
I. 서론
소프트웨어 품질관리는 오늘날 IT 산업에서 필수적인 요소이다. 신뢰성, 효율성, 유지보수성 등 다양한 품질 속성을 확보하기 위해서는 체계적이고 지속적인 관리가 중요한데, 이러한 상황에서 AI 기술의 발전은 소프트웨어 품질관리 방식을 혁신적으로 변화시키고 있다
본 글에서는 AI를 활용한 소프트웨어 품질관리 기법에 대해 설명해 보고자 한다.
II. 본론
1. AI를 활용한 테스트 자동화
전통적인 테스트 방식에서 자동화는 반복적이고 시간이 많이 소요되는 작업이지만, AI 기술을 활용하게 되면 테스트 시나리오를 자동으로 생성하고 실행할 수 있어 업무의 효율성을 높일수 있다
<AI 기반 테스트 자동화의 주요 요소>
1) 테스트 케이스 생성 및 유지보수 자동화
– 테스트 케이스 생성: AI 알고리즘을 이용하여 소프트웨어의 다양한 시나리오를 생성하고, 이러한 시나리오에 맞는 테스트 케이스를 자동으로 생성할 수 있다.
– 테스트 스크립트 유지보수: AI는 코드 변경 사항을 감지하고, 이에 따라 테스트 스크립트를 자동으로 업데이트 함으로써 코드 변화에 따라 발생할 수 있는 테스트 스크립트의오류를 최소화 할 수 있다.
2) 테스트 실행 최적화
– 우선순위 지정 : AI는 소프트웨어 변경 사항에 따라 테스트 케이스의 우선순위를 지정하여, 가장 중요한 테스트를 먼저 실행하도록 할 수 있다.
– 병렬 테스트 실행: 머신러닝 알고리즘을 사용하여 테스트를 병렬로 실행함으로써 전체 테스트 시간을 단축 시킬 수 있다.
3) 결과 분석 및 문제 예측
– 테스트 결과 분석: AI는 테스트 실행 결과를 분석하고, 패턴을 식별하여 잠재적인 문제를 예측할 수 있으며, 이는 문제 해결 시간을 단축하는 데 도움을 준다.
– 자동 버그 분류 및 보고: AI는 버그를 자동으로 분류하고, 관련 정보를 바탕으로 상세한 버그 리포트를 생성할 수 있다.
(사례 1: 구글의 AI 테스트 시스템) 구글은 AI를 활용하여 구글 검색 엔진의 다양한 기능을 테스트한다. 구글은 머신러닝 모델을 사용하여 사용자 검색 패턴을 분석하고, 이를 기반으로 다양한 시나리오에서 검색 결과의 정확성을 테스트 한다. 이를 통해 구글은 사용자 경험을 지속적으로 개선할 수 있다.

[그림 1] Google Rank Brain 소개 (출처 : Google Blog)
(사례 2: 아마존의 리테일 웹사이트 테스트) 아마존은 AI 기반 테스트 자동화 도구를 사용하여 웹사이트의 기능을 테스트 한다. AI는 사용자 행동 데이터를 분석하여, 다양한 사용자 시나리오에 맞춘 테스트 케이스를 생성하고, 이를 자동으로 실행한다. 또한, AI는 테스트 결과를 분석하여, 잠재적인 문제를 사전에 예측하고 해결할 수 있도록 지원한다.

[그림 2] AWS(Amazon Web Services)의 생성형 AI 스택(출처 : Amazon Blog)
(사례 3: 페이스북의 코드 변경 테스트) 페이스북은 코드베이스의 대규모 변경 사항을 효율적으로 테스트하기 위해 AI를 활용한다. AI 시스템은 코드 변경 사항을 분석하고, 이에 따라 필요한 테스트 케이스를 자동으로 생성 및 실행한다. 또한, 테스트 결과를 실시간으로 분석하여, 문제를 신속하게 식별하고 해결할 수 있도록 지원한다.
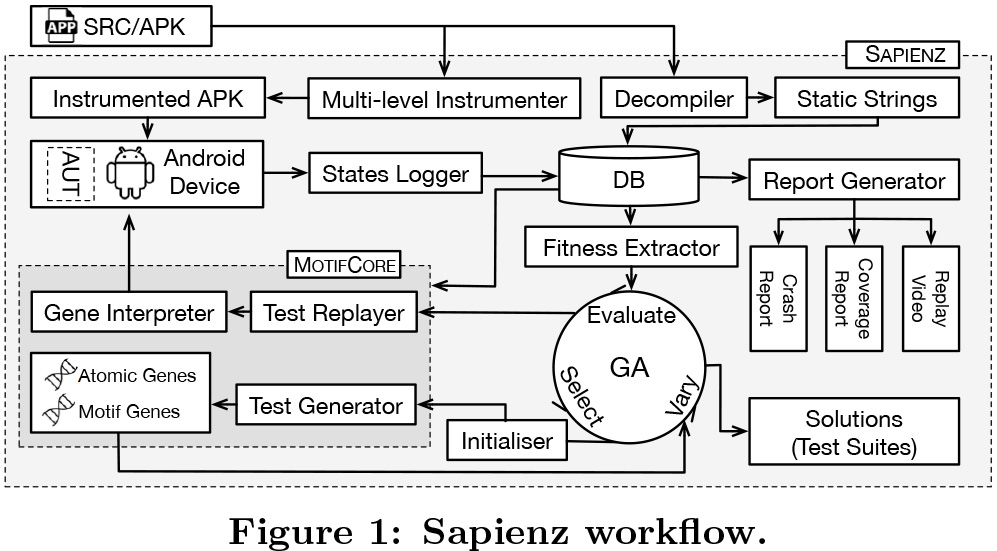
[그림 3] 페이스북 Sapienz의 워크플로우를 설명하는 다이어그램(출처 : Facebook Blog(Sapienz)
2. 머신러닝을 이용한 결함 예측 및 분석
머신러닝은 결함 예측 및 분석에도 효과적으로 활용될 수 있다.즉, 과거의 결함 데이터를 분석하여 결함 발생 패턴을 학습하고, 이를 바탕으로 새로운 소프트웨어 버전에서 발생할 수 있는 잠재적 결함을 예측할 수 있다. 이를 통해 결함이 발생하기 전에 예방적 조치를 취할 수 있도록 함으로써 소프트웨어 품질을 크게 향상시킬 수 있다.
<주요 개념 및 절차>
1) 데이터 수집:
– 과거 결함 데이터: 버그 리포트, 코드 리포지토리, 테스트 결과 등의 데이터를 수집함.
– 코드 메트릭스: 코드의 복잡도, 코드 변경 빈도, 코드 리뷰 기록 등의 메트릭스를 수집함.
2) 데이터 전처리:
– 결측값 처리: 누락된 데이터를 보완.
– 데이터 정규화: 데이터의 스케일을 일관되게 조정.
– 피처 엔지니어링: 머신러닝 모델의 성능을 향상시키기 위해 유의미한 피처를 생성함.
3) 모델 훈련:
– 분류 모델: 결함이 발생할 확률을 예측하기 위해 분류 모델(예: 로지스틱 회귀, 랜덤 포레스트, XGBoost 등)을 사용.
– 회귀 모델: 결함의 심각도를 예측하기 위해 회귀 모델을 사용.
– 클러스터링: 결함의 유형을 그룹화하기 위해 클러스터링 알고리즘을 사용.
4) 모델 평가:
– 정확도(Accuracy): 모델의 전체 예측 정확도를 평가.
– 정밀도(Precision)와 재현율(Recall): 결함 예측의 정확성과 탐지율을 평가.
– F1 점수: 정밀도와 재현율의 조화 평균을 계산하여 모델의 성능을 평가.
5) 모델 배포 및 사용:
– 실시간 예측: 새로운 코드 변경 사항에 대해 결함 발생 가능성을 실시간으로 예측함.
– 결함 분석: 예측된 결함의 원인을 분석하고, 개발자에게 피드백을 제공.
(사례 1: 마이크로소프트) 마이크로소프트는 코드 결함 예측을 위해 머신러닝을 활용함. 마이크로소프트의 연구팀은 버그 예측 모델을 개발하기 위해 코드 변경 기록, 코드 복잡도, 과거 결함 데이터를 사용 함. 이를 통해 고위험 코드 변경 사항을 사전에 식별하고, 개발 팀이 사전에 문제를 해결할 수 있도록 지원한다
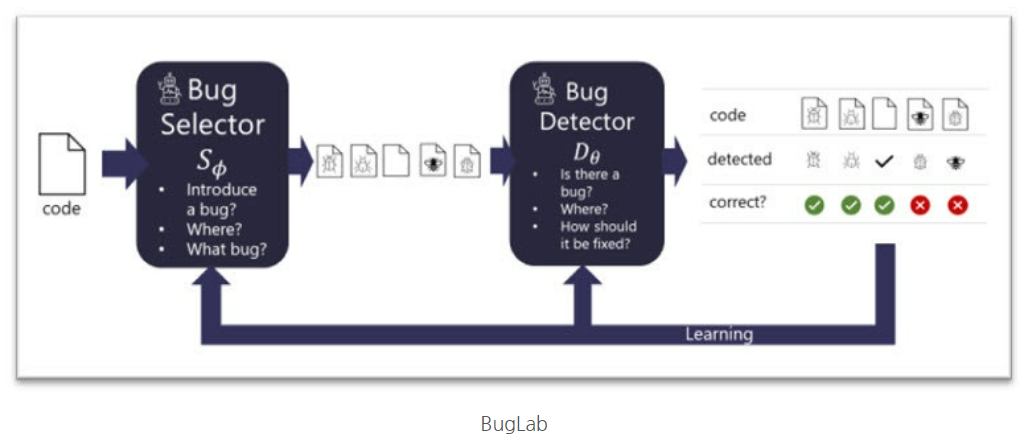
[그림 4] AI 기반의 버그 탐지 및 수정 도구인 BugLab의 동작 과정 설명 다이어그램(출처 : Microsoft Blog)

[그림 5] Microsoft Azure에서 제공하는 주요 AI 서비스(출처 : Microsoft Blog)
(사례 2: 넷플릭스) 넷플릭스는 대규모 분산 시스템에서 결함을 예측하기 위해 머신러닝을 사용합니다. 넷플릭스는 로그 데이터와 시스템 메트릭스를 분석하여, 서비스 장애를 예측하고, 잠재적인 문제를 사전에 경고한다. 이를 통해 넷플릭스는 서비스 중단을 최소화하고, 사용자 경험을 개선할 수 있었음

[그림 6] Netflix가 개발한 분산 시스템에서 장애를 격리하고 복구할 수 있도록 도와주는 도구인 Hystrix(출처 : Netflix Blog)
(사례 3: IBM) IBM은 소프트웨어 결함 예측을 위해 다양한 머신러닝 모델을 적용함. IBM의 연구팀은 결함 데이터와 코드 메트릭스를 분석하여, 결함이 발생할 가능성이 높은 코드를 사전에 식별 함. 이 접근 방식은 소프트웨어 유지보수 비용을 절감하고, 소프트웨어 품질을 향상시키는 데 기여 함

[그림 7] IBM에서 개발한 인공지능(AI) 플랫폼 왓슨(출처 : IBM Blog)
3. 자연어 처리(NLP)를 이용한 코드 리뷰 자동화
코드 리뷰는 소프트웨어 개발 과정에서 중요한 단계 중 하나이다. 자연어 처리(NLP) 기술을 활용하면 코드 리뷰 과정을 자동화할 수 있다. AI 모델은 코드의 주석이나 문서화된 내용을 분석하여 코드의 품질을 평가하고, 코드 스타일, 보안 취약점 등을 자동으로 검토할 수 있다. 이는 코드 리뷰 과정의 효율성을 높이고, 개발자들의 부담을 줄여 줄 수 있을 것이다.
주요 개념 및 절차
1) 코드 이해 및 분석:
– 코드 파싱: NLP 기술을 사용하여 코드를 분석하고, 구조적 요소(함수, 변수, 클래스 등)를 이해.
– 문맥 이해: 코멘트와 코드의 문맥을 파악하여, 코드가 의도한 대로 동작하는지 확인 함.
2) 리뷰 템플릿 및 규칙 생성:
– 스타일 가이드: NLP를 통해 회사 또는 프로젝트의 코딩 스타일 가이드를 학습하고, 이를 기반으로 코드의 스타일을 자동으로 검토 함.
– 베스트 프랙티스: 코드 리뷰에서 자주 발견되는 패턴과 베스트 프랙티스를 학습하여, 자동으로 이러한 규칙을 적용 할수 있음.
3) 자동 피드백 생성:
– 버그 탐지: 코드에서 잠재적인 버그를 탐지하고, 이를 설명하는 피드백을 자동으로 생성.
– 개선 제안: 코드의 성능이나 가독성을 높일 수 있는 개선점을 제안할수 있음.
4) 지속적인 학습 및 개선:
– 리뷰 결과 학습: 과거 코드 리뷰 데이터를 학습하여, 더 정확하고 유용한 피드백을 제공할 수 있도록 모델을 지속적으로 개선한다.
– 사용자 피드백 반영: 개발자들의 피드백을 반영하여, 모델의 성능을 향상시킬수 있음.
(사례 1: Facebook의 SapFix) Facebook은 SapFix라는 도구를 개발하여, 코드 리뷰 및 버그 수정을 자동화 함. SapFix는 코드를 분석하고, 잠재적인 버그를 발견하여 자동으로 수정 패치를 생성함. 이는 개발자들이 코드 리뷰 과정에서 발견할 수 있는 일반적인 문제들을 사전에 해결하는 데 도움을 줄 수 있음
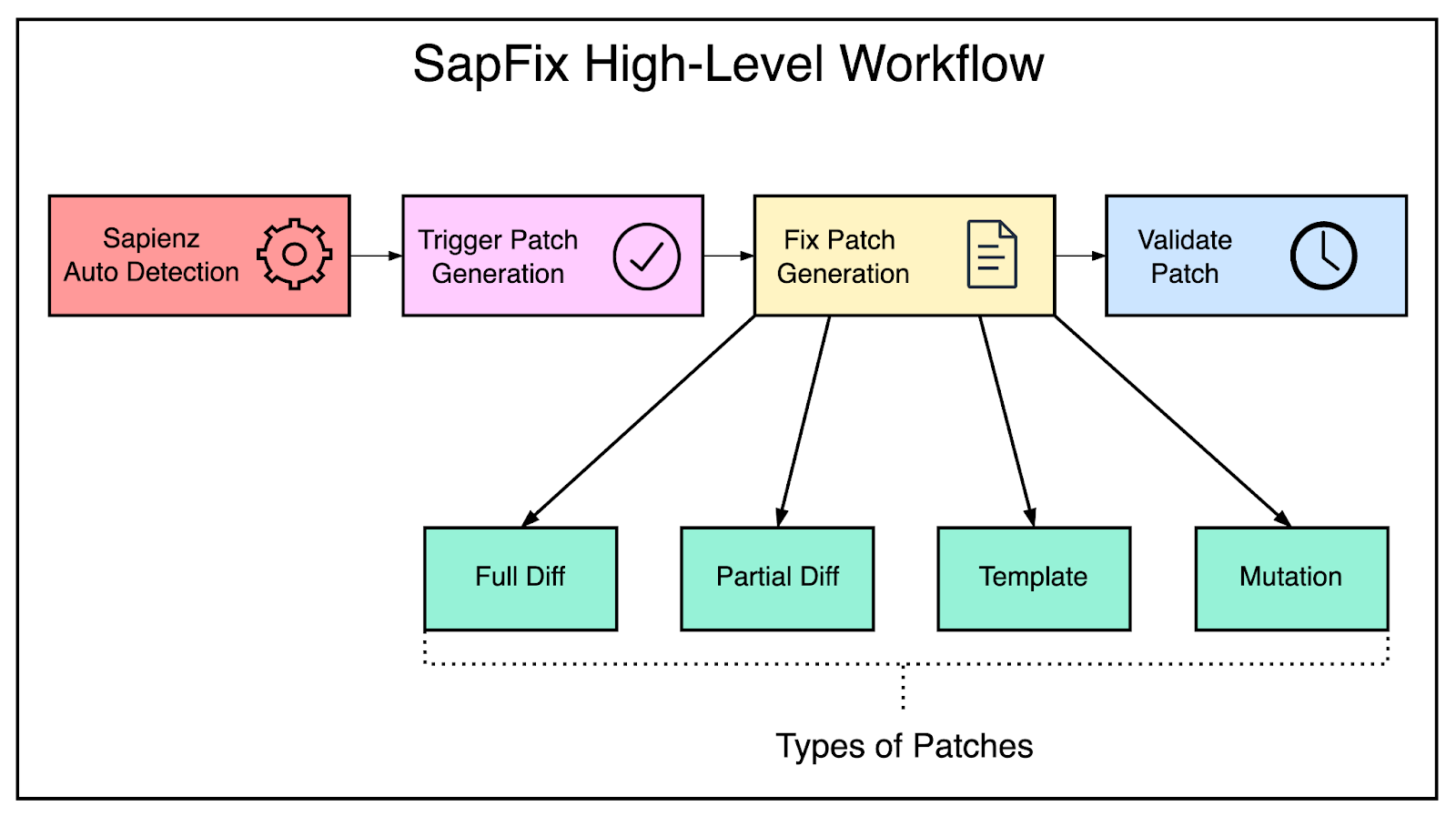
[그림 8] Facebook이 개발한 자동화된 버그 수정 도구인 SapFix의 상위 수준 워크플로우(출처 : Facebook blog)
(사례 2: GitHub의 코드스캔) GitHub는 CodeQL이라는 코드 분석 도구를 통해 코드 리뷰 자동화를 지원. CodeQL은 코드를 쿼리하고, 잠재적인 보안 취약점과 버그를 탐지하고 이를 통해 개발자들은 코드 리뷰 과정에서 이러한 문제를 자동으로 발견하고 해결할 수 있음.
[그림 9] GitHub Action을 통해 CodeScan 기능(출처 : Github)
DeepCode는 오픈 소스 프로젝트와 상용 프로젝트 모두에 적용될 수 있으며, 코드의 품질을 향상시키기 위한 자동 피드백을 제공 함. 이 도구는 코드의 잠재적인 버그와 개선점을 실시간으로 개발자에게 제안한다
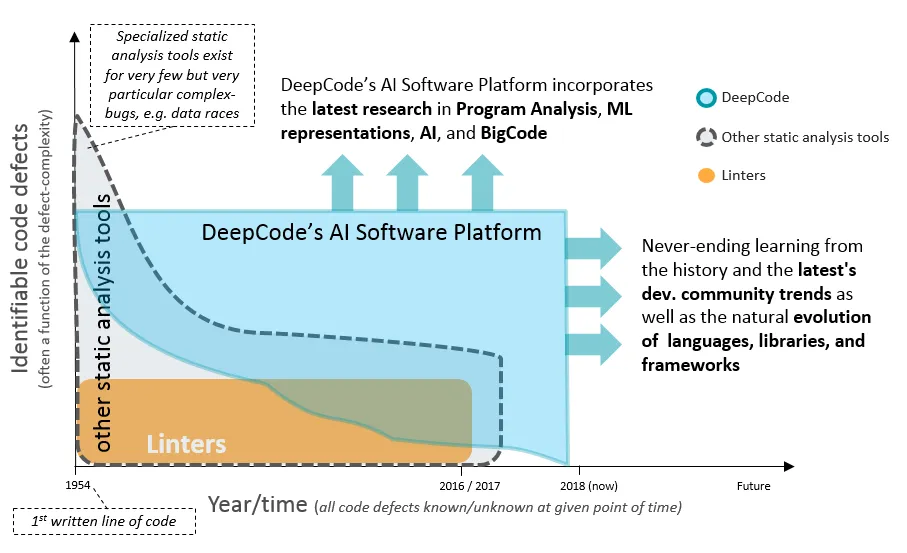
[그림 10] 정적 코드 분석 도구(Static Analysis Tools)의 진화와 기능을 비교(출처 : medium blog)
4. 지능형 버그 추적 시스템
AI 기반의 지능형 버그 추적 시스템은 버그 관리에 혁신적인 변화를 가져 왔다고 할수 있다. 이 시스템은 버그 보고서의 내용을 분석하여 버그의 우선순위를 자동으로 설정하고, 적절한 개발자에게 할당하여 처리 한다. 또한, 유사한 버그를 그룹화하여 중복된 작업을 줄이고, 버그 해결 과정을 최적화 하여 진행 할수 있다.
주요 개념 및 기능
1) 자동 버그 분류 및 우선순위 설정:
– 자연어 처리(NLP): 버그 리포트를 자동으로 분석하고, 유사한 버그를 그룹화하여 분류함.
– 우선순위 설정: 머신러닝 모델을 사용하여 버그의 심각도와 발생 빈도 등을 기반으로 우선순위를 설정. 이를 통해 개발팀이 중요한 버그를 먼저 해결할 수 있음.
2) 버그 예측 및 예방:
– 과거 데이터 분석: 과거의 버그 데이터를 분석하여 패턴을 식별하고, 유사한 상황에서 발생할 수 있는 버그를 예측 할 수 있음.
– 코드 리뷰 통합: 코드 변경 사항을 실시간으로 분석하고, 잠재적인 버그를 사전에 경고 함.
3) 자동 할당 및 추적:
– 버그 할당: AI를 사용하여 버그를 가장 적합한 개발자에게 자동으로 할당 함. 이는 개발자의 전문성과 과거 해결 경험을 기반으로 이루어짐.
– 진행 상태 추적: 버그 해결 과정을 실시간으로 모니터링하고, 프로젝트 관리 툴과 통합하여 전체 진행 상황을 추적 함.
4) 지속적인 학습 및 개선:
– 사용자 피드백 학습: 개발자와 테스터의 피드백을 반영하여 버그 추적 시스템의 성능을 지속적으로 개선 할 수 있음.
– 모델 업데이트: 새로운 버그와 해결 사례를 학습하여, 예측 모델을 지속적으로 업데이트 함.
(사례 1: JIRA with Machine Learning Integration) Atlassian의 JIRA는 전통적인 버그 추적 시스템이지만, 다양한 플러그인과 통합을 통해 AI와 머신러닝 기능을 추가할 수 있습니다. 예를 들어, 자동 분류 및 우선순위 설정을 위해 NLP와 머신러닝 모델을 통합하여, 버그 리포트를 분석하고 개발자의 작업 효율성을 높일 수 있음.

[그림 11] Atlassian Intelligence(출처 : atlassian 홈페이지)
(사례 2: Bugzilla with AI Enhancements) Bugzilla는 오픈 소스 버그 추적 시스템으로, AI 기술을 도입하여 버그 리포트의 자동 분류 및 예측 기능을 강화할 수 있음. 이를 통해 개발팀은 버그를 보다 효율적으로 관리하고, 빠르게 대응할 수 있도록 함.

[그림 12] Agility와 통합한 Bugzilla 의 결함 추적관리(출처 : Bugzilla 홈페이지)
(사례 3: Microsoft Azure DevOps) Microsoft의 Azure DevOps는 AI 기반의 버그 추적 기능을 제공하여, 코드 변경 사항을 분석하고 잠재적인 버그를 사전에 경고 함. Azure DevOps는 과거 데이터와 머신러닝 모델을 사용하여 버그의 우선순위를 자동으로 설정하여, 개발자의 효율성을 높일 수 있음.
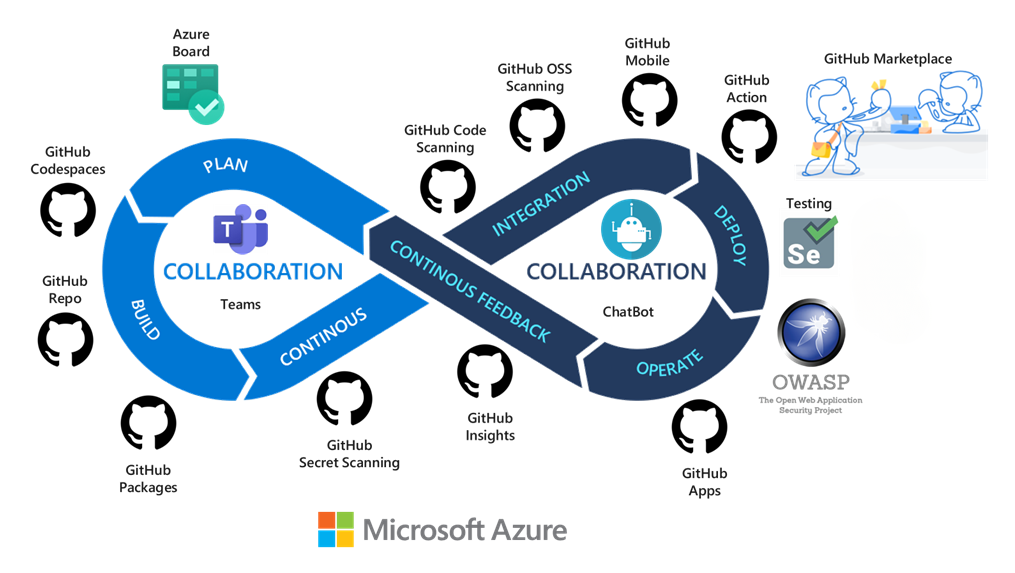
[그림 13] Microsoft Azure DevOps(출처 : Microsoft 홈페이지)
III. 결론
AI 기술 발전에 따른 소프트웨어 품질 관리의 전망
AI 기술의 발전은 소프트웨어 품질 관리에 새로운 가능성을 열어주고 있다. 테스트 자동화, 결함 예측, 코드 리뷰 자동화, 버그 추적 시스템 등 다양한 분야에서 AI는 이미 그 효과를 입증하고 있다. 앞으로 AI 기술이 더욱 발전함에 따라 소프트웨어 품질 관리의 효율성은 더욱 높아질 것이며, 이는 더 나은 소프트웨어 제품을 개발하는데 기여할 수 있을 것이다.
AI 기술을 활용한 소프트웨어 품질 관리 기법은 현재와 미래의 소프트웨어 개발에 있어 중요한 역할을 수행할 것이며, 이를 통해 소프트웨어의 품질을 향상시키고, 개발 비용과 시간을 절감할 수 있을 것이다. AI 기술을 적극적으로 도입하여 품질 관리 프로세스를 최적화하는 것이 앞으로의 경쟁력 확보에 있어 필수적인 요소가 될 수 있을 것이다.
[참고문헌]
1. 김민수. (2021). 인공지능을 활용한 소프트웨어 테스트 자동화. 소프트웨어 품질 저널.
2. 박영희. (2022). 머신러닝 기반의 소프트웨어 결함 예측 기법. IT 기술 리뷰.
3. 이철수. (2023). 자연어 처리를 이용한 코드 리뷰 자동화. 컴퓨터 과학 학술지.
4. 장혜진. (2024). AI 기반의 지능형 버그 추적 시스템 개발. 소프트웨어 엔지니어링 저널.
5. 마이크로소프트 블로그(https://www.microsoft.com/en-us/research/publication/)
6. 넷플릭스 기술 블로그(https://netflixtechblog.com/)
7. IBM 연구 블로그(https://research.ibm.com/blog)
8. 페이스북 블로그(https://developers.facebook.com/blog/)