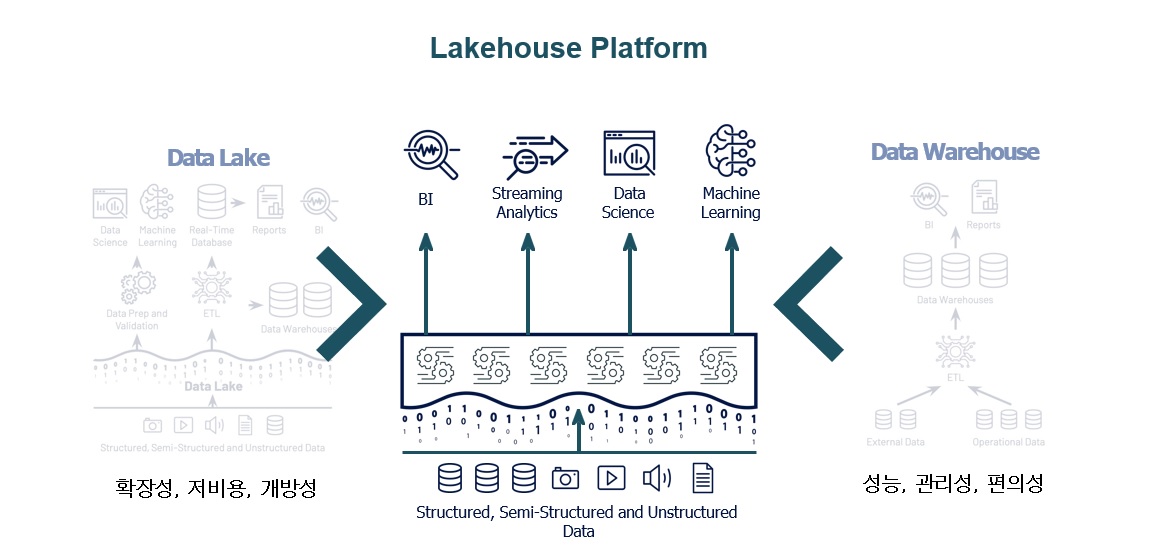
데이터 통합, 저장, 프로세싱, 거버넌스, sharing, 분석 및 AI를 위한 단일 아키텍처를 제공하고 있으며, 정형, 비 정형 등 모든 종류의 데이터 타입과 호환 가능하며, 하나의 데이터 lineage를 통해서 데이터가 어디에서 와서 어떻게 사용되었으며, 어디로 흘러가는지를 하나의 뷰를 제공할 뿐만 아니라, 하나의 Notebook이라는 IDE 툴을 통해서 Python, Scala, SQL, R 개발 환경을 제공합니다. Batch 및 Streaming Data 데이터 프로세싱도 가능하며, 모든 메이저 네이티브 클라우드 Provider (AWS, ZURE, GCP) 위에서 작동이 가능합니다.
이제부터는 Lakehouse Platform이 무엇인지 좀더 깊게 알아가 봅시다.
[ Databricks Lakehouse Platform ]
데이터 웨어하우스는(DW) 의사결정 지원 및 비즈니스 인텔리전스(BI) 분야에서 오랜 역사를 지니고 있습니다. 1980년대 후반에 시작된 데이터 웨어하우스 기술은 계속적으로 발전하였고 MPP 아키텍처는 더 큰 데이터 크기를 처리하는 시스템으로 이어졌습니다. 그러나 최근 들어 대부분의 기업들은 정형화된 데이터뿐만 아니라, 반정형화된 데이터, 비정형화된 데이터처리를 요구하고 있으며, 데이터의 크기 증가 및 실시간 처리를 위한 인프라를 요구하고 있는데 데이터 웨어하우스는 이러한 다양한 Use Case에 적합하지 않을 뿐 더러 비용 효율적인 시스템이 아닌 걸로 나타나고 있습니다.
기업들은 다양한 소스에서 대량의 데이터를 수집하기 시작했고, 아키텍처들은 다양한 분석 제품 및 워크로드에 대한 데이터를 저장할 단일 시스템을 구상하기 시작했습니다. 다양한 형식의 원천데이터를 저장할 수 있는 하나의 레파지토리인 데이터 레이크 (Data Lake)를 구축하기 시작했습니다. 데이터 레이크는 데이터를 저장하기에는 적합하지만 기존 데이터 웨어하우스가 지니는 중요한 기능들을 제공하지 못했습니다. 예를 들면, 트랜잭션처리를 지원하지 않아서, 데이터 품질에 대한 이슈가 발생했고, Consistency 및 Isolation 미지원은 동시에 read, write 작업을 힘들게 했으며, batch 및 Streaming Job 처리가 쉽지 않았습니다.
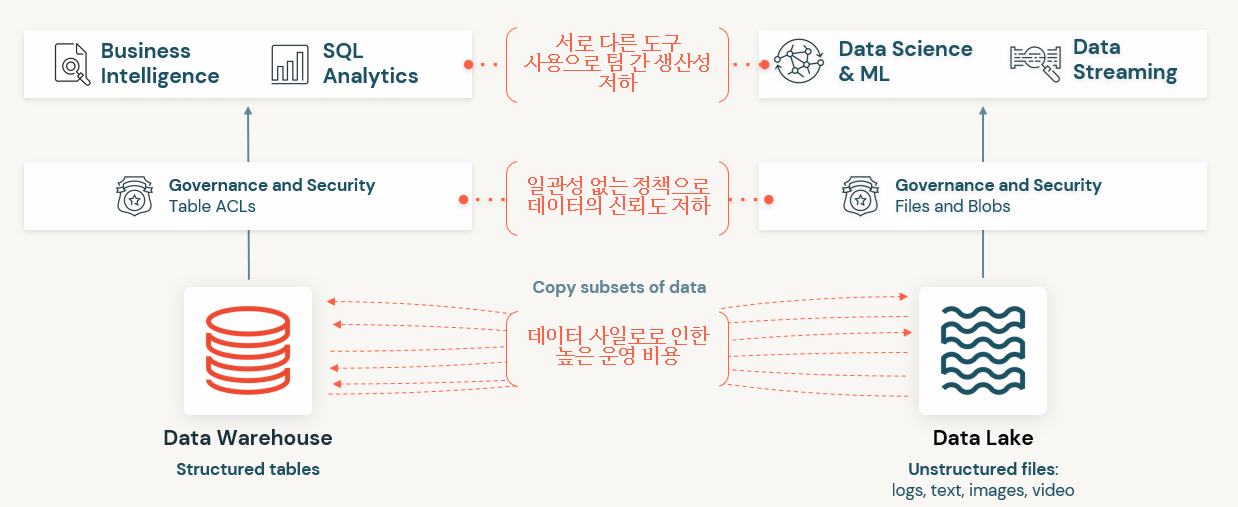
유연하고 고성능 시스템에 대한 필요성은 갈수록 증가하고 있으며, 많은 기업들이 SQL 분석, 실시간 모니터링, 데이터 사이언스 및 머신 러닝 작업이 가능한 다양한 데이터 애플리케이션을 지원하는 시스템을 필요로 하고 있습니다. 최근 인공지능의 발전은 비정형데이터(텍스트, 이미지, 비디오, 오디오)를 처리하기 위한 최상의 모델이 되었지만 이러한 데이터는 데이터 웨어하우스에 최적 화된 데이터 타입이 아닙니다. 데이터 레이크, 데이터 웨어하우스, 스트림밍, 타임 시리즈, 그래프, 이미지 데이터베이스와 같은 다양한 시스템을 이용하는 것이 일반적인 접근 방법입니다. 하지만 한 회사에서 여러 시스템을 사용하는 것은 복잡성을 야기시키며, 다른 시스템 간에 데이터를 이동시키거나 복사로 인한 delay를 초래하고 있습니다.
데이터 레이크의 한계를 해결하는 새로운 시스템이 등장하기 시작하고 있습니다. Lakehouse는 데이터 레이크와 데이터 웨어하우스의 최고의 요소들을 결합한 새로운 오픈 아키텍처입니다. Lakehouse는 오픈 포맷의 저비용 클라우드 스토리지 위에 데이터 웨어하우스에 있는 것 과 유사한 데이터 구조와 데이터 관리 기능을 직접 구현한 새롭게 생성된 시스템 설계로 구현되었습니다.
값싸고 신뢰성이 높은 스토리지(object stores의 형식으로)를 사용할 수 있게 되면서 가능하게 되었습니다.
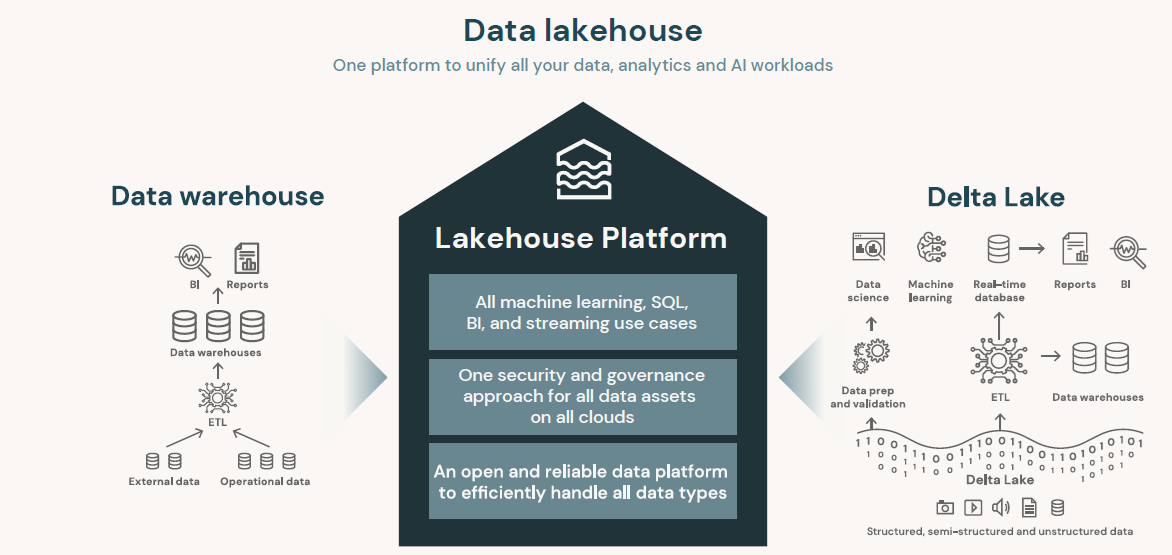
Data Lakehouse의 주요 특징은 다음과 같습니다.
1) Transaction Support: 엔터프라이즈 레이크하우스에서는 여러 데이터 파이프라인이 동시에 읽고, 쓰기작업이 진행되는 경우가 많이 발생합니다. 일반적으로 여러 명의 사용자들이 동시에 데이터를 읽거나 쓰기 작업을 진행하고 있기 때문에 ACID(Atomicity, Consistency, Isolation and Durability) 트랜잭션을 지원함으로써 일관성이 보장이 됩니다.
2) Schema enforcement and governance: Lakehouse는 DW 같은 스키마 아키텍처를 지원하며, Schema enforcement 와 Schema evolution을 지원합니다. 그와 동시에 Data 무결성을 보장해야 하며, 강력한 거버넌스와 Auditing 메커니즘을 지원하고 있습니다.
3) BI Support: Lakehouse는 BI tool을 직접 원천 데이터(Source data)에 사용할 수 있게 할 수 있으며, 이를 통해서 데이터 레이크와 웨어하우스 사이에 데이터 복사본을 운영해야 하는 비용을 절감하고 지연 시간을 단축할 수 있습니다.
4) Storage is decoupled from compute: 실제로 스토리지와 컴퓨팅 자원이 별개로 분리되어 사용하므로 동시 사용자 증가 및 데이터 증가 시 분리된 cluster를 확장할 수 있습니다. (일부 최신의 데이터 웨어하우스에서도 이러한 기능이 추가됨)
5) Openness: 데이터레이크에서 사용하는 스토리지 format이 parquet파일과 같은 오픈 되고, 표준 화되어 있으며, API를 제공하므로 머신러신 및 Python/R 라이브러리를 포함하는 다양한 Tool과 엔진이 직접 데이터에 효율적으로 접근 가능합니다.
6) Support for diverse data types ranging from unstructured to structured data: Lakehouse는 이미지, 비디오, 오디오, 반정형 데이터 및 텍스트를 포함하는 다양한 데이터 타입들을 저장, 정제, 분석, 액세스 하는데 사용 할 수 있습니다.
7) Support for diverse workloads: 하나의 데이터 repository를 사용하여 데이터 사이언스, 머신 러닝, SQL 및 분석을 포함하여 다양한 워크로드를 지원합니다.
8) End-to-end streaming: 실시간 보고서는 많은 회사에서 일반적으로 많이 사용되고 있습니다. 스트림밍 지원하는데 있어서 전용 실시간 데이터 애플리케이션을 제공하는 별도의 시스템 없이 Lakehouse에서 가능합니다.
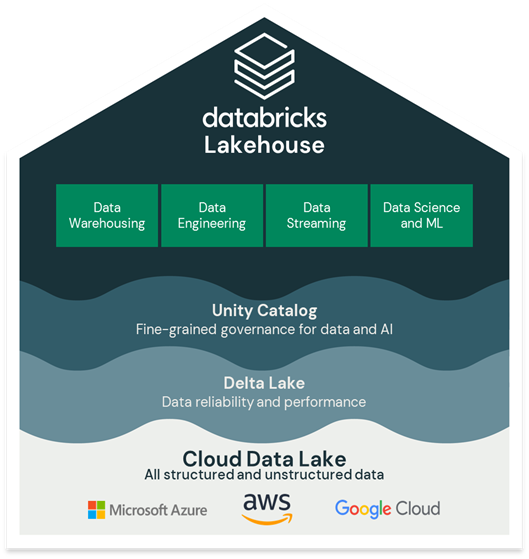
위의 특징들이 Lakehouse의 주요 요소들이며, 엔터프라이즈 등급의 시스템들은 추가적으로 Security 및 Access Control이 필요합니다. 특히 최근의 개인정보 규정에 비추어 보면, auditing, retention 및 lineage를 포함하는 데이터 거버넌스는 필수 기능이 되었습니다.
데이터 카탈로그 및 데이터 사용 메트릭스와 같은 데이터 검색이 가능한 tool도 필요하게 되었습니다.
하나의 Lakehouse Platform으로 이러한 엔터프라이즈 기능을 구현, 테스트, 관리가 가능하게 되었습니다.
Databricks Lakehouse Platform의 장점을 정리해 보면 다음과 같습니다
1) Simple: 전통적인 대부분의 시스템과는 다르게 analytics, BI, data science and machine learning 시스템이 분리되어 발생하는 데이터 silos를 제거하여 데이터 아키텍처를 단순화합니다. 하나의 통합된 시스템구성으로 복잡성과 높은 운영비용을 제거할 수 있습니다.
2) Open: 오픈소스와 오픈 표준을 기반으로 구축된 Lakehouse는 Delta Lake를 기반으로 데이터에 품질에 대한 실뢰성과 높은 성능을 제공하고 있습니다. vender lock-in을 제거함으로써 오픈소스 데이터 생태계를 구축하고 있으며 동시에 databricks 파트너 네트워크 통해서 협업 가능한 환경을 제공하고 있습니다.
3) Multicloud: 모든 클라우드 환경(AWS, AZURE, GCP)에서 일관된 유지관리, 보안 및 거버넌스를 제공합니다. Data 관련팀들은 클라우드 환경프로세스를 재구성 할 필요없이 데이터로 Insight를 도출하는 업무에 집중 할 수 있습니다.
Databricks Lakehouse Platform architecture 근간을 이루는 기술입니다.
1) Data reliability and performance for lakehouse:
Delta Lake는 모든 주요 분석 툴과 통합되는 레이크 하우스를 위해 구축된 개방형 포맷 스토리지 계층으로 가장 다양한 포맷으로 데이터를 저장하고 처리할 수 있습니다.
Photon은 레이크하우스를 위해 구축된 차세대 쿼리 엔진으로, 최첨단 벡터화 엔진을 활용하여 빠른 쿼리를 수행하며, 레이크하우스의 모든 워크로드에 대해 최고의 성능을 제공합니다
2) Unified governance and security for lakehouse:
Databricks Lakehouse 플랫폼은 엔터프라이즈 규모, 보안 및 컴플라이언스를 갖춘 통합 거버넌스를 제공합니다. Datbricks Unity Catalog(UC)는 Lakehouse에 있는 데이터 및 AI 자산(파일, 테이블, 대시보드 및 머신러닝 모델)에 대한 거버넌스를 제공합니다
Delta Sharing은 기업이 데이터가 상주하는 플랫폼에 관계없이 실시간으로 조직 전반에 걸쳐 데이터를 안전하게 공유할 수 있는 개방형 프로토콜입니다.
3) Instant compute and serverless:
서버리스 컴퓨팅은 데이터브릭이 고객 계정 대신 데이터브릭 클라우드 계정에서 고객을 대신하여 컴퓨팅 계층을 프로비저닝하고 관리하는 완전 관리 서비스입니다. 서버리스 컴퓨팅은 데이터브릭 SQL과 함께 사용할 수 있도록 지원됩니다.
차후 우리는 Databricks Lakehouse Platform 위에서 작동하는 각각의 기능들에 대해서 알아볼 예정입니다. (Delta Lake, Unity Catalog, Data Warehousing, Data Engineering, Data Science and ML)
[참고 문헌]
[1] Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia, Lakehouse:ANewGenerationofOpenPlatformsthatUnify DataWarehousingandAdvancedAnalytics, https://www.databricks.com/research/lakehouse-a-new-generation-of-open-platforms-that-unify-data-warehousing-and-advanced-analytics
[2] Bill Inmon, Ranjeet Srivastava, Rise of the Data Lakehouse
[3] Databricks, The Big Book of Data Engineering
[4] Databricks, The Data Team’s Guide to the Databric
[5] Databricks Documentation, https://docs.databricks.com/en/index.html
[6] Databricks Homepage, https://www.databricks.com