1. Databricks와 Lakehouse Platform
4. Databricks Data Engineering Workload
5. Databricks Data Warehousing Workload
6. Databricks Data Science and ML Workload

오늘은 Databricks 다섯 번째 시간으로 Databricks Data warehouse에 대해서 알아보겠습니다.
Data warehouses는 주로 과거에 발생한 정형데이터 이용해서 의사결정을 하거나 insight를 도출하는데 이용이 되었습니다.
하지만 SQL이외의 언어와 비정형 데이터, 머신 러닝, IoT 및 스트리밍 분석이 급증함에 따라 조직은 분리된 별도의 시스템을 채택해야 했습니다 (BI을 위해서는 Data warehouse를 ML 및 AI를 위해서는 Data Lake를 사용함)
SQL는 수백만명의 전문가들에게 의해서 널리 알려졌지만 data lake는 lakehouse 이전 까지는 잘 알려지거나 언급된 경우가 드뭅니다.
[ What is Databricks data warehousing ]
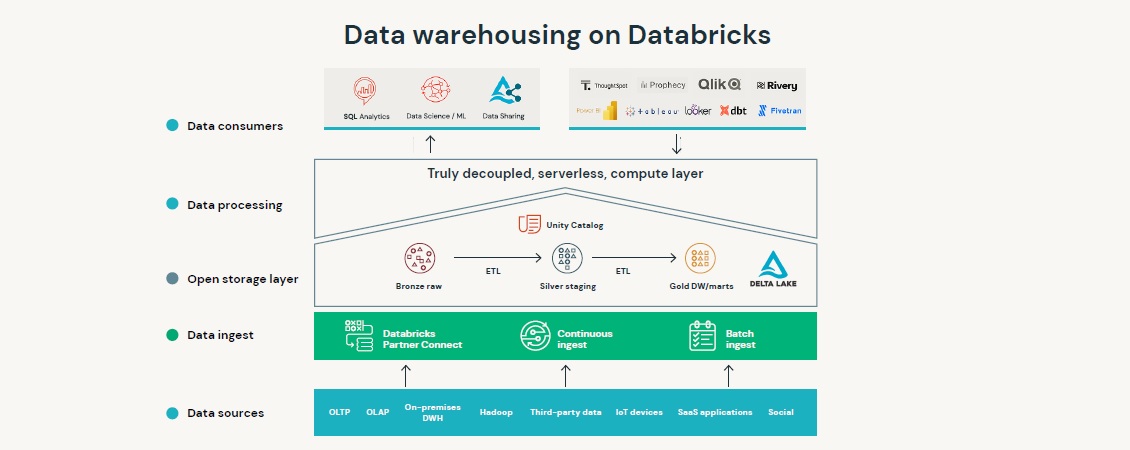
– 데이터브릭스 레이크하우스 플랫폼은 데이터 웨어하우스 워크로드를 위한 단순화된 멀티클라우드 및 서버리스 아키텍처를 제공합니다.
– 레이크하우스의 데이터 웨어하우징은 공통 거버넌스 모델(Unitiy Catalog)을 통해 규모에 맞는 SQL 분석 및 BI가 가능합니다.
– SQL이나 선택한 BI 툴을 사용하여 모든 데이터를 하나의 플랫폼내에서 수집, 변환, 쿼리하여 최고의 가격 대비 성능으로 실시간 비즈니스 통찰력을 제공할 수 있습니다.
– 개방형 표준 및 API를 기반으로 구축된 레이크하우스는 데이터 레이크가 기본적으로 부족한 안정성, 품질, 성능을 제공합니다. 에코시스템과의 통합을 통해서 최대의 유연성도 제공합니다.
[ Key benefits ]
1) Best price/performance: 비용절감 및 가격대비 성능 확보, 리소스 관리 오버헤드 제거
– 기존의 데이터 웨어하우스는 점점 증가하는 데이터 양을 처리하기 위해 물리적으로 확장하기가 쉽지 않고, 끊임없이 변화하는 비즈니스 요구에 대응하는 데 필요한 탄력성을 제공하는 데 한계에 도달했습니다.
– 클라우드 데이터 웨어하우스는 온프레미스 데이터 웨어하우스를 대체할 수 있는 훌륭한 대안으로, 더 큰 규모와 탄력성을 제공하지만, 독점 클라우드 데이터 웨어하우스의 클라우드 비용은 일반적으로 데이터 볼륨이 증가함에 따라 기하급수적으로 비용이 증가합니다.
– Databricks Lakehouse 플랫폼은 즉각적이고 탄력적인 SQL 서버리스 컴퓨팅 제공합니다. 저렴한 오브젝트 저장소의 스트리지와 분리된 컴퓨팅 자원을 사용하고 수천개의 성능 최적화 기능을 제공하여 전체 인프라 비용을 약 40% 절감할 수 있습니다.
– Databricks는 기존 클라우드 데이터 웨어하우스보다 최대 12배 우수한 가격 대비 성능을 제공하는 인스턴스 유형 및 수성을 자동으로 결정하고 동시작업 진행시에는 사례에 맞게 확장합니다.
2) Built-in governance: 모든 데이터 팀에서 One source of thuth 와 통합된 거버넌스 사용

– Delta Lake를 기반으로 하는 Databricks Lakehouse 플랫폼은 기존 데이터 레이크에서 발생하는 데이터 이동 및 본사본을 생성하지 않고 모든 데이터의 단일 본사본을 구축하여 아케텍처를 단순화할 수 있습니다.
– Databricks Unity Catalog와 원활한 통합을 통해서 세분화된 거버넌스, 데이터 리니지, 표준 SQL을 통해 모든 데이터를 쉽게 검색하고, 권한부여 및 관리가 가능합니다.
3) Rich ecosystem: 선호하는 tool을 사용하여 모든 데이터를 현재위치에서 수집, 변환, 쿼리가능
– 데이터레이크에서 BI를 수행하는 도구는 거의없습니다. 일반적으로 데이터 분석가가 Spark job을 submit 하거나 개발자 인터페이스를 사용해야 했습니다.
– 이러한 툴들은 데이터 과학자에게는 일반적이지만 데이터 분석가 사용하는 툴에는 포함되지 않아 별도의 언어 및 인터페이스에 대한 지식이 필요했습니다. 데이터 웨어하우스에 대해 잘 구축된 도구와 방법이 이미 존재하는 경우 분석가가 데이터 레이크를 활용하기 위해서는 학습해야할 요소가 너무 많았습니다.
– Lakehouse 플랫폼은 dbt, Fivetran, Power bI 또는 Tableau와 같이 선호하는 도구화 함께 작동하므로 분석가 및 엔지니어는 별도의 데이터 웨어하우스로 이동할 필요 없이 최신의 완전한 데이터를 쉽게 수집, 변환, 쿼리할 수 있습니다.
– 모든 분석가가 내장된 SQL편집기, 시각화, 대쉬보드를 통해 새로운 Insight를 빠르고 협력적으로 찾아서 공유할 수 있습니다.
4) Break down silos: 원시데이터에서 실행 가능한 데이터까지의 시간을 단축하고 BI에서 ML까지 간편하게 사용
– 기존의 데이터 웨어하우스는 실시간 처리가 부족하고 대규모의 ETL 작업에 적합한 확장이 불가능하기 때문에 데이터 엔지니어링 팅에 새로운 데이터 이동과 병목 현상을 발생 시켜도 분석가가 최신 상태의 데이터에 대한 접근을 느리게 만듭니다.
– Advanced Anaytics 애플리케이션(ML)의 경우 SQL 전용데이터 웨어하우스와는 전혀 다른 시스템을 관리해야 하므로 협업 및 혁신의 속도가 느려집니다.
– Databricks Lakehouse 플랫폼은 최신분석 요구사항 등을 모두 충족하는 완벽한 엔드 투 엔드 데이터 웨어하우징 솔루션을 제공하므로, 데이터 팀과 비즈니스 사용자가 실시간 분석을 위해 최신데이터에 빠르게 액세스하고 BI에서 ML로 쉽게 이동할수 있습니다.
[ What is serverless compute? ]
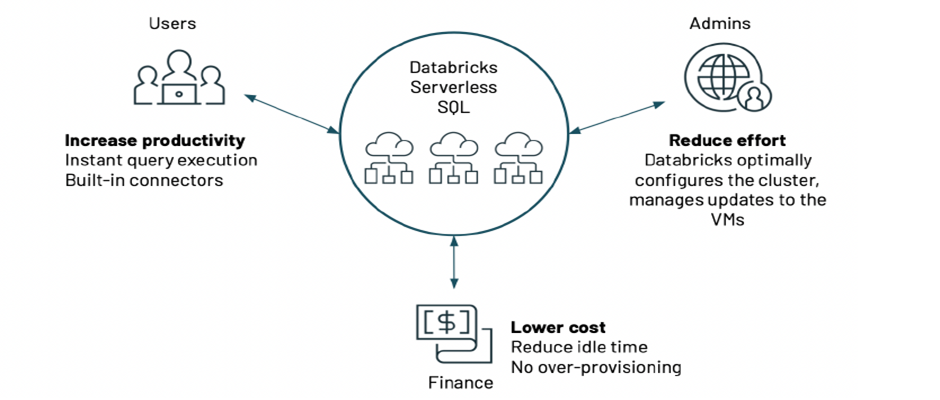
– 서버리스 컴퓨팅은 고객 계정 대신 데이터브릭스 클라우드 계정에서 고객을 대신해서 컴퓨팅 레이어를 프로비저닝하고 관리하는 완전 관리형 서비스입니다.
– 현재 릴리스에서는 서버리스 컴퓨팅이 Databricks SQL과 함께 사용이 가능합니다. BI 및 SQL 워크로드에 대해 즉각적인 컴퓨팅 리소스를 제공하며, 최소한의 관리 필요성과 용량 최적화를 전체 비용을 평균 20%~40% 절감 할수 있습니다.
[ Benefits of Databricks Serverless SQL ]
– 서버리스 SQL은 Databricks가 클러스터 VM의 구축, 구성 및 관리를 담당하므로 관리가 훨씬 간편합니다. 데이터브릭스는 일반적으로 15초 만에 사용자 쿼리에 컴퓨팅 용량을 전송할 수 있으므로 쿼리 실행을 위해 클러스터가 시작되거나 스케일 아웃될 때 까지 기다릴 필요가 없습니다.
– 서버리스 SQL에는 Tableau, Power BI, Qlik 등과 같은 좋아하는 도구에 대한 커넥터도 내장되어 있습니다. 이 커넥터에는 간편한 인증 지원과 고성능을 위해 최적화된 JDBC/ODBC 드라이버를 사용합니다.
– idle 용량에 대해 초과 프로비저닝 하거나 비용을 지불 할 필요가 없으므로 비용을 절감할 수 있습니다.
[ Inside Serverless SQL ]
– 서버리스 SQL의 핵심에는 사용자에게 몇 초 안에 할당할 수 있는 Kubernetes 컨테이너를 실행하는 Databricks의 계정에 있는 서버풀을 운영하는 컴퓨팅 플랫폼입니다.
– 여러 사용자가 report or 쿼리를 실행하는 경우 동시에 컴퓨팅 플랫폼은 동시 부하를 처리하기 위해 더 많은 클러스터를 추가 합니다. (몇 초 안에)
– 데이터브릭스는 서버의 전체 구성을 관리하고 필요에 따라 패치 및 업그레이드를 자동으로 수행합니다.
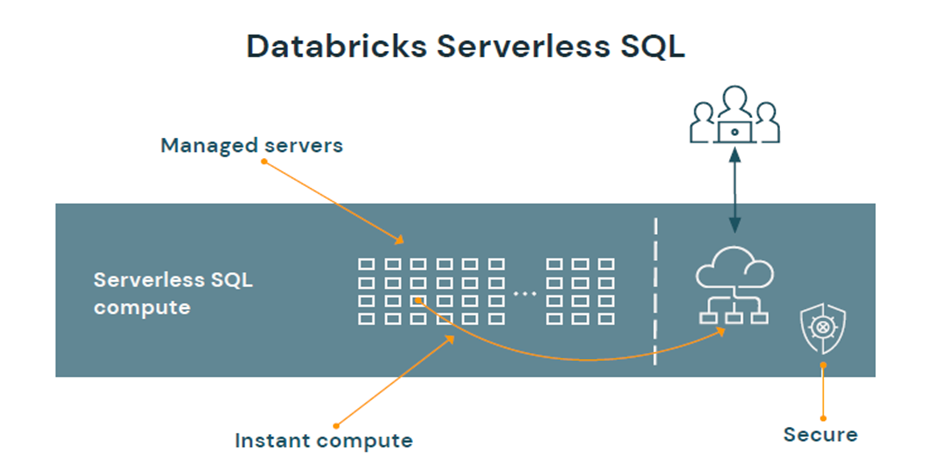
– 각 서버는 secure한 보안 구성을 실행하고 있으며, 모든 프로세싱은 세 가지 격리 layer에 의해서 보호됩니다. 각 계층은 공유 또는 네트워크 간 트래픽이 허용되지 안는 상태에서 하나의 워크스페이스로 격리됩니다. 컨테이너는 강화된 환경구성을 사용하고 VM은 종료되고 재사용 되지 않으며, 네트워크 트래픽은 동일한 클러스터의 노드들로 제한됩니다.
a. 런타임을 호스팅하는 kubernetes 컨테이너
b. 컨테이너를 호스팅하는 가상머신(VM)
c. 작업 공간에 대한 가상 네트워크
[ Performance of Serverless SQL]
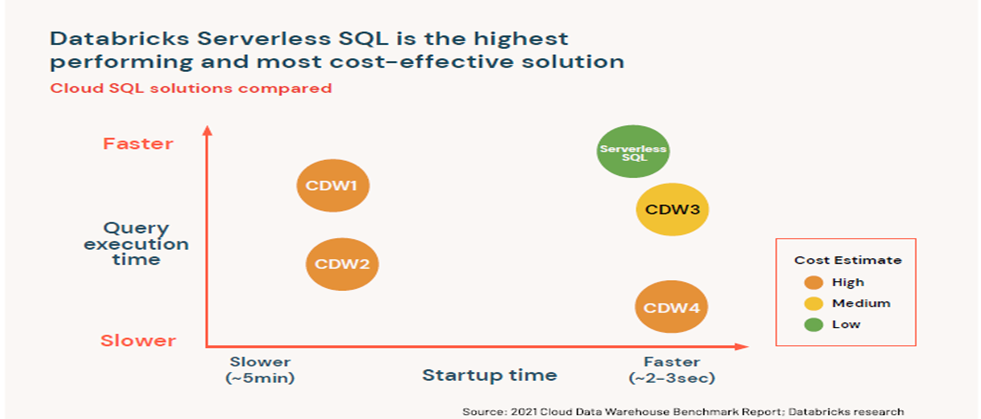
현재의 Databricks Serverless SQL과 전통적인 Cloud Data warehouses의 성능 비교를 해보면 아래의 그림에서 나타나듯이 클러스터의 시작시간, 쿼리실행 시간 및 전체 비용을 고려할 때 서버리스 SQL이 SQL 워크로드를 실행하는데 가장 비용 효율적이고 성능이 뛰어난 환경임을 확인 할 수 있습니다.
Databricks Datawarehouse에 대해서 알아보면서 다시한번 Data warehouse, Data Lake, Data lakehouse에 대한 기본적인 특징을 정리해보겠습니다

데이터 레이크하우스 아키텍처는 데이터 웨어하우시 시장 초기에 볼 수 있었던 것과 비슷한 기회를 제공합니다. 개방형 환경에서 데이터를 관리하고, 기업의 모든 부분에서 데이터사이언스 포커스와 데이터 웨어하우스의 사용자 분석을 결합하여 모든 데이터에 다양한 워크로드 작업이 가능한 플랫폼이 될것입니다.
이번시간에는 Data Analysist에게 작업하는 환경을 제공하는 Databricks data warehousing에 대한 기본적인 특징을 알아보았습니다. 다음에는 Data Scientist관점에서 ML환경 및 라이프사이클을 제공하는 Databricks Data Science and ML Workload에 대해서 알아보도록 하겠습니다.
[참고 문헌]
[1] Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia,Lakehouse: https://www.databricks.com/research/lakehouse-a-new-generation-of-open-platforms-that-unify-data-warehousing-and-advanced-analytics
[2] Bill Inmon, Ranjeet Srivastava, Rise of the Data Lakehouse
[3] Databricks, The Big Book of Data Engineering
[4] Databricks, The Data Team’s Guide to the Databricks
[5] Databricks Documentation, https://docs.databricks.com/en/index.html
[6] Databricks Homepage, https://www.databricks.com
[7] Databricks Blog, https://www.databricks.com/blog