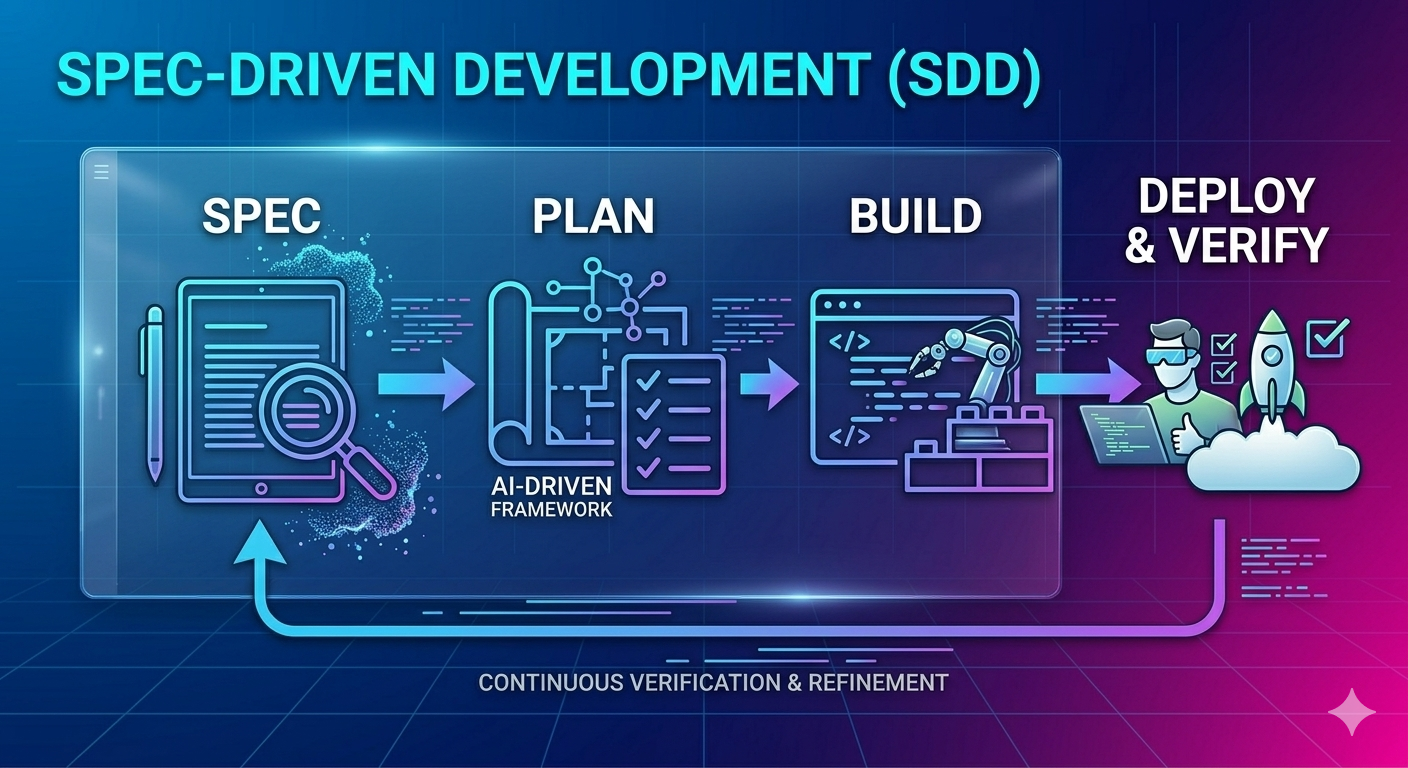
AI 코딩 도구가 코드를 “생성”하는 것은 이제 놀랍지 않다. 진짜 문제는 그 코드가 의도한 대로 동작하게 만드는 것이다. 이 글은 AI 코딩의 현실적 한계에서 출발하여, “Less is More” 원칙에 기반한 명세 주도 개발(SDD, Spec-Driven Development)의 개념, 구현 전략, 그리고 엔터프라이즈 레거시 전환 프로젝트에서의 실전 적용 방안을 다룬다.
들어가며: AI가 코드를 쓰는 시대, 무엇이 달라져야 하는가
2025년을 기점으로 AI 코딩 도구는 개발자의 일상이 되었다. 자동 완성을 넘어, 자연어로 기능을 설명하면 전체 모듈을 생성하는 수준에 이르렀다. 개발 생산성이 비약적으로 향상되었다는 보고가 쏟아지고, 많은 조직이 AI 코딩 도구 도입을 서두르고 있다.
하지만 실제로 AI 코딩 도구를 프로덕션 수준의 프로젝트에 적용해본 팀이라면, 데모에서는 보이지 않던 문제들을 경험했을 것이다. AI가 생성한 코드가 컴파일은 되지만 비즈니스 로직이 틀리다. 같은 요청을 두 번 하면 다른 코드가 나온다. 간단한 기능은 잘 만들지만, 기존 시스템과의 연동이나 예외 처리에서 무너진다. 그리고 가장 근본적인 문제 — AI에게 “무엇을 만들어야 하는지”를 정확히 전달하는 것 자체가 어렵다.
이 문제들은 AI 모델의 성능이 부족해서가 아니다. AI에게 작업을 지시하는 방식, 즉 “개발자와 AI 사이의 커뮤니케이션 구조”가 부재하기 때문이다.
1. AI 코딩의 현실: 왜 명세 주도(Spec-Driven)가 필요해졌는가
1.1 “그냥 시키면 되지 않나?” — 자유 형식 지시의 한계
AI 코딩의 가장 직관적인 사용법은 자연어로 원하는 것을 설명하는 것이다. “주문 생성 API를 만들어줘.” 간단하고 빠르다. 프로토타입이나 개인 프로젝트에서는 이 방식이 충분히 작동한다.
하지만 엔터프라이즈 환경에서는 이야기가 달라진다. “주문 생성 API를 만들어줘”라는 지시에는 결정적인 정보가 빠져 있다. 어떤 필드가 필수인가? 결제 연동은 동기인가 비동기인가? 재고 부족 시 어떻게 처리하는가? 트랜잭션 범위는 어디까지인가? 기존 레거시 시스템의 응용 프로그램 인터페이스(API, Application Programming Interface) 규격은 무엇인가?
AI는 이 빈 공간을 “그럴듯한 추측”으로 채운다. 문제는 그 추측이 종종 틀린다는 것이다. 그리고 틀린 코드가 그럴듯하게 보이기 때문에, 리뷰에서 놓치기 쉽다. 할루시네이션(Hallucination)은 챗봇에서만 일어나는 것이 아니다. 코드 생성에서도 “자신 있게 틀리는” 현상이 발생한다.
1.2 “더 많이 알려주면 되지 않나?” — 정보 과부하의 역설
자유 형식 지시의 한계를 인식한 개발자들은 자연스럽게 다음 단계로 넘어간다. “AI에게 프로젝트에 대한 정보를 더 많이 주면 되지 않을까?” 이 발상에서 탄생한 것이 AGENTS.md, CLAUDE.md 같은 “컨텍스트 파일”이다. 프로젝트의 아키텍처, 코딩 규칙, 파일 구조, 기술 스택 등을 한 파일에 담아 AI에게 제공하는 방식으로, GitHub의 60,000개 이상의 저장소에 확산되었다.
그런데 2026년 2월, ETH Zurich 연구팀이 이 접근의 효과를 최초로 체계적으로 검증했다(논문: “Evaluating AGENTS.md”, arXiv: 2602.11988v1). 138개의 실제 GitHub 이슈를 대상으로 실험한 결과는 업계의 통념을 정면으로 뒤집었다. 대규모 언어 모델(LLM, Large Language Model)이 자동 생성한 컨텍스트 파일은 성능을 오히려 떨어뜨렸고(8개 설정 중 5개에서 하락), 비용은 20~23% 증가했다. 개발자가 직접 작성한 파일도 효과는 미미했다(평균 4% 향상, 일부 모델에서는 오히려 하락).
원인은 정보 과부하(Information Overload)였다. 컨텍스트 파일이 존재하면 AI 에이전트는 더 많은 파일을 탐색하고, 더 많은 도구를 사용하며, 불필요한 작업을 수행했다. 컨텍스트 파일에 언급된 도구는 1.6배 더 사용하는 반면, 언급되지 않은 도구는 거의 사용하지 않았다. 문제는 “지시 불이행”이 아니라 AI의 “과잉 수행”이었다. 컨텍스트에 언급된 도구와 파일을 빠짐없이 처리하려는 AI 에이전트의 성향이 오히려 불필요한 탐색과 비용 증가를 유발했다.
1.3 진짜 문제: 커뮤니케이션 구조의 부재
자유 형식 지시는 정보가 부족하고, 컨텍스트 파일은 정보가 과다하다. 이 딜레마의 근본 원인은 “AI에게 무엇을, 얼마나, 어떤 형식으로 전달해야 하는가”에 대한 구조가 없다는 것이다.
사람과 사람 사이의 협업에서는 이 문제가 오래전에 해결되었다. 건축에는 설계도가 있고, 제조에는 공정 명세서가 있고, 소프트웨어에는 요구사항 명세서가 있다. 하지만 사람과 AI 사이의 협업에서는 아직 이런 구조가 확립되지 않았다. 대부분의 팀이 “자연어로 대충 설명하고, 결과를 보고 고치는” 시행착오 방식에 의존하고 있다.
ETH Zurich 논문의 결론은 이 문제에 대한 명확한 방향을 제시한다. “Less is More” — 간결하고 핵심적인 정보만, 사람이 직접 작성해야 한다. 과도한 정보는 해롭고, 자동 생성된 정보는 더 해롭다. 필요한 것은 “더 많은 정보”가 아니라 “더 나은 구조”다.
이 “더 나은 구조”가 바로 Spec-Driven Development다. AI에게 전달하는 정보의 양이 아니라 질과 형식을 체계화하는 접근이다.
2. 명세 주도 개발(Spec-Driven Development, SDD): 개념과 구현 레벨
2.1 SDD란 무엇인가
SDD는 AI로 코드를 작성하기 전에 스펙(Spec, specification: 명세서)을 먼저 작성하는 개발 방식이다. Thoughtworks의 Distinguished Engineer인 Birgitta Böckeler가 martinfowler.com에 게재한 분석에서 이 개념을 체계적으로 정리했다.
핵심 정의는 이렇다:
“Spec-driven development means writing a ‘spec’ before writing code with AI. The spec becomes the source of truth for the human and the AI.”
이 말을 설명하자면, 애자일이 확산되면서 많은 팀은 “동작하는 소프트웨어”를 우선시한 나머지 코드를 먼저 작성하고 문서는 나중에(또는 아예 쓰지 않는) 방식으로 흘러왔다. SDD에서는 순서가 뒤집힌다. 스펙을 먼저 작성하고, AI가 그 스펙을 기반으로 코드를 생성하며, 개발자가 결과를 검증한다. 스펙이 사람과 AI 모두에게 “진실의 원천(Single Source of Truth)”이 되는 것이다.
2.2 SDD의 3가지 구현 레벨
SDD는 단일한 방법론이 아니다. 구현 깊이에 따라 세 가지 레벨로 나뉜다.
Level 1: Spec-First(명세 우선)는 가장 기본적인 접근이다. 작업 전에 스펙을 작성하고, AI가 이를 기반으로 코드를 생성한다. 작업이 완료되면 스펙의 유지 여부는 선택적이다. 버그 수정이나 간단한 기능 추가처럼 “다시 볼 일이 없는” 작업에 적합하다. 건축에 비유하면, 인테리어 리모델링 전에 배치도를 그리되, 공사가 끝나면 도면을 보관하지 않는 것과 같다.
Level 2: Spec-Anchored(명세 고정)는 스펙을 장기 자산으로 유지하는 접근이다. 기능이 변경될 때 스펙을 먼저 업데이트하고, 그 스펙을 기반으로 코드를 수정한다. 스펙이 해당 기능의 살아있는 문서가 된다. 핵심 비즈니스 로직, 규제 대응 기능, 여러 팀이 공유하는 API처럼 “나중에 반드시 다시 볼” 기능에 적합하다. 대형 건물의 설계도를 준공 후에도 영구 보관하고, 증축할 때마다 설계도를 먼저 수정하는 것과 같다.
Level 3: Spec-as-Source(명세가 소스)는 가장 급진적인 접근이다. 사람은 스펙만 편집하고, 코드는 절대 직접 수정하지 않는다. 코드 파일에는 GENERATED FROM SPEC – DO NOT EDIT라는 경고가 붙는다. 비전은 매력적이지만, 현재 시점에선 LLM의 비결정론적 특성 — 같은 스펙을 줘도 매번 다른 코드가 생성되는 문제 — 때문에 시기상조다. Böckeler는 이것을 2000년대 MDD(Model-Driven Development)의 실패와 연결지으며, “유연성도 없고 결과도 예측 불가능하면 양쪽의 단점만 가진 것”이라고 우려했다.
엔터프라이즈 환경에서 현실적인 목표는 Level 2(Spec-Anchored)까지다. Level 1으로 시작하되, 핵심 모듈은 Level 2로 관리하는 것이 균형 잡힌 전략이다.
2.3 스펙과 Memory Bank: 두 가지 컨텍스트의 역할
SDD에서 AI에게 전달하는 컨텍스트는 두 종류로 나뉜다.
메모리 뱅크(Memory Bank)는 프로젝트 전반에 걸친 전역 컨텍스트다. 아키텍처 원칙, 코딩 표준, 기술 스택, 디자인 패턴 같은 정보가 여기에 해당한다. 모든 AI 코딩 세션에 자동으로 로드되며, 변경 빈도가 낮다. 회사 생활에 비유하면 “사원 핸드북”이다 — 어떤 업무를 하든 항상 적용되는 규칙이다.
스펙은 특정 기능이나 작업에 대한 명세다. 해당 작업에만 관련되며, 작업별로 생성하고 사용한다. “업무 지시서”에 해당한다 — 이번 주에 할 구체적인 작업 내용이다.
왜 둘 다 필요한가? 메모리 뱅크만 있으면 AI가 프로젝트 규칙은 알지만 “지금 뭘 만들어야 하는지”를 모른다. 스펙만 있으면 AI가 할 일은 알지만 “어떤 규칙을 따라야 하는지”를 모른다. 둘을 함께 쓰면 AI가 “프로젝트 규칙을 지키면서 + 지금 이 기능을 구현”할 수 있다.
이 구분이 AGENTS.md 논문의 교훈과 직접 연결된다. 논문에서 문제가 된 것은 “저장소 전체 정보를 한 파일에 담은” 컨텍스트 파일이다. SDD에서는 이것을 메모리 뱅크(Memory Bank, 전역, 최소한)와 스펙(작업별, 집중적)으로 분리함으로써, 정보 과부하 문제를 구조적으로 해결한다.
3. SDD 도구 비교: Thoughtworks의 실무 분석에서 배운 교훈
3.1 세 가지 도구의 실전 평가
Birgitta Böckeler는 martinfowler.com에서 세 가지 SDD 개발 도구를 직접 사용해보고 비교 분석했다. 각 도구가 SDD를 어떻게 구현하는지, 그리고 실무에서 어떤 문제가 발생하는지를 솔직하게 기록한 글이다.
첫 번째 도구(AWS의 Kiro)는 가장 경량한 접근을 취한다. Requirements → Design → Tasks의 3단계 워크플로우로, 직관적이고 파일 수가 적다. 이 도구에서 메모리 뱅크는 스티어링(Steering) 파일로 구현되며, 항상 로드(always), 파일 패턴 매칭시 로드(fileMatch), 수동 로드(manual)의 세 가지 선택가능하도록 하는 전략을 제공한다. 평가는 “가장 단순하고 직관적”이었지만, “작은 버그 수정에도 4개의 유저스토리(User Story)와 16개의 승인기준(Acceptance Criteria)이 생성되어 과도하다”는 지적이 있었다.
두 번째 도구(GitHub Spec-Kit)는 Constitution이라는 강력한 메모리 뱅크 개념을 도입했다. 프로젝트의 불변 원칙을 정의하고, 모든 변경이 이 원칙을 준수하는지 체크리스트로 검증한다. 체계적이지만, “너무 많은 마크다운 파일이 생성되어 코드 리뷰가 더 나았을 것”이라는 평가를 받았다. Böckeler의 표현이 인상적이다: “To be honest, I’d rather review code than all these markdown files.”
세 번째 도구(Tessl Framework)는 Spec-as-Source를 명시적으로 지향한다. 코드 파일당 1개의 스펙이 1:1로 매핑되고, 사람은 스펙만 편집한다. 비전은 명확하지만, 같은 스펙으로 여러 번 생성하면 매번 다른 코드가 나오는 비결정론적 문제가 발견되었다. Böckeler는 이것을 “MDD의 유연성 부족과 LLM의 비결정성이라는 양쪽의 단점을 모두 가진 것”이라고 평가했다.
3.2 Böckeler가 던진 핵심 질문들
이 비교 분석에서 Böckeler가 제기한 다음 질문들은 SDD를 실무에 적용하려는 모든 조직이 답해야 할 질문들이다.
“하나의 워크플로우로 모든 크기의 문제를 커버할 수 있는가?” 오타 수정(1줄)과 모듈 전환(수천 줄)에 같은 프로세스를 적용하는 것은 비효율적이다. 작업 크기별로 유연한 워크플로우가 필요하다.
“스펙 리뷰가 코드 리뷰보다 나은가?” 과도한 마크다운 파일은 리뷰 피로(Review Fatigue)를 유발한다. 간결한 스펙은 가치 있지만, 장황한 스펙은 오히려 해롭다.
“통제의 착각은 아닌가?” 아무리 많은 문서와 체크리스트를 만들어도, AI 에이전트가 모든 지시를 따르지는 않는다. 큰 컨텍스트가 완벽한 통제를 보장하지 않는다. 작은 반복적 단계와 자동 검증이 더 안전하다.
“MDD의 실패를 반복하는 것은 아닌가?” 2000년대 모델 주도 개발(Model-Driven Development)는 모델에서 코드를 자동 생성하려 했지만, 어색한 추상화 레벨과 과도한 오버헤드로 대부분 실패했다. LLM 기반 SDD는 자연어를 사용한다는 점에서 MDD보다 유연하지만, 비결정론적 생성이라는 새로운 문제를 추가한다.
이 질문들에 대한 Böckeler의 결론은 균형 잡혀 있다. SDD의 Spec-First 원칙 자체는 가치가 있다. 하지만 구현이 과도하면 “개선하려다 악화(Verschlimmbesserung)”될 수 있다. 실용주의가 핵심이다.
3.3 역사적 교훈: MDD에서 배우기
SDD를 논할 때 MDD(Model-Driven Development)의 역사를 빼놓을 수 없다. 2000년대에 UML이나 DSL(Domain-Specific Language)로 모델을 정의하고, 그 모델에서 코드를 자동 생성하려는 시도가 있었다. 임베디드 시스템 같은 특정 도메인에서는 성공했지만, 비즈니스 애플리케이션에서는 대부분 실패했다.
실패 원인은 명확하다. 추상화 레벨이 어색했다 — 너무 높으면 표현력이 부족하고, 너무 낮으면 코드와 차이가 없었다. 오버헤드가 과도했다 — 모델 작성과 도구 학습에 드는 비용이 직접 코딩보다 컸다. 유연성이 부족했다 — 특정 패턴만 지원하고, 예외 상황에 대응하기 어려웠다.
LLM 기반 SDD는 이 문제들을 일부 해결한다. 자연어를 사용하므로 별도의 모델링 언어를 배울 필요가 없고, 코드 생성기를 만들 필요도 없다. 하지만 비결정론적 생성이라는 MDD에는 없던 새로운 문제를 추가한다. 같은 스펙을 줘도 매번 다른 코드가 나올 수 있다는 것이다.
이 교훈이 시사하는 바는 분명하다. Spec-as-Source(Level 3)는 MDD의 경직성과 LLM의 비결정성을 동시에 가질 위험이 있다. Spec-Anchored(Level 2)까지가 현실적인 목표이며, 개발자가 코드를 직접 검증하고 수정할 수 있는 유연성을 반드시 유지해야 한다.
4. Less is More 원칙의 실전 구현: 스펙 설계 전략
4.1 논문 교훈에서 설계 원칙으로
AGENTS.md 논문의 “Less is More”를 실전에 적용하려면, 추상적인 원칙을 구체적인 설계 규칙으로 변환해야 한다.
논문이 “하지 마라”고 한 것들이 있다. 과도한 저장소 개요, 모든 파일 목록 나열, 일반적인 베스트 프랙티스 포함, LLM 자동 생성, 한 번에 모든 정보 전달. 이것들을 뒤집으면 “이렇게 하라”가 된다. 작업별 필요한 정보만, 관련 모듈만 참조, 프로젝트 특화 규칙만, 개발자가 직접 작성, 계층적으로 필요한 만큼만.
핵심 원칙은 한 문장으로 요약된다: “최소한의 명확한 정보를, 필요한 시점에, 필요한 만큼만.”
4.2 계층적 스펙 구조
대규모 프로젝트에서 이 원칙을 구현하는 방법은 스펙의 계층화다. 모든 정보를 하나의 파일에 담는 것이 아니라, 역할과 범위에 따라 계층으로 분리한다.
최상위에는 Global 스펙이 있다. 시스템 전체 아키텍처(Architecture 스펙, 2~3페이지)와 코딩 표준(Standard 스펙, 3~5페이지)을 정의한다. AI-COE(Center of Excellence)나 아키텍트 그룹이 관리하며, 변경 주기는 분기별이다. 모든 AI 코딩 세션에 자동으로 로드된다.
중간 계층은 Module 스펙이다. 모듈별 비즈니스 기능(Functional 스펙, 5~10페이지)과 기술 요구사항(Technical 스펙, 3~5페이지)을 정의한다. 모듈 리드가 관리하며, 해당 모듈 작업시에만 로드된다.
최하위는 Task 스펙이다. 개별 작업의 목표, 입출력, 완료 기준을 1~2페이지로 정의한다. 개발자가 직접 작성하며, 현재 작업에만 사용된다.
이 계층 구조의 핵심은 상속과 중복 제거다. 하위 스펙은 상위 스펙을 자동으로 상속하므로, 같은 정보를 반복할 필요가 없다. AI 코딩 도구가 작업을 실행할 때 로드하는 총 컨텍스트는 Global(2~3페이지) + Module(5~10페이지) + Task(1~2페이지) = 최대 15페이지 수준이다. 논문이 권장하는 “최소한의 필수 정보” 범위 안에 들어온다.
4.3 스펙 작성 실전 가이드: 좋은 스펙과 나쁜 스펙
계층 구조를 설계했다면, 다음 질문은 “각 스펙을 어떻게 작성하는가”다. 논문의 교훈을 반영한 실전 작성 원칙을 살펴보자.
좋은 Task 스펙의 예시를 보자. 주문 생성 API를 구현하는 작업이라면, 다음과 같이 작성한다.
| task: “주문 생성 API 구현” input: userId: string (required) items: array (required, min 1) paymentMethod: string (required) output: orderId: string status: “created” | “failed” estimatedDelivery: date constraints: – “트랜잭션 처리 필수” – “재고 확인 선행 (inventory-api 참조)” – “결제 연동은 비동기 처리” error_handling: – 400: 입력값 검증 실패 – 409: 재고 부족 – 500: 결제 시스템 장애 시 주문 보류 completion_criteria: – “단위 테스트 커버리지 80% 이상” – “재고 부족 시나리오 통합 테스트 포함” |
이 스펙은 1페이지 안에 들어온다. AI 코딩 에이전트가 “무엇을 만들어야 하는지”, “어떤 제약을 지켜야 하는지”, “언제 완료인지”를 명확히 알 수 있다. 입출력이 정의되어 있으므로 탐색 공간이 제한되고, 에러 처리가 명시되어 있으므로 불필요한 시도가 줄어든다.
반면, 나쁜 스펙은 이렇게 생겼다.
| 주문 관리 시스템을 구현해주세요. – 사용자가 주문을 생성할 수 있어야 합니다 – 주문 조회, 수정, 취소도 가능해야 합니다 – 결제 시스템과 연동해야 합니다 – 재고 관리도 고려해주세요 – 성능이 좋아야 합니다 – 보안도 신경 써주세요 |
이 스펙의 문제는 세 가지다. 첫째, 범위가 너무 넓다. 주문 생성, 조회, 수정, 취소, 결제 연동, 재고 관리를 한 번에 요구한다. AI 에이전트는 어디서부터 시작해야 할지 모른다. 둘째, 구체성이 없다. “성능이 좋아야 합니다”는 측정 불가능한 요구사항이다. 응답 시간 200ms 이내인지, 동시 접속 1,000명 처리인지 알 수 없다. 셋째, 완료 기준이 없다. 언제 “다 됐다”고 판단할 수 있는지 불명확하다.
논문의 발견과 직접 연결된다. 과도하고 모호한 정보는 AI 에이전트의 탐색 공간을 넓히고, 불필요한 시도를 유발하며, 비용을 증가시킨다. 반대로, 간결하고 명확한 정보는 탐색 공간을 제한하고, 일관된 결과를 유도한다.
스펙 작성의 핵심 원칙을 정리하면 다음과 같다.
하나의 스펙은 하나의 작업만 다룬다. “주문 관리 시스템”이 아니라 “주문 생성 API”다. 범위가 넓으면 분해한다.
입출력을 명시한다. AI 에이전트가 “무엇을 받아서 무엇을 반환하는지”를 정확히 알아야 한다. 타입, 필수 여부, 제약 조건까지 포함한다.
제약 사항을 구체적으로 적는다. “보안 신경 써주세요”가 아니라 “bcrypt 사용 필수, JSON 웹 토큰(JWT, JSON Web Token) 발급”이다. AI 에이전트가 “어떤 암호화를 쓸까?” 고민하는 시간이 사라진다.
완료 기준을 정의한다. 테스트 커버리지, 특정 시나리오 통과 여부, 성능 기준 등 측정 가능한 기준을 명시한다.
이 원칙들은 결국 논문의 “Less is More”를 구현 가능하게 작게, 정확하게 사용할 수 있도록 한 것이다.
5. 엔터프라이즈 레거시 전환에서의 SDD 적용
5.1 왜 레거시 전환에 SDD가 필요한가
지금까지의 논의는 주로 신규 개발 관점이었다. 하지만 SDD의 진정한 가치는 대규모 레거시 전환 프로젝트에서 드러난다.
논문의 실험 대상은 잘 관리된 오픈소스 프로젝트였다. README, docs 폴더, 예제 코드가 이미 충분히 갖춰진 환경이다. 논문이 “컨텍스트 파일이 기존 문서와 중복된다”고 지적한 것은 이런 맥락에서다. 하지만 엔터프라이즈 레거시 시스템은 정반대의 상황이다.
대형 엔터프라이즈의 레거시 시스템은 대부분 이런 특징을 갖는다. 비즈니스 로직이 코드에만 존재하고 문서화되어 있지 않다. 도메인 지식이 특정 개발자의 머릿속에만 있다. 기존 산출물(기능명세서, 화면설계서, 인터페이스명세서 등)은 수백 페이지에 달하지만, 정보가 여러 문서에 흩어져 있고 중복이 심하다. 코드와 문서의 버전이 일치하지 않는다.
논문의 발견 중 하나를 다시 떠올려보자. “문서가 없는 저장소에서는 컨텍스트 파일이 유일하게 도움이 되었다.” LLM이 자동 생성한 파일조차 평균 2.7%의 성능 향상을 보인 유일한 경우다. 레거시 전환 프로젝트는 본질적으로 “문서가 없는(또는 문서가 신뢰할 수 없는) 저장소”에 해당한다. 이런 환경에서 잘 작성된 스펙은 단순한 “도움”이 아니라 “필수”다.
5.2 기존 산출물에서 스펙으로: 92% 압축의 비밀
대형 엔터프라이즈의 레거시 전환 프로젝트에서 하나의 모듈에 대한 기존 산출물은 대략 이런 규모다. 예를 들자면, BPD(Business Process Design) 20페이지, 기능명세서 50페이지, 화면설계서 30페이지, 인터페이스명세서 40페이지, DB설계서 25페이지, 테스트케이스 60페이지. 총 6개 파일, 225페이지 이런 식이다.
이 산출물들의 문제는 양이 아니라 구조다. 같은 정보가 여러 문서에 반복된다. 주문 생성 프로세스의 입력 필드가 기능명세서, 화면설계서, 인터페이스명세서에 각각 다른 형식으로 기술되어 있다. 문서 간 버전이 다르면 어느 것이 최신인지 알 수 없다. AI 코딩 에이전트에게 이 225페이지를 그대로 전달하면? 논문이 증명한 정보 과부하가 그대로 재현된다.
SDD 접근은 이 산출물을 두 개의 스펙으로 재구조화한다. Functional 스펙(10페이지)에 기능 개요, 비즈니스 프로세스, UI 요구사항, 테스트 시나리오를 통합한다. Technical 스펙(8페이지)에 API 명세, DB 스키마, 성능 요구사항을 통합한다. 총 2개 파일, 18페이지. 225페이지에서 92% 압축이다.
이 압축이 가능한 이유는 세 가지다. 중복 제거 — 같은 정보를 한 곳에만 기술한다. 불필요한 정보 제거 — AI 코딩에 필요하지 않은 관리적 정보(승인 이력, 변경 이력 등)를 제외한다. 구조화 — 자연어 서술을 정형화된 형식(입출력 정의, 제약 조건, 완료 기준)으로 변환한다.
핵심은 “기존 산출물이 나쁘다”는 것이 아니다. 기존 산출물은 사람이 읽기 위해 설계된 것이고, 스펙은 AI가 읽기 위해 설계된 것이다. 목적이 다르므로 형식도 달라야 한다.
5.3 수백 명 규모 프로젝트에서의 SDD 운영
10명 팀의 SDD와 200명 팀의 SDD는 근본적으로 다른 문제다. 소규모 팀에서는 스펙 작성자와 사용자가 같은 사람이거나 바로 옆에 앉아 있다. 대규모 팀에서는 스펙을 작성하는 사람, 리뷰하는 사람, 사용하는 사람이 모두 다르고, 서로 다른 모듈에서 작업하면서 API를 통해 연결된다.
대규모 프로젝트에서 SDD를 운영할 때 핵심 과제는 세 가지다.
첫째, Multi-Project API 참조 문제다. 주문 서비스가 결제 서비스의 API를 호출해야 할 때, 결제 서비스의 전체 스펙을 주문 서비스의 컨텍스트에 포함하면 정보 과부하가 발생한다. 해결책은 “계약(Contract)” 기반 참조다. 결제 서비스의 전체 스펙 대신, 주문 서비스가 사용하는 엔드포인트의 입출력 계약만 참조한다. OpenAPI나 GraphQL 스펙을 중앙에서 관리하고, 각 모듈의 스펙에서 필요한 부분만 참조 링크로 연결하는 구조다.
둘째, 스펙 품질의 균일성 문제다. 200명의 개발자가 각자 스펙을 작성하면, 품질 편차가 심해진다. 어떤 스펙은 입출력이 명확하고 제약 조건이 구체적인 반면, 어떤 스펙은 “잘 만들어주세요” 수준이다. 해결책은 표준화된 템플릿과 자동 검증이다. 필수 섹션(목표, 입출력, 제약 조건, 완료 기준)을 템플릿으로 강제하고, 린팅 도구로 완성도를 자동 체크한다. 논문이 “개발자가 작성해도 효과가 미미했다”고 한 것은 품질 관리 없이 자유 형식으로 작성했기 때문이다. 템플릿과 리뷰 프로세스로 품질을 통제하면 결과가 달라진다.
셋째, 작업 크기별 워크플로우 유연성이다. Birgitta Böckeler가 지적한 “작은 버그 수정에 4개의 유저스토리(User Story)와 16개의 승인기준(Acceptance Criteria)이 생성되는” 문제는 실제로 대규모 프로젝트에서 빈번하게 발생한다. 해결책은 작업 크기별로 다른 워크플로우를 적용하는 것이다. 소규모 변경(버그 수정, 1~2줄 수정)은 스펙 없이 직접 AI 코딩한다. 중규모 변경(3~5일 작업)은 Task 스펙만 작성한다. 대규모 변경(신규 모듈, 복잡한 기능)은 전체 워크플로우(Requirements → Design → Tasks)를 적용한다. 모든 문제에 같은 프로세스를 적용하는 것은 작업 규모에 맞지 않는 불필요한 오버헤드를 만들 뿐이다.
5.4 점진적 전환 전략: Big Bang은 실패한다
레거시 전환에서 가장 흔한 실패 패턴은 “모든 기능명세서를 한 번에 스펙으로 변환하자”는 빅뱅(Big Bang) 접근이다. 수백 개의 문서를 6개월에 걸쳐 일괄 변환하고, 완료될 때까지 사용하지 않는다. 6개월 후에는 요구사항이 이미 변경되어 스펙이 구식이 된다. 실패 확률이 극히 높다.
성공하는 전환 전략은 다음과 같은 점진적 방법이다.
20/80 규칙 적용: 전체 모듈의 20%가 80%의 가치를 제공한다. 변경 빈도가 높은 모듈, 신규 개발 예정 기능, 버그가 많은 레거시 모듈을 우선 선정한다. 이 핵심 모듈만 먼저 스펙화하고, 나머지는 필요할 때 점진적으로 전환한다.
파일럿으로 시작: 1~2개 모듈로 전체 프로세스를 검증한다. 기능명세서에서 스펙으로의 변환, AI 코딩 에이전트를 통한 코드 생성, 품질 측정까지 한 사이클을 돌려본다. 이 과정에서 템플릿을 개선하고, 프로세스를 문서화하고, 팀의 학습 곡선을 파악한다.
병행 운영 : 기존 기능명세서를 즉시 폐기하지 않는다. 스펙화된 모듈부터 스펙을 진실의 단일 원천(Single Source of Truth)로 사용하고, 나머지는 기존 문서를 유지한다. 점진적으로 스펙의 비중을 높여간다.
측정: “스펙을 만들었으니 좋아졌겠지”는 위험한 가정이다. AI 코딩 에이전트의 성공률, 코드 리뷰 통과율, 개발 시간 변화, LLM API 비용을 정량적으로 측정한다. 데이터가 개선을 보여주면 확대하고, 그렇지 않으면 스펙의 품질을 재검토한다.
6. SDD와 AI-Native 설계 패러다임의 연결
6.1 두 패러다임의 교차점
이 글에서 다룬 SDD는 “AI에게 코드를 어떻게 작성하게 할 것인가”에 대한 방법론이다. 이전 글에서 다룬 AI-Native 설계 패러다임은 “AI를 시스템에 어떻게 내재화할 것인가”에 대한 아키텍처 원칙이다. 이 두 가지는 별개의 주제가 아니라, 같은 문제의 다른 면이다.
AI-Native 설계 패러다임의 핵심 원칙을 떠올려보자. “AI는 시스템의 중심이 아니라, 통제된 해석 계층이다.” 뉴로-심볼릭 아키텍처(Neuro-Symbolic Architecture)에서 AI는 의도를 해석하고, 결정적 엔진이 실행한다. AI의 확률적 특성이 핵심 비즈니스 로직에 침투하지 않도록 아키텍처 수준에서 격리한다.
SDD의 핵심 원칙도 동일한 철학을 공유한다. “AI에게 모든 것을 맡기지 않는다.” 스펙으로 범위를 제한하고, 개발자가 결과를 검증하며, 핵심 설계 판단은 사람이 내린다. AI의 비결정론적 특성이 시스템 설계에 침투하지 않도록 프로세스 수준에서 통제한다.
두 패러다임의 공통 원칙을 정리하면 이렇다.
| 원칙 | AI-Native 설계 | SDD |
| AI의 역할 제한 | 해석 계층으로 격리 | 스펙 범위 내로 제한 |
| 사람의 통제 유지 | HITL, Validation Layer | 개발자 검증, 스펙 리뷰 |
| 비용 최적화 | Model Right-Sizing, Caching | Prompt Caching, 계층적 로딩 |
| 관측 가능성 | Observability 5대 항목 | 성공률, 비용, 품질 측정 |
| 점진적 도입 | Shadow Mode → Canary → 전환 | 파일럿 → 확산 → 최적화 |
6.2 통합 적용: AI로 설계하고, AI로 구현하고, AI를 통제한다
엔터프라이즈 레거시 전환 프로젝트에서 두 패러다임을 통합 적용하면 다음과 같은 흐름이 된다.
설계 단계에서는 AI-Native 설계 원칙을 적용한다. 시스템을 뉴로(Neuro,AI 해석) 영역과 심볼릭(Symbolic, 결정적 실행) 영역으로 분리하고, 5계층 아키텍처(5-Layer Architecture)를 설계하고, 비용 최적화 전략(Model Right-Sizing, Caching, Confidence 필터)을 아키텍처에 내재화한다. 이 설계 결과가 전역(Global) 스펙과 모듈(Module) 스펙에 반영된다.
구현 단계에서는 SDD를 적용한다. 설계 단계에서 정의된 아키텍처 원칙이 메모리 뱅크(전역 컨텍스트)로 자동 로드되고, 각 작업의 Task 스펙이 AI 코딩 에이전트에게 전달된다. AI 에이전트는 “프로젝트의 아키텍처 원칙을 지키면서 + 이 작업의 스펙을 구현”한다.
검증 단계에서는 AI-Native의 제어 계층(Control Layer) 원칙이 적용된다. AI가 생성한 코드가 출력 스키마(Output Schema)를 준수하는지, 신뢰 임계점(Confidence Threshold)을 통과하는지, 기존 시스템과의 동작 동등성이 보장되는지를 자동으로 검증한다. 검증을 통과하지 못하면 개발자가 개입한다.
이 통합 흐름에서 핵심은 “AI가 AI를 통제하는 구조”가 아니라 “사람이 설계한 구조가 AI를 통제하는 구조”라는 점이다. 스펙이 AI의 행동 범위를 정의하고, 아키텍처가 AI의 배치 위치를 정의하고, 제어 계층이 AI의 출력을 검증한다. AI는 이 구조 안에서 최대한의 생산성을 발휘하되, 구조 밖으로 벗어나지 않는다.
6.3 “Less is More”의 확장: 설계에서 운영까지
AGENTS.md 논문의 “Less is More”는 원래 AI 코딩 에이전트에 대한 컨텍스트 전달 전략이었다. 하지만 이 원칙은 AI 시스템 설계 전반으로 확장된다.
AI-Native 설계에서도 “Less is More”다. AI에게 모든 비즈니스 로직을 맡기는 것이 아니라, 해석과 분류라는 제한된 역할만 위임한다. 5계층 아키텍처에서 AI가 담당하는 것은 Layer 2(LLM Layer) 하나뿐이다. 나머지 4개 계층은 결정적 로직이 통제한다.
비용 최적화에서도 “Less is More”다. 모든 요청을 고성능 모델로 처리하는 것이 아니라, 신뢰 기반 조기 종료 필터로 60~70%의 요청을 경량 모델이나 규칙 기반으로 처리한다. 고성능 모델이 처리하는 것은 전체의 10~20%에 불과하다.
거버넌스에서도 “Less is More”다. 모든 개발자에게 AI 사용의 완전한 자유를 주는 것이 아니라, AI-COE(Center of Excellence)가 표준을 정의하고, 계층적 스티어링(Steering)으로 일관성을 유지하며, AI 게이트웨이를 통해 중앙에서 통제한다. 통제가 많을수록 좋은 것이 아니라, 핵심적인 통제만 효과적으로 적용하는 것이 중요하다.
결국 “Less is More”는 AI 시대의 설계 철학이다. AI의 능력이 강력해질수록, 그 능력을 어디에 쓰고 어디에 쓰지 않을지를 결정하는 것이 더 중요해진다. 모든 곳에 AI를 적용하는 것이 아니라, AI가 가장 효과적인 곳에만 집중적으로 적용하고, 나머지는 검증된 결정적 방식을 유지하는 것. 이것이 엔터프라이즈 환경에서 AI를 안전하고 효율적으로 활용하는 핵심 원칙이다.
마치며: 스펙은 AI와의 계약이다
이 글의 출발점은 ETH Zurich의 실험 결과였다. “AI에게 더 많은 정보를 주면 더 좋은 코드를 만든다”는 통념이 틀렸다는 발견. 60,000개 저장소가 채택한 방식이 실제로는 성능을 떨어뜨리고 비용을 높인다는 데이터.
이 발견에서 도출된 “Less is More” 원칙은 단순한 경험칙이 아니다. AI 코딩 시대의 설계 원칙이다. 간결하고 핵심적인 정보만, 사람이 직접 작성하고, 필요한 시점에 필요한 만큼만 전달한다. 이 원칙을 체계적으로 구현한 것이 SDD(Spec-Driven Development)다.
SDD에서 스펙은 단순한 문서가 아니다. 사람과 AI 사이의 계약이다. 사람은 스펙을 통해 “무엇을 만들어야 하는지, 어떤 제약을 지켜야 하는지, 언제 완료인지”를 정의한다. AI는 그 계약의 범위 안에서 최대한의 생산성을 발휘한다. 계약이 명확할수록 결과가 좋고, 계약이 모호할수록 결과가 나쁘다. 이것은 논문이 138개 이슈에 대한 실험으로 증명한 사실이다.
엔터프라이즈 레거시 전환이라는 맥락에서 SDD의 가치는 더욱 분명해진다. 문서가 부재하거나 신뢰할 수 없는 환경, 수백 명의 개발자가 동시에 작업하는 환경, 비즈니스 연속성을 유지하면서 시스템을 전환해야 하는 환경. 이런 환경에서 “AI에게 알아서 하라”는 접근은 통하지 않는다. 명확한 스펙, 계층적 구조, 점진적 전환, 정량적 측정. 이 네 가지가 대규모 AI 코딩의 성공 조건이다.
모델은 6개월마다 바뀌고, 도구는 매년 새로운 것이 등장한다. 하지만 “Less is More”라는 원칙, 그리고 그 원칙을 구현하는 SDD의 설계 철학은 도구와 모델에 종속되지 않는다. AI가 더 강력해질수록, 그 힘을 통제하는 구조의 중요성은 더 커진다.
*이 글은 ETH Zurich 논문 “Evaluating AGENTS.md”(arXiv: [2602.11988v1](https://arxiv.org/abs/2602.11988))와 Birgitta Böckeler의 martinfowler.com 분석 “Understanding Spec-Driven Development”를 기반으로, 엔터프라이즈 레거시 전환 프로젝트에서의 실전 적용 경험을 더해 작성되었습니다.*