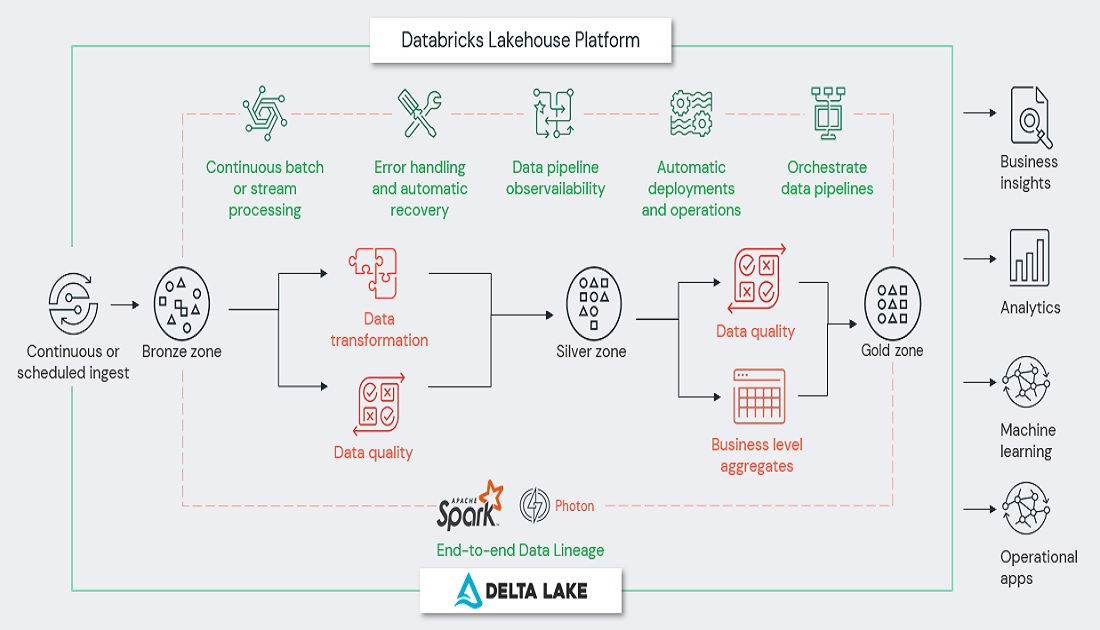
1. Databricks와 Lakehouse Platform
2. Databricks Delta Lake
4. Databricks Data Engineering Workload
5. Databricks Data Warehousing Workload
6. Databricks Data Science and ML Workload
이번 장은 Databricks 두번째 소개 시간으로 Databricks Lakehouse의 근간을 차지하고 있는 Delta Lake에 대해서 이야기해 보고자 합니다.
[ Data Lake가 가지는 주요 문제점 ]
1) Lack of ACID transactions: Update, append and read 작업을 동시에 혼합해서 사용하기가 어렵습니다.
2) Lack of schema enforcement: 데이터에 일관성이 없고 품질이 낮은 데이터 발생 가능성이 높습니다.
3) Lack of integration with data catalog: single souce of truth 구현이 안됩니다.
그 외에도 데이터 엔지니어는 생성하는 데이터 파이프라인에서 고품질 데이터를 보장하기 위해서 추가적인 작업을 진행해야만 했습니다.
성능관점에서 보면 data lake은 주로 객체 스토리지를 사용하면서 불변파일에 보관이 되므로 다음과 같은 문제를 야기시켰습니다.
1) Ineffective partitioning: 데이터 엔지니어는 파일 크기를 조정 하면서 파티셔닝 형식으로 인덱싱을 통해서 읽기/쓰기 성능을 향상시키고자 합니다. 잘못된 필드로 파티션을 하거나 높은 카디널리티 열로 인해서 시간이 지남에 따라 파티션이 효율적이지 않아서 성능 이슈가 발생하곤 합니다.
2) Too many small files: 트랜잭션을 지원하지 않아서, 새로운 데이터를 추가하면 점점 더 많은 파일이 추가되는 형태가 되어 쿼리성능 저하의 근본 원인으로 알려진 “small files issue” 가 발생합니다.
이러한 이슈사항들은 Lakehouse에서 두가지 핵심 기술인 Delta Lake and Photon 으로 해결이 됩니다.
[ 델타레이크란 ? ]
– Databricks lakehouse 플랫폼위에서 다양한 형식의 데이터 및 테이블을 저장 할 수 있는 기반을 제공하는 최적화된 storage layer 입니다
1) 오픈소스 소프트웨어로서 ACID 트랜잭션 및 확장 가능한 메타데이터 처리를 위한 파일기반의 트랜잭션 로그를 관리하고 있습니다.
2) 기존의 Data lake위에서 실행이 되어 Apache Spark API 및 다른 프로세싱 엔진과 호환이 됩니다.
3) Apache Parquet기반으로 하는 Delta Tables를 사용하여 기존의 파케 테이블을 델타 테이블로 쉽고 빠르게 전환 가능합니다.
4) 델타 테이블은 정형데이터, 반구조화된 데이터, 비정형 데이터등 모든 형식의 데이터가 함께 사용이 가능합니다.
5) 버전 관리 제공, 타임 트래블기능, 메타데이터 관리의 기능 제공하고 있습니다.
[ 델타레이크의 주요 기능 ]을 좀더 깊게 살펴보면 아래와 같습니다.
1) ACID guarantees: 커밋된 모든 데이터 변경사항이 스토리지에 기록되어 ACID를 보장하여 데이터 불일치나 부분적 파일 손상을 방지하고 있습니다.
2) Scalable data and metadata handling: Delta Lake은 data lake를 기반으로 지어졌기 때문에 Spark 나 다른 분산처리 엔진을 사용하는 모든 읽기 및 쓰기는 기본적으로 페타바이트 규모로 확장이 가능하고, 특히 Spark를 활용하여 모든 메타 데이터 처리를 확장하므로 수십억 개의 메타 데이터 파일을 효율적으로 처리가 가능합니다.
3) Audit history and time travel: 트랜잭션 로그에는 데이터를 변경할 때마다 변경 사항에 대한 디테일 한 사항을 보관이 되며, 풀 audit관리를 제공하고 있습니다. 이러한 데이터 스냅샷을 통해서 개발자는 일정시점의 데이터로 액세스 하거나 과거 시점으로 데이터를 rollback이 가능합니다.
4) Schema enforcement and schema evolution: 테이블 스키마에 일치하지 않는 데이터가 자동적으로 삽입되는 것을 방지하고 스키마 변경 시 기존 데이터에 상관없이 수용이 가능한 구조를 가지고 있습니다.
5) Support for deletes, updates and merges: 대부분의 분산 처리 프레임워크는 data lake의 파일 수정 작업을 지원하지 않지만, Delta Lake는 merge, update, delete 작업을 지원하여 변경데이터 캡처(CDC), slowly changing demension(SCD) 작업, 스트리밍 upserts등 복잡한 use case를 지원하고 있습니다.
6) Streaming and batch unification: Delta Lake Table은 배치 및 스트리밍 작업에 source 및 sink로 모두 사용이 가능합니다. 스트리밍 데이터 수집에서부터 대화형 쿼리, 배치 작업까지 모든 작업 처리에 활용이 가능합니다.
[ Delta Lake 트랜잭션 로그(DeltaLog) ] 에 대해서 좀더 자세히 알아봅시다.
– 트랜잭션 로그는 델타 레이크 테이블에서 수행된 모든 트랜잭션을 순차적으로 기록하는 로그 파일입니다.
– 사용자가 테이블 수정 작업(insert, update 또는 delete등)을 수행할 때마다 Delta Lake는 하나의 작업을 Atomic Commit(Add, Remove, Update metadata, Set transaction, Change protocol, Commit info)로 분리하거나, 조합해서 저장하고 있습니다.
– 예들 들어보면, 사용자가 테이블에 하나의 컬럼을 추가하고 테이블에 일부 데이터를 추가했다고 하면, Delta Lake는 하나의 트랜잭션을 컴포넌트로 break down 해서 트랜젝션 로그에 다음과 같은 commits으로 등록하고 있습니다.
1. Update metadata – 새로운 컬럼을 포함하여 스키마 변경하는 경우 등록합니다.
2. Add file – 각 새로운 파일이 add된 경우 속성을 등록합니다
[ 파일 레벨로 Delta Lake Transaction Log 처리 과정 ]
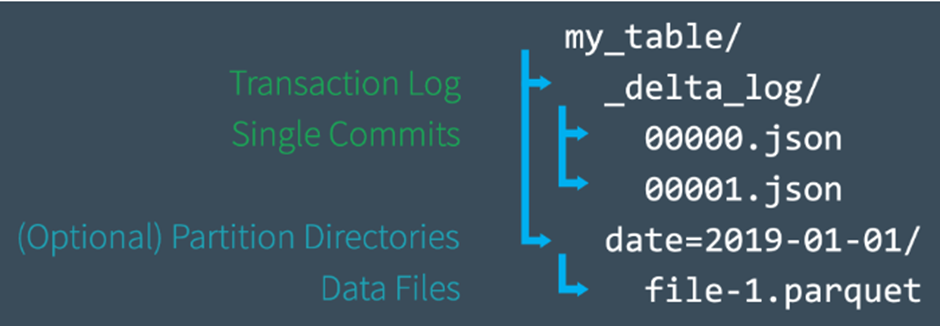
– 사용자가 테이블 생성하면 모든 테이블의 트랜잭션 로그는 테이블 디렉토리 아래에 _delta_log라는 subdirectory로 자동 생성되어 저장.
– 테이블 변경 시 transaction log에 변경 사항은 순차적으로 저장이 되며, atomic commits로 분리됨
– 각각의 commit는 JSON 파일로 작성
– 000000.json으로 시작해서, 000001.json, 000002.json등 다음 커밋 마다 순차적으로 증가됨
예제를 통해서 더 자세히 확인해 보겠습니다.

1) 테이블에 레코드 추가 ( 데이터 파일 1.parquet and 2.parquet ) 하면 자동적으로 트랜잭션 로그에 add됨 ( commit 000000.json 으로 디스크에 저장됨)
2) 이 파일들을 삭제하고 새로운 파일 add ( 데이터 파일 3. parquet ) 하기로 결정
3) commit으로서 트랜잭션 로그에 000001.json 로 기록됨
4) 1.parquet and 2.parque는 더 이상 Delta Lake Table의 부분이 아니지만 add 및 removal 내역은 여전히 트랜잭션 로그에 남아있음.
5) 델타레이크는 atomic commit을 여전히 보유하고 있음 ( 테이블 audit이 필요하거나, “time travel”을 위해서 내역 보관)
6) Spark는 테이블의 데이터를 삭제한 경우에도 디스크에서 Json files 삭제를 안함. 차후 사용자는VACCUM 명령어를 통해서 Json 파일을 삭제 가능함
[ 트랜잭션 log의 Checkpoint File 생성 과정]
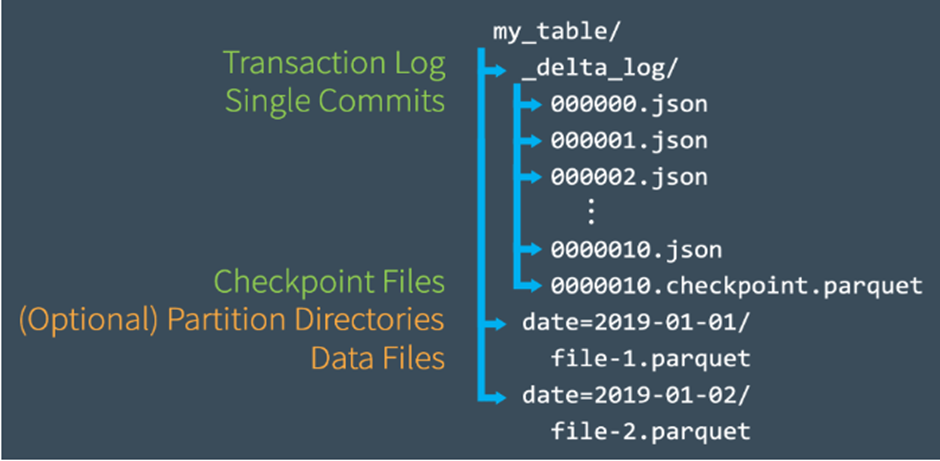
– Checkpoint 파일을 통해서 테이블의 상태를 빠르게 계산하는 것이 주목적입니다.
– 여러 번의 commit이 트랜잭션 로그에 반영된 후 델타 레이크는 자동적으로 checkpoint file을 생성함. 파케 포맷으로 저장이 되며, 10개의 json 파일이 생성될 때마다 하나의 checkpoint 파케 파일이 read 성능 향상을 위해서 자동 생성됩니다.
– 비효율적으로 수천개의 작은 파일을 읽는 것이 아니라 그 시점의 최적의 테이블 상태를 읽어오기 위해서 checkpoint file 파일을 사용합니다.
– 스파크는 가장 최근의 checkpoint file이 만들어진 이후의 Json commit만 읽어와서 성능을 향샹시킵니다.
[ 트랜잭션 log의 Checkpoint File 생성 예제 ]

1) 000007.json commit 발생함
2) spark는 테이블 상태를 메모리에 자동으로 caching 하여 읽기 속도를 높일 수 있음
3) 중간에 많은 commit이 발생(000012.json까지 commit됨)
4) Spark는 최신의 상태를 확인하기 위해서 모든 json파일을 읽는 것이 아니라 가장 최근의 checkpont 파일과 000011.json, 000012.json 파일만 처리함
5) Spark는 메모리에 version12로 cache 처리함
[ 동시작업 처리 방안 ]
– Delta Lake는 Apache Spark를 기반으로 하기 때문에 멀티플 사용자들이 하나의 테이블에 동시에 수정하는 것이 가능하고, 이것을 “Optimistic Concurrency Control” 라고합니다.
– Optimistic Concurrency Control (최적 동시성 제어)는 서로 다른 사용자가 테이블에 작업한 트랜잭션이 서로 충돌없이 작업을 가능하게 하는 방법을 말합니다. (mutual exclusion으로 내부적으로 구현되고 있습니다.)
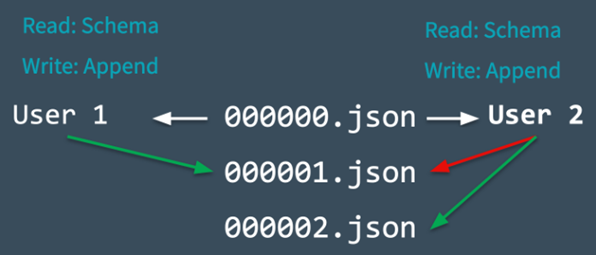
1) Delta Lake는 변경하기전 테이블의 시작상태 테이블 버전(version 0)을 기록
2) User1, 2 동시에 테이블에 data append 시도 -> 하나의 commit만 가능하므로 출동 발생
3) Delta Lake는 이러한 충돌을 “mutual exclusion”으로 처리함 ( user1만 commit 000001.Json 으로 성공시킴) , User2는 Reject됨
4) 단순히 user2에대해서 error 발생 했다고 던지는 것만 아니라 delta lake는 이러한 충돌을 Optimistically 하게 처리함. -> 새로운 commit이 있는지 확인하고 이러한 변경사항을 반영하여 user2의 commit을 새롭게 변경된 테이블로 반영함, 그래서 성공적으로 0000002 json 파일이 커밋됨
[ Photon이란? ]
– Databricks Lakehouse Platform의 차세대 쿼리엔진입니다.
– C++로 작성되어 고성능 스파크 실행 엔진을 제공하고 있습니다.
– 데이터 수집, ETL, 스트리밍, ML, 인터랙티브 쿼리 등 모든 사용 사례에 대해서 극적인 인프라 비용 절감과 속도 향상을 제공하고 있으며, Spark API와 호환되며, 데이터를 효율적으로 처리할 수 있는 일반적인 실행 framwork 구현이 가능합니다.
– 기존 Databricks Runtime(Spark) 대비 최대 80% TCO 절감효과가 확인 되었습니다..
– Databricks SQL warehouse에서는 기본으로 활성 화 되어 있습니다.
이번장에서 스토리지 레이어인 Delta Lake에 대해서 알아보았고 차후에는 하나의 통합된 환경에서 Security와 Governance는 담당하고 있는 Unity Catalog에 대해서 알아보겠습니다.
[참고 문헌]
[1] Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia, Lakehouse:ANewGenerationofOpenPlatformsthatUnify DataWarehousingandAdvancedAnalytics, https://www.databricks.com/research/lakehouse-a-new-generation-of-open-platforms-that-unify-data-warehousing-and-advanced-analytics
[2] Bill Inmon, Ranjeet Srivastava, Rise of the Data Lakehouse
[3] Databricks, The Big Book of Data Engineering
[4] Databricks, The Data Team’s Guide to the Databric
[5] Databricks Documentation, https://docs.databricks.com/en/index.html
[6] Databricks Homepage, https://www.databricks.com
[7] Databricks Blog, https://www.databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html