1. Databricks와 Lakehouse Platform
4. Databricks Data Engineering Workload
5. Databricks Data Warehousing Workload
6. Databricks Data Science and ML Workload
Databricks의 마지막 소개 세션입니다. 오늘은 Data science와 machine learning에 대해서 소개하고자 합니다.
대부분의 기업은 머신 러닝과 AI를 적용함으로써 얻을 수 있는 잠재적인 이점을 알고 있지만 실현하는 것은 상당이 어려울 수 있습니다. 가장 큰 장애물 중 일부는 사일로화 되고 서로 다른 데이터 시스템, 복잡한 실험 환경 및 운영 환경에서 모델을 제공하는 데서 발생합니다.
다행히도 Databricks Lakehouse 플랫폼은 데이터를 사용하여 혁신적인 통찰력을 도출하고 강력한 예측 모델을 구축하고, 데이터 과학자, ML 엔지니어 및 모든 종류의 개발자가 기계 학습 및 AI 공간에서 작업할 수 있도록 지원합니다.
Databricks Machine Learning

[ 탐색적 데이터 분석 ]
– 모든 데이터를 하나의 장소에 배치하여 내장된 시각화, 대시보드는 물론 다양한언어(R, SQL, Python, Scala)를 지원하는 노트북 스타일 환경내에서 데이터를 쉽게 탐색하고 시각화 할 수 있습니다.
– 협업해서 작성하고, 주석 달고, 자동 버전 관리, Git 통합 및 역할 기반 액세스 제어를 통해 코드를 안전하게 공유할 수 있습니다.
[ Model creation and management ]

– Lakehouse는 데이터 수집부터 모델 훈련, 튜닝, 프로덕션 모델 서빙 및 버전관리에 이르기까지 이러한 일련의 작업들의 단순화하는데 필요한 tool을 제공하고 있습니다.
– scikit-learn, XGBoost 등과 같은 가장 널리 사용되는 라이브러리를 포함하도록 최적화되고 사전 구성된 Databricks ML 런타임으로 바로 작업이 가능합니다. GPU를 사용한
통한 분산 training 및 하드웨어 가속화에 내장된 지원 때문에 대규모 확장이 가능합니다.
– 데이터브릭스가 만들 오픈 소스 머신 러닝 플랫폼인 MLflow을 사용하여 모델 training 세션을 추적하고, 모델을 패키징하고 재사용할 수 있습니다. MLfolw는 Lakehouse내에 관리형 서비스로 포함되어 있습니다. 쉽게 재사용 가능한 방식으로 모델 및 패키지 코드를 관리하는 중앙화 된 location을 제공합니다.
– 이러한 모델을 트레이닝하려면 중앙 집중식 feature store에 저장되는 feature를 사용하는 경우가 많습니다. Databricks는 내장된 feature store가 있어서 새로운 feature를 만들고 탐색 및 기존 feature 재사용 할 수가 있습니다. 기계학습 모델을 훈련하고 스코어링 하기 위한 feature를 선택하고 실시간 추론을 위해 낮은 지연성을 갖는 온라인 스토어에 feature를 publish할수 있습니다.
– 먼저 시작하려는 경우 AutoML을 사용하여 코딩 없이 실험을 수행할 수 있습니다. 데이터 세트를 지정하여 모델을 자동으로 학습하고 hyperparameter를 조정하여 초보자, 고급사용자 할 것 없이 머신 러닝 프로세스의 시간을 절약할 수 있습니다.
– AutoML은 또한 모델 트레이닝 결과와 관련된 metrics은 물론 data set에 이미 맞춤화된 training을 반복하기 위해 필요한 code도 생성하고 있습니다.
[ Deploy your models to production ]
– 기계 학습 모델을 탐색하고 생성하는 것은 일반적인 작업의 일부일 뿐입니다. 모델이 존재하고 성능이 좋으면 모델을 업데이터하고 모니터링하며 다른 사람이 사용할 수 있도록 유지해야 하는 파이프라인의 일부가 되어야 합니다.
– 데이터브릭스는 모델 자체를 생성하는 데 사용할 수 있는 동일한 플랫폼 내에서 모델 버전관리, 모니터링 및 serving을 위한 세계적 수준의 경험을 제공하고 있습니다. 즉 모든 ML 파이브라인을 동일한 장소에서 만들고, 모델 drift를 모니터링 하고, 새로운 데이터로 재교육하고, 규모에 맞게 쉽게 promote 및 서빙 할 수 있습니다.
– ML 라이프사이클 전체에 걸쳐 lineage 및 governance가 전체적으로 추적되고 있습니다. 이는 향후 규제준수 및 보안 문제를 크게 줄여서 비용이 많이 발생하는 이슈를 줄 일수 있음을 의미합니다.

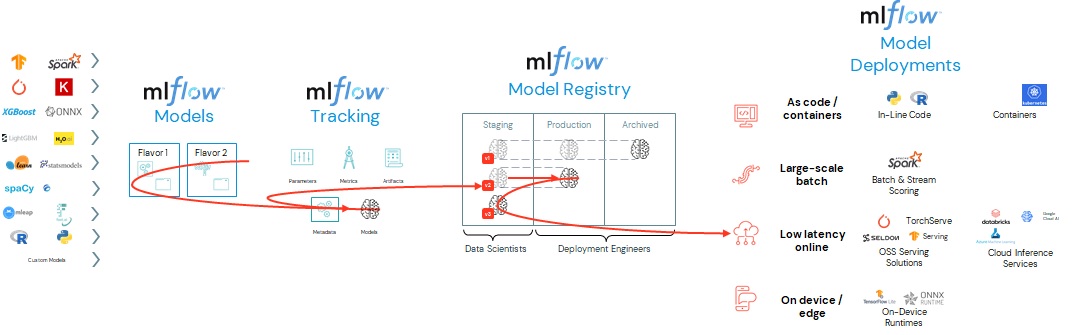
[ MLflow guide ]
– MLflow는 엔드 투 엔드 머신 러닝 라이프 사이클을 관리하기 위한 오픈 소스 플랫폼입니다.
(ML 모델을 개발의 생명주기에서 모델, 피처, 평가지표를 효율적으로 관리할수 있도록 지원하는 오픈소스 MLOps프레임워크)
– Mlflow는 특정 ML 프레임워크에 종속되지 않고 SparkML, ScikitLearn, XGBoost 등 다양한 프레임워크의 ML관리를 지원합니다.
– Databricks는 MLflow의 Tracking Server를 관리형 서비스로 제공하여 사용자가 별도로 서버를 운영 및 관리할 필요가 없읍니다.
– Databricks Notebook을 통합하여 ML모델에서 바로 해당되는 Notebook 확인이 가능합니다.
– Unity Catalog와의 통합으로 모델의 접근에대한 권한제어를 통해 모델 거버넌스가 보장됩니다.
주요 구성 요소는 다음과 같습니다.
– Tracking: 실험을 추적하여 매개변수와 결과를 기록하고 비교할 수 있습니다. MLflow Tracking 구성요소는 API(JAVA, Python, R, REST)을 이용하며 머신 러닝 트레이닝 세션(runs)을 기록하고 쿼리할 수 있습니다. MLflow ‘run’ 은 기계학습 훈련 프로세스와 관련된 parameters, metrics, tags, 및 artifact의 모음입니다.
– Models: 다양한 ML 라이브러리에서 다양한 모델 서빙 및 추론 플랫폼으로 모델을 관리하고 배포할 수 있습니다.
– Projects: ML 코드를 재사용 가능하고 재현 가능한 형태로 패키징하여 다른 데이터 과학자와 공유하거나 프로덕션으로 이전할 수 있습니다.
– Model Registry: 모델 스토어를 중앙 집중화하여 모델의 전체 라이프사이클 단계 전화(스테이지에서 프로덕션까지)을 관리할 수 있으며, 버전화 및 주석화 기능을 사용할 수 있습니다. 데이터브릭스는 Unity Catalog에서 모델 레지스트리의 관리되는 버전을 제공합니다.
– Model Serving: MLflow Model들을 REST 엔드포인트로 호스팅할 수 있습니다.
Databricks는 엔터프라이즈 보안기능, 고가용성, 및 데이터브릭스 워크스페이스(experiment, run management, notebook revision capture등) 기능이 통합된 완전히 관리되고 호스팅되는 MLflow 버전을 제공합니다. MLflow on Databricks는 머신러닝 모델 training 실행, 머신러닝 프로젝트 실행을 추적 및 secure하기 위한 통합된 경험을 제공합니다.
MLflow 데이터는(experiment runs, metrics, tags and params) 데이터브릭스 환경의 control plane에 저장이 되며, 플랫폼 관리 키를 사용하여 암호화되어 있습니다. 반면에, 루트 스토리지(DBFS)에 저장이 되는 models, artifact는 자체키를 사용하여(작업공간 스토리지에 대한 고객관리 키)하여 암호화할 수 있습니다.
[ What are experiments in MLflow? ]
– Experiments는 MLflow에서 조직의 기본 단위이며, 모든 MLflow 실행은 experiment에 속합니다. 각 실험을 통해서 runs를 시각화, 검색, 비교할 수 있을 뿐만 아니라 다른 툴에서 분석을 위해 run artifact나 metadata를 다운로드할 수 있습니다. Experiment는 데이터브릭스에서 호스팅하는 MLflow tracking server에서 관리되어집니다.
– 실험은 워크스페이스의 파일 트리로 보여집니다. 폴더, 노트북, 라이브러리 등 다른 작업공간 개체를 관리하는 것과 동일한 도구를 사용하여 관리되고 있습니다.
[ Databricks Data Intelligence Platform]

– 2023년 Databricks는 Moraic AI 를 인수하면서 제품군에 AI 모델 운영의 간소화와 민감한 데이터를 위한 Private AI 모델 생성을 위한 AI 플랫폼인 Databricks Data Intelligence Platform 도입했습니다..
– 모든 데이터를 위한 개방적이고 통합된 기반 플랫폼인 Data Lakehouse에 쉽게 확장 가능하고 쉽게 데이터와 AI를 활용하여 모델 생성이 가능한 AI 환경인 Generative AI을 첨가해서 모든 Data + AI 작업이 가능한 플랫폼인 Databricks Data Intelligence Platform을 만들었습니다.
[ 맺음말 ]
우리는 총 여섯 차례에 걸쳐서 Databricks와 Lakehouse Platform에 대해서 알아보았고 Lakehouse의 근간을 이루는 Delta Lake 및 Unity Catalog에 대한 기본 개념을 파악했으며, 그 위에서 작업할 수 있는 Data warehousing, Data engineering, Data science and ML 워크로드에 대해서 학습했습니다. 하나의 플랫폼에서 Data warehouse의 기능과 Data lake의 기능을 통합한 Lakehouse Platform으로 Native Cloud Storage 와 Computing 자원을 사용해서 모든 Persona별 작업이 가능한 플랫폼이 있다는 것을 확인했습니다.

이제 우리는 기본 이론에 첨가된 각 실습을 해봐야 할 것입니다. 이 과정은 문서를 참조해서 진행해보시면 많은 도움이 될 것입니다.
실습환경은 크게 2가지로 접근이 가능합니다.
1) Community Edition : 완전무료버전(databricks 및 cloud 비용 무료)이나 기능제한이 있음. Single node Cluster Only, Job Cluster사용 불가, Databricks SQL 사용 불가, 권한제어 불가 등.
2) Trial Edition: 14일 동안 Databrick 무료 사용, Cloud Provider 비용은 고객 지불, 전체 기능 사용 가능.
[참조 문서]
1) Databricks documentation: https://docs.databricks.com/en/index.html (각 클라우드 엡체에 따라 별도의 문서 존재, AWS, Azure, Google Cloud)
2) Databricks Demo Hub: https://www.databricks.com/resources/demos (노트북, 비디오, eBook)
3) Databricks Academy: https://www.databricks.com/learn/training/home (skill set)
4) Databricks Community: https://community.databricks.com/ (문제 및 이슈에 대한 공유)
5) Databricks Labs: https://www.databricks.com/learn/labs (현장의 프로젝트)
6) Databricks customers: https://www.databricks.com/customers (산업 군별 고객 use case)