최근 소셜 미디어에서 화제를 모은 유리 과일 ASMR 숏폼 영상을 보신 적 있으신가요? 투명한 유리로 만든 블루베리나 딸기, 수박 등을 칼로 썰면 실제 유리가 깨지는 듯한 소리와 함께 반짝이는 단면이 드러나는 이색적인 ASMR 콘텐츠입니다. 시각과 청각을 동시에 자극하는 이 몰입형 영상들은 각각 수백만에서 수천만 뷰를 기록할 정도로 폭발적인 인기를 끌고 있습니다. 놀랍게도 이 영상들은 실제 촬영이 아닌 AI가 만들어낸 가짜 영상으로, 현실에서는 불가능한 장면을 생생하게 구현해낸 사례입니다. 이러한 몰입형 콘텐츠의 유행은 생성형 비전 AI 기술이 창작의 지평을 넓히며 새로운 감각 경험을 선사하고 있음을 보여주는 흥미로운 사례입니다.
1. 생성형 비전 AI와 텍스트-투-비디오(Text-To-Video)
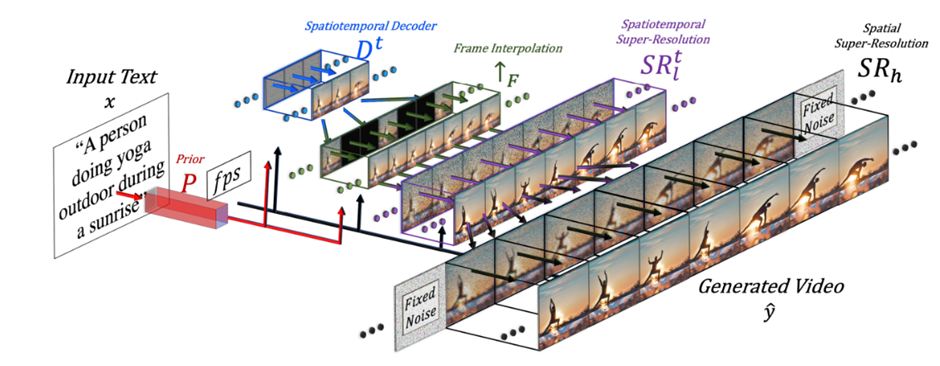
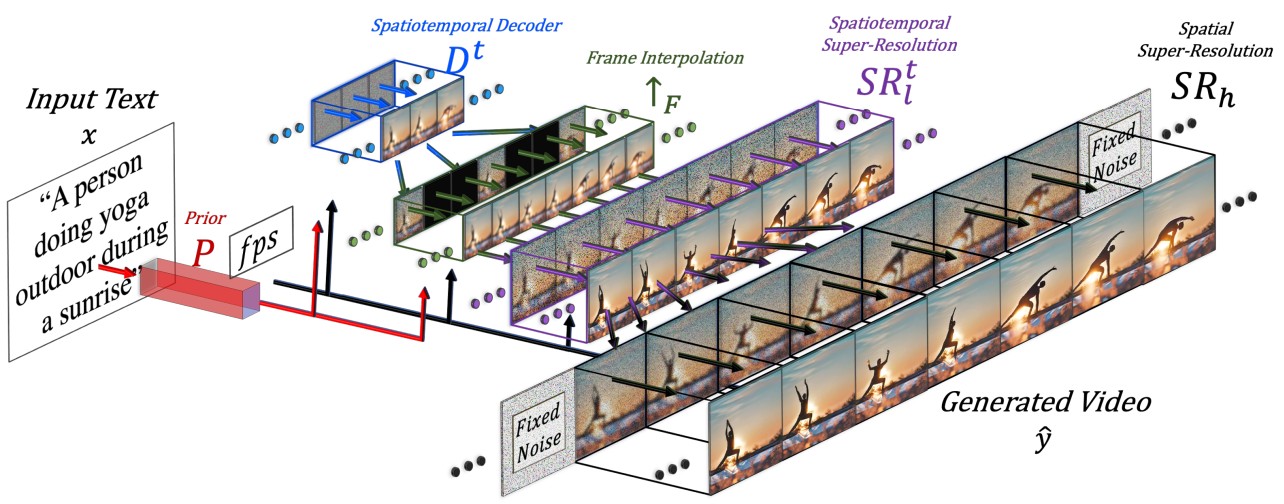
Make-A-Video Method, (사진: Make-A-Video: Text-to-Video Generation without Text-Video Data 논문 발췌)
위 사례의 이면에는 생성형 비전 AI, 그중에서도 텍스트-투-비디오(Text-To-Video)기술의 발전이 있습니다. 텍스트-투-비디오 (Text-to-Video) 모델이란 사용자가 입력한 자연어 설명을 바탕으로 그에 맞는 동영상을 자동 생성하는 AI 모델을 말합니다. 쉽게 말해, 요즘 각광받는 텍스트-투-이미지(AI 그림) 기술을 영상으로 확장한 개념입니다. 예를 들어 “우주복을 입은 사람이 우주에서 둥둥 떠있고, 뒷편에 별들이 반짝인다.”라는 텍스트를 넣으면, 그 장면에 어울리는 짧은 동영상 클립을 AI가 직접 만들어냅니다. 다음은 앞에 든 예시를 입력하여 Sora AI로 직접 생성한 5초 영상입니다.

텍스트-투-비디오(Text-To-Video) 기술은 2020년대에 들어 확산 모델(diffusion model) 등 딥러닝 기반의 이미지 생성 기법을 시간차원으로 확장함으로써 급속도로 발전해왔습니다. 초기에는 생성된 영상이 매 프레임 일관성이 떨어지거나 해상도가 낮아 실용성이 제한적이었지만, 최근 거대 IT 기업들과 연구진이 앞다투어 혁신적인 모델들을 발표하며 이런 한계를 빠르게 극복하고 있습니다. 이제는 생성형 AI가 글로 쓰여진 아이디어를 바로 고화질 영상으로 바꿔주는 시대가 성큼 다가오고 있습니다. 아래에서는 현재 주목받는 대표 텍스트-투-비디오(Text-To-Video) 모델들과 이들의 특징을 살펴보고, 최신 기술 동향과 산업 활용 사례, 그리고 개발자들이 주목해야 할 시사점을 정리해보겠습니다.
2. 대표적인 텍스트-투-비디오(Text-To-Video) 모델들
OpenAI Sora(2024)

Sora로 생성한 영상, (출처: Video generation models as world simulator, openai)
OpenAI가 2024년 말 공개한 최첨단 텍스트-투-비디오(Text-To-Video) 모델입니다. Sora는 최대 1분 길이의 영상을 사용자 프롬프트만으로 생성할 수 있을 만큼 강력한 성능을 보여주고, 시네마틱한 연출과 높은 화질로 주목받고 있습니다. DALL·E 3로 대표되는 이미지 생성 기술을 기반으로 한 Diffusion Transformer 아키텍처를 활용하여 개발되었으며, 텍스트뿐 아니라 이미지 한 장을 입력받아 이를 애니메이션화하거나 기존 짧은 영상을 이어서 확장하는 등 다양한 응용 모드도 제공합니다. 공개 당시 시연 영상에서는 컷신 전환이나 다양한 카메라 앵글 변화까지 스스로 구현해 “영상 문법”을 터득한 모습을 보여주기도 했습니다. 다만 아직 개발 중인 기술인 만큼 복잡한 물리 동작에서는 개체의 형태가 뒤틀리거나 물체가 갑자기 사라지는 등의 한계도 지적되었습니다. OpenAI는 Sora로 생성한 모든 영상에 AI 생성 표시(C2PA 메타데이터)를 심고 부적절한 프롬프트는 차단하는 등 안전장치를 함께 도입한 상태입니다.
Pika Labs(2024)

Pika Labs를 이용하여 생성한 영상, (출처: Pika Labs 인스타그램 캡쳐)
Pika Labs는 2024년 등장한 신생 스타트업의 텍스트-투-비디오(Text-To-Video) 플랫폼으로, 직관적 인터페이스와 역동적인 영상 생성으로 인기를 끌고 있습니다. 최신 버전인 Pika 2.2에서는 최대 10초 분량의 1080p 해상도 영상을 생성할 수 있고, Pikaframes라는 키프레임 전환 기능을 제공해 장면 간 부드러운 연결을 연출할 수 있습니다. 텍스트 또는 정지 이미지 입력으로부터 손쉽게 영상을 만들 수 있으며, 영상 생성 중 카메라 움직임이나 피사체 동작을 사용자가 세밀하게 조정할 수 있는 것이 장점입니다. 예를 들어 하나의 장면에서 시작해 키프레임마다 다른 장면이나 각도로 전환하는 식으로, 사용자가 스토리를 설계하며 AI 영상을 만들 수 있습니다. 이 밖에도 영상 내 객체를 다른 이미지로 교체하거나 지우는 비디오 인페인팅 기능(PikaSwaps)과, 생성 영상의 캐릭터나 오브젝트에 간단한 애니메이션 효과를 입히는 PikaTwists 등 영상 편집에 가까운 고급 기능도 갖추고 있습니다. 베타 버전임에도 불구하고 이러한 사용자 친화적 기능 덕분에 크리에이터 커뮤니티에서 활발히 활용되고 있으며, 향후 더 긴 영상 생성과 안정적 품질을 목표로 발전하고 있습니다.
Runway Gen(2023)

Runway Gen-3 모델로 생성한 영상, (출처: Runway)
Runway ML은 영상 생성 AI를 상용화한 대표적인 플랫폼입니다. 2023년 선보인 Runway Gen-2 모델은 텍스트, 이미지, 또는 기존 비디오 클립을 입력 받아 새로운 영상을 합성하는 다중모달 기능을 제공하며, 최대 약 16초 길이의 영상까지 생성할 수 있었습니다. 또한 스타일 트랜스퍼(예: 실제 영상을 만화 스타일로 변환)나 스토리보드 모드 등 다양한 생성 옵션을 갖추어 사용자들이 창의적인 영상을 제작하도록 지원했습니다. 최근에는 차세대 모델인 Gen-3와 Gen-4 (터보 버전)가 공개되어, 영상의 사실감과 temporal한 장면 연결이 더욱 향상되었습니다. 특히 Gen-3 Turbo 모델은 첫 프레임과 마지막 프레임을 사용자가 지정하여 정확한 스토리 연출이나 부드러운 루프 영상을 만들 수 있게 했고, Gen-4 Turbo 모델은 자연스러운 모션과 다양한 화면 비율 지원에 초점을 맞춰 세로형, 정사각형 비디오까지도 안정적으로 생성합니다. Runway의 기본 생성 해상도는 720p이지만, 결과 영상에 대해 원클릭 4K 업스케일 기능을 제공하여 품질을 보완하고 있습니다. 무엇보다 Turbo 버전들은 생성 속도를 크게 높여 사실상 실시간 프로토타이핑이 가능할 정도의 응답성을 구현했는데, 이를 통해 크리에이터들이 아이디어를 빠르게 영상으로 실험해볼 수 있는 워크플로우 혁신을 이루었습니다.
Google Lumiere(2024)

이미지의 가려진 부분도 주변 이미지와 합성해 완전한 영상으로 만들어주는 ‘비디오 인페인팅 기능’, (사진=구글 루미에르 깃허브 캡처)
구글이 2024년 초 발표한 Lumiere는 텍스트-투-비디오(Text-To-Video) 분야에 새로운 패러다임을 제시한 연구 모델로 평가받습니다. Lumiere의 가장 큰 혁신은 Space-Time U-Net이라는 새로운 딥러닝 구조를 도입해, 영상 생성 시 시간축상의 일관성(Temporal Consistency) 문제를 크게 개선한 점입니다. 기존 많은 모델들이 긴 영상을 만들 때 일부 키프레임만 생성하고 그 사이를 보간하는 방식이어서 프레임 간 움직임이 불안정했지만, Lumiere는 영상의 전체 프레임들을 한 번에 다루는 방식으로 처리해 개별 프레임들이 유기적으로 연결된 결과를 냅니다. 쉽게 말해, 첫 장면부터 마지막 장면까지 모델이 한 번에 내다보며 그리는 덕분에 객체가 중간에 사라지거나 형태가 튀는 일이 줄어들고, 움직임도 자연스럽고 부드럽게 이어집니다. 이 모델은 텍스트 프롬프트만으로 5초 길이(80프레임, 16fps)의 1024×1024 고해상도 영상을 직접 생성해냈으며, 이미지 한 장을 입력받아 그 속 인물이 눈을 깜박이거나 미소 짓게 하는 등 정지 이미지를 움직이는 영상으로 만드는 기능도 선보였습니다. 또한 영상의 일부분만 움직이는 시네마그래프 효과, 특정 스타일의 참고 이미지를 받아들여 영상의 화풍을 바꾸는 스타일 변환, 그리고 영상 속 일부 요소를 지우거나 다른 것으로 교체하는 비디오 인페인팅(영상 추론) 등 고급 편집 기능까지 통합하여, 한층 다재다능한 생성 능력을 보여주었습니다. 다만 Lumiere는 아직 연구 단계의 모델로, 일반에 공개되어 있지는 않으며 (구글이 논문을 통해 개념을 시연) 향후 제품화 여부는 지켜봐야 합니다. 그럼에도 불구하고 Lumiere가 제시한 기술적 아이디어는 향후 텍스트-투-비디오(Text-To-Video) 모델들의 표준을 한 단계 끌어올릴 것으로 전망됩니다.
3. 텍스트-투-비디오(Text-To-Video) 최신 기술 발전: 일관성, 해상도, 제어력
텍스트 입력만으로 동영상을 만들어주는 기술이 실용화되기 위해 연구자들이 특히 집중해온 문제는 “시간적 일관성(Temporal Consistency)”입니다. 초기의 생성 영상들은 프레임마다 디테일이 맞지 않아 깜빡이듯 어색한 경우가 많았는데, 최신 모델들은 프레임 사이의 변화까지 고려하는 새로운 아키텍처로 이러한 문제를 상당 부분 해결했습니다. 예를 들어 앞서 소개한 Lumiere는 모든 프레임을 한꺼번에 생성하는 공간-시간 확산모델을 도입하여, 이전 모델들에서 흔했던 “움직이는 사이에 손이나 물체 일부가 사라지는” 현상을 크게 개선했습니다. 그 결과 사용자들은 더욱 부드럽게 연결되고 일관성 있는 동영상을 얻을 수 있게 되었습니다.

VideoProc을 활용한 해상도 향상과 FPS 보간 예시
(7 Best AI Video Upscalers (2025): Improve Video Quality, medium)
해상도 측면에서도 눈에 띄는 발전이 이어졌습니다. 불과 몇 년 전만 해도 생성 영상의 해상도는 240p~480p 정도로 낮았으나, 이제는 대부분 720p 이상의 HD 영상을 직접 생성하고, 일부 모델은 1080p 풀HD까지도 출력합니다. 생성 단계에서 해상도가 다소 제한적이더라도, Runway처럼 생성된 720p 영상을 후처리 업스케일러로 4K까지 올리는 기술이 도입되어 결과물의 활용도를 높이고 있습니다. 해상도 향상은 영상 생성 AI가 실무 현장에서 바로 쓰일 수 있도록 하는 중요한 조건인데, 고해상도 출력을 위해 멀티 단계 확산모델(저해상도 생성 후 초해상화)이나 병렬 처리 최적화 등이 접목되고 있습니다.
또 하나의 키워드는 프롬프트 제어와 생성 자유도의 향상입니다. 단순히 한 문장에 따른 한 장면의 영상을 만드는 단계를 넘어, 사용자가 스토리라인이나 장면 전환을 세분 제어할 수 있게 된 것이지요. 대표적으로 Runway Gen-3은 첫 번째/마지막 프레임을 직접 지정하여 시작과 끝이 명확한 영상을 만들 수 있고, Pika Labs는 중간중간 키프레임을 설정해 각 구간마다 다른 움직임이나 카메라 시점을 주는 기능을 제공함으로써 영상 연출의 자유도를 높였습니다. 또한 멀티프롬프트 스토리보드 기능을 통해 하나의 긴 영상을 여러 텍스트 조각(씬)으로 나눠서 순차적으로 생성, 이어붙이는 시도도 이루어지고 있습니다. 이러한 제어력 개선 덕분에 사용자는 더 긴 분량의 영상도 장면을 나눠 제작하고 합성할 수 있게 되었고, 영상 내 세부 연출(예: 초반 2초간은 어두운 밤 장면, 3초째부터는 해가 뜨는 아침 장면 등)도 원하는 대로 조정할 수 있게 되었습니다.
흥미롭게도 최근에는 멀티모달 발전으로 영상과 오디오를 함께 생성하는 단계까지 나아가고 있습니다. 예를 들어 구글이 2025년 3월 발표한 비디오 생성 AI ‘Veo 3’는 영상과 동시에 그에 맞는 소리와 심지어 내레이션 대사까지 함께 만들어낼 수 있는데, 덕분에 ASMR 장르에서는 영상의 청각적 몰입감까지 AI가 한 번에 구현해내고 있습니다. 실제로 앞서 소개한 유리 과일을 자르는 소리도 AI가 생성한 것이죠. 이처럼 영상+음향 통합 생성은 광고나 게임 등 소리의 비중이 큰 분야에서도 매우 유용할 전망이며, 텍스트-투-비디오(Text-To-Video) 기술을 진정한 멀티미디어 생성 AI로 진화시키는 중요한 흐름입니다.
요약하면, 텍스트-투-비디오(Text-To-Video) 분야의 기술적 진보는 (1) 프레임 간 시간 일관성 향상, (2) 출력 해상도와 길이 확대, (3) 사용자 제어력 강화, 그리고 (4) 멀티모달 통합의 방향으로 빠르게 이루어지고 있습니다. 이러한 발전이 쌓이면서 AI가 만들어내는 영상은 갈수록 자연스러워지고 품질이 높아져, 머지않아 일반 사용자가 전문 장비 없이도 고품질 영상을 창작하는 일이 일상이 될 것으로 보입니다.
4. 산업 분야에서의 활용 사례
생성형 비전 AI의 실제 활용은 이미 다양한 산업에서 모색되고 있습니다. 특히 광고 마케팅, 게임, 소셜미디어 콘텐츠 분야에서 텍스트-투-비디오(Text-To-Video) 기술의 잠재력이 크게 주목받고 있습니다:
광고 및 마케팅

AI 기술로 구현한 A2+ 우유 TV광고, 서울우유
제품 광고나 프로모션 영상 제작에 텍스트-투-비디오(Text-To-Video)를 활용하면 콘텐츠 제작 시간을 획기적으로 단축하고, 하나의 아이디어로 여러 버전의 광고 영상을 손쉽게 만들어 AB 테스트해볼 수 있습니다. 예를 들어 마케터는 “햇살 가득한 해변에서 사람들이 우리 음료를 즐긴다” 같은 문장만으로 콘셉트 영상을 즉각 얻고, 이를 기반으로 캠페인 영상을 발전시킬 수 있습니다. AI가 자동으로 짧은 광고 스팟이나 소셜미디어용 영상을 만들어주는 서비스들이 이미 등장하고 있으며, 스타트업들은 사용자 맞춤형(퍼스널라이즈드) 광고 영상을 대량 생성하는 솔루션 개발에도 나서고 있습니다.
게임 시네마틱 및 미디어 제작

AI로 재현한 실화…‘신비한TV 서프라이즈’ Project AI, MBC
게임 분야에서는 텍스트-투-비디오(Text-To-Video)로 게임 시네마틱 영상이나 컨셉 트레일러를 손쉽게 제작하는 방안이 연구되고 있습니다. 예를 들어 게임 기획자가 시나리오 문장을 입력하면 AI가 해당 장면의 러프한 영상 연출을 생성해주어, 개발 초기에 사전 시각화(pre-visualization) 자료로 활용할 수 있습니다. 또한 인디 게임 개발자는 별도 모션 캡처나 3D 모델링 작업 없이도 AI를 통해 간단한 컷신 영상을 만들어 게임에 삽입하는 것도 가능해질 것입니다. 최근 MBC ‘신비한TV 서프라이즈’에서 준비한 생성형 인공지능(AI)을 활용한 특집 코너 ‘Project AI’는 그동안 ‘서프라이즈’ 의 장점으로 꼽히는 탄탄한 스토리텔링에 실현 불가능했던 영상을 AI 기술로 구현하였습니다. 이처럼 문화 산업(영화, 애니메이션, 게임) 전반에서 텍스트-투-비디오(Text-To-Video) 기술은 콘텐츠 프로토타이핑과 자동화를 이끌 도구로 부상하고 있습니다.
소셜미디어 및 크리에이터 콘텐츠

숏폼에서 활용되는 생성형 비전 AI (출처 유튜브 좌:야옹멍 YaongMeong, 우:눈or귀)
틱톡이나 인스타그램 릴스와 같은 숏폼 영상 플랫폼에서는 남다른 아이디어의 짧고 강렬한 영상이 곧 경쟁력입니다. 크리에이터들은 이제 AI를 활용해 기상천외한 상상을 현실화한 영상을 빠르게 만들어낼 수 있게 되었습니다. 앞서 소개한 유리 과일, 용암 디저트 ASMR처럼 현실에서는 불가능한 소재를 다룬 영상이 바이럴되는가 하면, AI로 생성한 가상 인플루언서나 캐릭터가 등장하는 콘텐츠도 관심을 모으고 있습니다. 실제로 불가능한 영상을 만드는 틱톡 채널들이 속속 생겨나고 있으며, 소셜미디어 콘텐츠의 새로운 트렌드로 자리잡고 있습니다. AI로 생성했다는 사실 자체가 흥미요소가 되기도 하고, 시청자 입장에서도 한번 보면 시선을 뗄 수 없는 몰입감을 주기 때문입니다. 이외에도 교육 분야에서는 교사가 텍스트로 설명한 역사 장면이나 과학 실험 과정을 AI 영상으로 보여주는 시도가 이루어지고 있고, 음악 산업에서는 가사나 음악 분위기에 맞춰 자동 생성한 뮤직비디오를 활용하는 등 다양한 분야로의 확장이 계속되고 있습니다.
5. 개발자를 위한 기술적 시사점
생성형 비전 AI의 부상은 AI/ML 연구자와 소프트웨어 개발자들에게 새로운 도전과 기회를 함께 안겨주고 있습니다. 다음은 텍스트-투-비디오(Text-To-Video) 기술 흐름에서 개발자들이 주목할 만한 기술적 요소와 시사점입니다:
혁신적인 모델 아키텍처
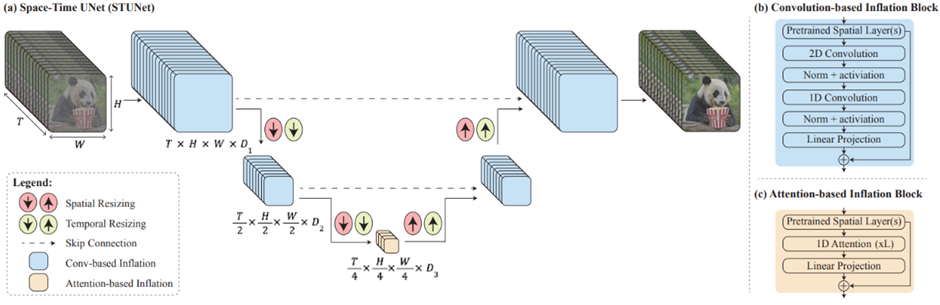
Google Lumiere의 Space-Time UNet (STUNet) 구조, Lumiere: A Space-Time Diffusion Model for Video Generation
영상 생성을 위해서는 시간 차원을 다루는 새로운 딥러닝 구조가 필요하며, Lumiere의 Space-Time UNet이나 OpenAI Sora의 Diffusion-Transformer 등 첨단 모델 아키텍처가 속속 제안되고 있습니다. 특히 Lumiere의 경우 3D 풀링을 통해 시간축까지 다운샘플링/업샘플링하는 간단한 아이디어로 기존 문제를 타개했는데, 저자들이 이렇게 단순한 설계가 이전에는 간과되어왔다고 언급했을 정도입니다. 이는 AI 개발자들에게 새로운 차원의 사고(2D에서 3D로의 확장)를 요구하며, 향후 비디오 전용 AI프레임워크나 라이브러리 발전에도 영향을 미칠 것으로 보입니다.
고성능 연산 및 최적화
텍스트-투-비디오(Text-To-Video) 모델은 매우 방대한 연산량을 요구합니다. 수백만 개의 동영상 데이터로 거대 모델을 학습시켜야 하고, 생성 시에도 한 편의 영상을 만들기 위해 다수의 프레임을 순차적으로 렌더링해야 하죠. 따라서 대용량 GPU/TPU 클러스터 인프라와 모델 최적화 기법이 필수적입니다. 예를 들어 OpenAI Sora의 경우 영상을 바로 픽셀로 생성하지 않고 잠재 공간(latent space)에서 3D 패치 단위로 생성한 뒤 복원하는 접근으로 효율을 높였으며 Runway는 Turbo 모델 도입을 통해 생성 속도를 실시간에 가깝게 향상시켰습니다. 개발자들은 이러한 효율화 전략 (모델 경량화, 분산처리, 캐싱 등)에 대한 고민과 함께, 서비스 단계에서는 클라우드 API를 통한 제공 등 인프라 설계 측면의 고려가 필요합니다.
멀티모달 및 시스템 통합
AI 툴 카탈로그 서비스, Toolify.ai
이제 텍스트-투-비디오(Text-To-Video) 모델은 단순히 영상 하나 생성에서 나아가 종합적인 콘텐츠 생성 플랫폼으로 발전하고 있습니다. 영상과 함께 배경음이나 효과음, 나아가 대본 내레이션 음성까지 동시에 생성해주는 모델(Veo 3 등)도 나오면서, 향후 개발자는 이러한 멀티모달 요소를 한데 묶는 시스템 통합 역량이 중요해질 것입니다. 예컨대, 텍스트-투-비디오(Text-To-Video) + 텍스트-투-오디오 + 대화형 인터페이스를 결합하면 사용자가 채팅하듯 시나리오를 입력해 바로 영상 컨텐츠를 얻는 형태의 서비스도 가능해집니다. 실제로 OpenAI는 ChatGPT에 Sora의 비디오 생성 기능을 통합하여 대화형으로 영상을 만들 수 있는 기능을 준비 중인데, 이는 일반 개발자들도 OpenAI API를 통해 손쉽게 프롬프트로 영상 생성 기능을 자신의 앱에 적용할 수 있게 된다는 뜻입니다. 앞으로 소프트웨어 엔지니어들은 AI 모델들을 조합하여 새로운 사용자 경험을 디자인하는 능력이 더욱 중요해질 것입니다.
윤리적 고려와 콘텐츠 안전장치

생성형 AI, 왜 윤리적으로 사용해야 하나요?, 대한민국 정책브리핑
한편, AI로 누구나 현실 같은 영상을 만들 수 있게 되면서 딥페이크나 가짜뉴스 영상 등에 대한 우려도 커지고 있습니다. 개발자들은 이러한 AI 윤리 이슈를 간과해서는 안 됩니다. 실제로 OpenAI는 Sora를 공개하며 폭력적·선정적·증오 콘텐츠나 유명인 얼굴 합성 등의 프롬프트는 철저히 제한하고, 생성된 모든 영상에 “AI 생성됨”을 표시하는 메타데이터(C2PA)를 삽입하는 조치를 도입했습니다. 이는 향후 디지털 콘텐츠 인증 표준이나 관련 법규가 마련될 가능성을 염두에 둔 선제 대응으로 볼 수 있습니다. 개발자들은 모델 개발 단계에서 데이터 편향성 제거, 출력 콘텐츠 필터링, 워터마크 삽입 등의 기법을 고려해야 하며, 생성 AI 기술을 제품에 적용할 때 사회적 악용 가능성에 대한 사전 검토와 안전장치 마련을 병행해야 할 것입니다.
6. 맺으며
생성형 비전 AI – 특히 텍스트-투-비디오(Text-To-Video) 기술의 약진으로 우리는 상상력이 곧 영상이 되는 새로운 창작 시대를 맞이하고 있습니다. 불과 몇 년 전만 해도 공상에 가깝던 일이 이제는 틱톡 영상과 유튜브 쇼츠를 통해 현실이 되고 있죠. 이러한 변화는 콘텐츠 산업의 지형을 바꾸는 한편, 개발자들에게도 혁신의 기회이자 책임을 안겨줍니다. 기술 트렌드에 관심을 가지고 있는 AI/ML 개발자라면, 텍스트-투-비디오(Text-To-Video) 모델들의 최신 동향과 핵심 개념(예: 확산모델의 시간 확장, 멀티모달 통합 등)을 꾸준히 학습하고 실험해보는 것이 중요합니다. 텍스트-투-비디오(Text-To-Video) 툴을 직접 사용해보고 싶다면 Toolify.ai 같은 메타 플랫폼에서 최신 도구들을 비교해볼 수 있습니다. 아울러 새로운 창작 도구로서 이 기술이 가져올 비즈니스 활용 가능성을 모색하되, 그 사회적 영향에도 눈을 기울여 책임 있는 AI 활용 방안을 고민해야 할 것입니다. 앞으로 펼쳐질 몰입형 콘텐츠의 시대, 개발자들의 역할을 기대합니다.