- 서론 : 범용 LLM의 한계와 sLLM의 부상
최근 기업과 공공기관에서 생성형 AI 도입이 활발하다. 그러나 범용 대규모 언어모델(LLM, Large Language Model)을 그대로 업무에 활용하는 데에는 몇 가지 현실적 한계가 존재한다. 범용 LLM은 방대한 데이터를 학습했기 때문에, 법률·조세·의료 같은 전문 분야에서는 원하는 답변을 얻기 어렵고, 수십~수천억 개 파라미터로 인해 추론 비용과 학습 부담이 크고, 고성능 GPU가 필수라 운영 부담도 크기 때문에 공공기관의 생성형 AI로 적합하지않다.
대신 최근에는 경량화 대규모 언어 모델( sLLM, small Large Language Model) 기반 파인튜닝 전략이 주목받고 있다. sLLM은 LLM에 비해 경량화된 모델로, 파라미터가 적어 GPU 부담이 낮고, 제한된 데이터로도 도메인 특화 AI를 구현할 수 있다. 특히 검색 증강 생성 (RAG, Retrieval-Augmented Generation)과 결합하면 최신 정보를 반영하기 용이해 실무 활용도가 높다. 이러한 장점들 때문에 최근에는 sLLM의 ‘s’가 단순히 모델의 크기가 작다(small)는 의미를 넘어, 특정 도메인에 특화(specialized)된 speicalized Large Language Model 이라고 해석하기도 한다.
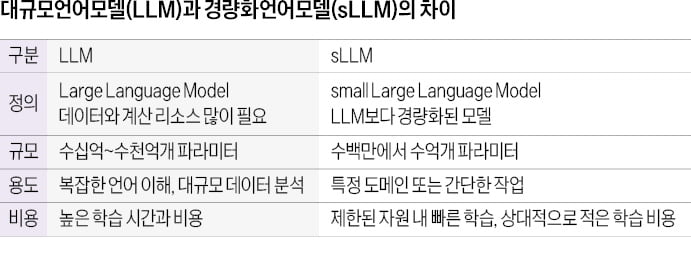
[그림1] LLM과 sLLM의 차이 (출처: 비싼 LLM 대신 싸고 빠른 sLLM 뜬다…구글·MS 속속 선보여)
- 파인튜닝의 필요성
RAG는 외부 문서를 참조해 최신 정보를 반영하고, 환각 문제를 줄이는 데 효과적이다. 그렇다면, RAG만으로 도메인 특화 AI를 구현할 수 있을 텐데, 굳이 파인튜닝이 필요할까? 정답은 ‘아니다’.
RAG는 정보를 모델에 제공할 뿐, 모델 자체의 이해력이나 추론 능력을 높이지는 못한다. 따라서 도메인 지식을 모델 내부에 정착시키고 맥락 이해와 표현 능력을 강화하려면 파인튜닝이 필요하다. 파인튜닝을 통해 모델은 도메인 이해력, 응답 품질, 그리고 효율적인 데이터 활용 능력을 갖추게 된다.
가. 도메인 이해력
파인튜닝은 모델이 특정 도메인에서 필요한 개념, 용어, 규칙, 업무 프로세스를 내부적으로 학습하도록 한다. 예를 들어 조세심판 분야 sLLM은 ‘납세자 권리’, ‘청구 절차’, ‘관련 법규’ 같은 핵심 개념을 내재화한다.이를 통해 모델은 단순히 외부 문서를 인용하는 수준을 넘어, 도메인 고유의 사고방식과 문맥까지 이해할 수 있다.결과적으로 환각 발생 위험이 낮아지고, 신뢰도 높은 응답이 가능해진다.
나. 응답 품질
파인튜닝된 모델은 도메인 질문에 대해 구체적이고 실무 중심적인 답변을 생성한다. 불필요하게 포괄적이거나 모호한 답변 대신, 업무와 분석 문맥에 적합한 정밀한 응답을 제공하며, 보고서 형식이나 어투, 문체도 일관되게 유지할 수 있다.
다. 효율적 데이터 활용
파인튜닝은 데이터 양보다 핵심 사례와 품질 중심 학습으로 성능을 극대화한다. 조세 판례 도메인에서는 소수의 중요 문서와 QA 쌍만으로도 충분히 도메인 특화 능력을 확보할 수 있다.sLLM은 핵심 지식을 내재화하고, 최신 정보는 RAG 시스템에 맡기는 구조로 효율성과 신뢰성을 동시에 달성한다.
- sLLM 파인튜닝 프로세스
sLLM을 도메인 특화 AI로 만들기 위해서는, 모델 탐색 → 데이터 준비 → 훈련/파인튜닝이라는 3단계를 체계적으로 수행하는 것이 중요하다.
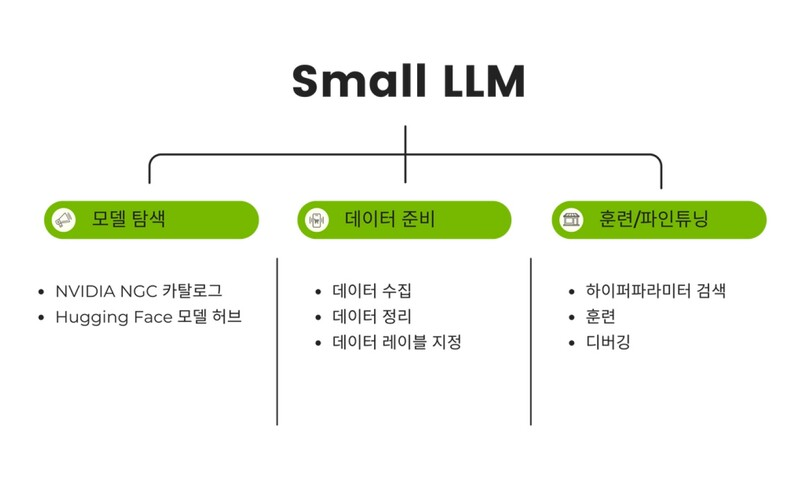
[그림2] sLLM 파인튜닝 프로세스(출처: 온프레미스 생성AI 구현에 가장 효과적인 방법 ‘sLLM’ < 솔루션가이드 < IT·산업 < 뉴스 < 기사본문 – 지티티코리아)
가. 모델 탐색
파인튜닝을 시작하기 전, 어떤 모델을 사용할지 먼저 결정해야 한다. 하드웨어 환경, VRAM, 연산량, 라이선스 조건 등을 고려하여 모델 후보군을 선정해야 한다. 여러 조건에 따라 계산식, 혹은 경험적으로 어떤 모델을 사용할 지 결정할 수도 있지만, LLM Directory: All Local LLMs List 과 같은 사이트를 활용하면 파인튜닝할 sLLM 모델을 보다 객관적으로 선정할 수 있다.
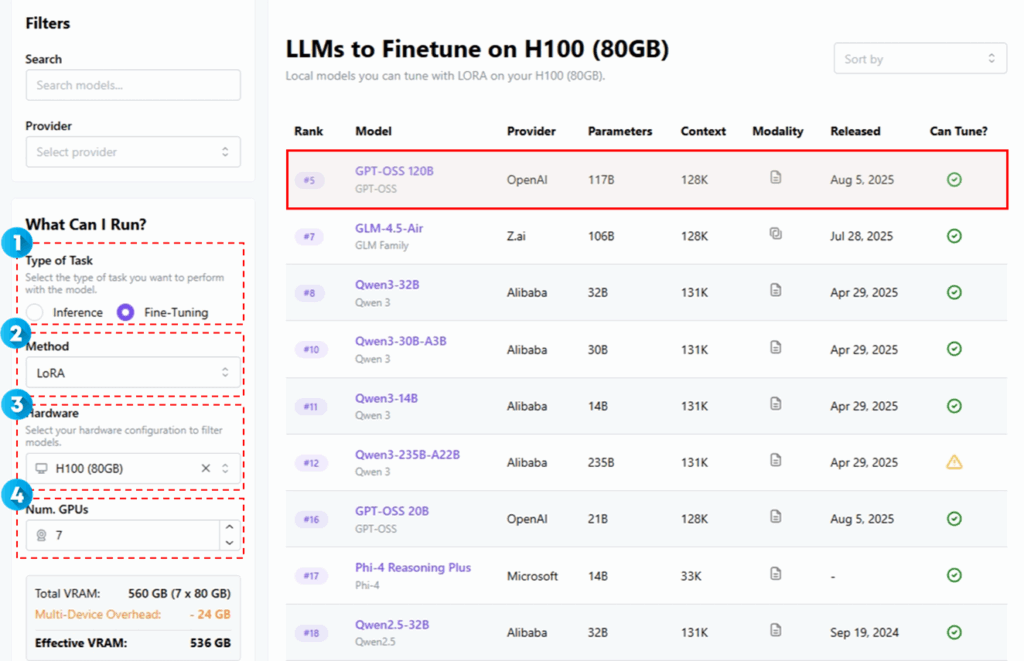
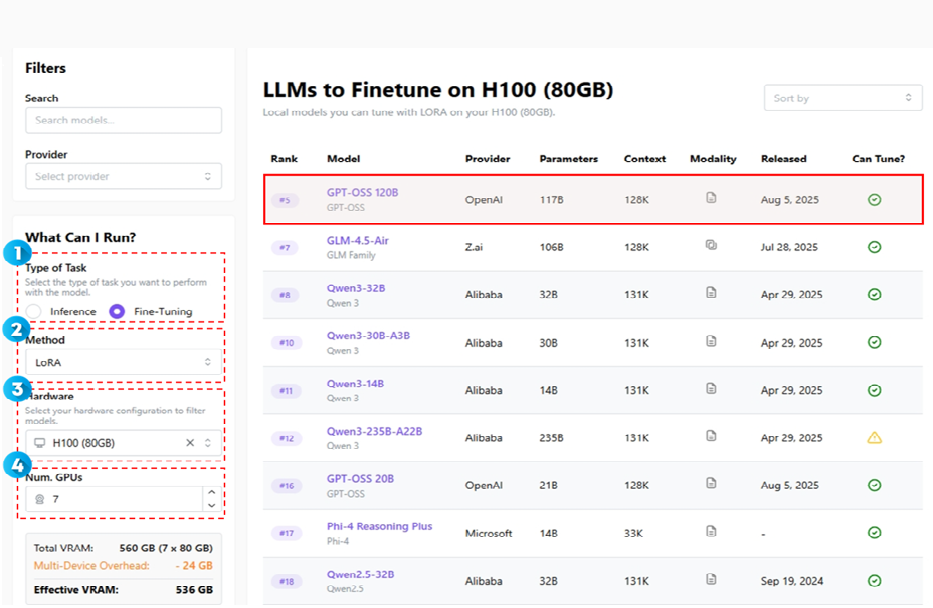
[그림3] 필터링을 통한 sLLM 파인튜닝 모델 우선순위 (출처: https://apxml.com/models)
이미지에서 빨간색 점선 상자 안의 필터 영역을 사용하여 원하는 조건에 맞는 모델 목록을 정렬할 수 있다.
- Type of Task (수행 작업 유형)
모델로 수행하려는 작업 유형을 선택하는 영역이다. sLLM의 파인튜닝을 위한 모델 선정을 위해 Fine-Tuning을 선택한다.
- Method (튜닝 방법)
파인튜닝을 수행할 구체적인 기술 또는 접근 방식을 선택하는 영역이다. 선택하는 방법에 따라 필요한 하드웨어(VRAM) 용량과 학습 속도가 크게 달라진다. Full Fine-tuning, LoRA(Low-Rank Adaptation), QLoRA(Qantization Low-Rank Adaptation) 3가지 방법이 있어 원하는 학습 방법을 선택하면 된다.
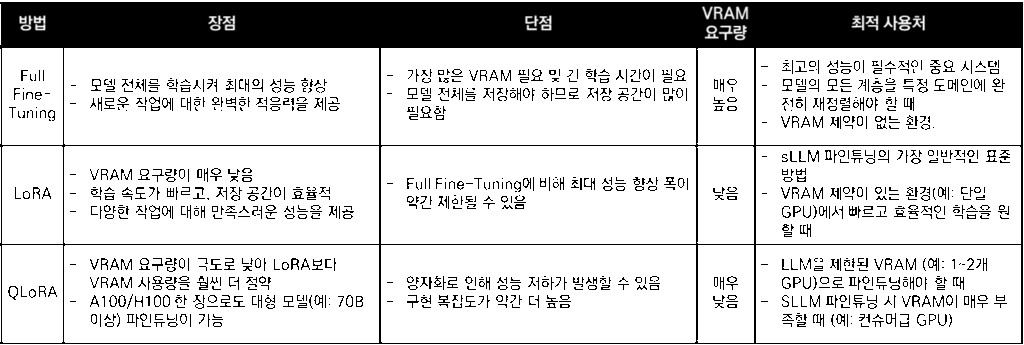
[표1] Fine-tuning 학습 방법
- Hardware (하드웨어)
파인튜닝을 진행할 GPU 유행을 선택하는 영역이다. 모델이 요구하는 VRAM 용량이 선택한 GPU의 VRAM 용량을 초과하면 파인튜닝이 불가능하거나 비효율적이 된다. 파인튜닝할 sLLM 도입 시 실제 가용할 GPU를 선택한다.
- Num. GPUs (GPU 개수)
파인튜닝에 사용할 GPU의 갯수를 선택하는 영역이다. GPU를 여러 개 사용하면 작업을 분산 처리하여 더 큰 모델을 학습시키거나 학습 속도를 높일 수 있다.
위 네 가지 조건을 적용하면, 조건에 가장 적합한 모델을 랭크순으로 정렬하여 제시되고, 이 순위를 통해 파인튜닝의 성공 가능성이 높은 모델을 객관적으로 결정할 수 있게 된다.
필터링을 통해 sLLM 파인튜닝에 사용할 모델의 최종 우선순위를 구했다면, 해당 모델의 가중치 파일과 구성 파일을 다운로드해야 한다. 이 파일들은 주로 Hugging Face 모델 허브, NVIDIA NGC 카탈로그 등에서 받을 수 있다.
실제 프로젝트 적용 사례
특정 사업 수행 과정에서, A100 80GB 단일 GPU 환경을 기반으로 최적 모델을 결정하였다. 하드웨어 제약(VRAM), 학습 방식, 모델 파라미터, 라이선스 및 기타 조건을 모두 고려한 결과, LoRA/QLoRA 기반 30B 모델이 도메인 특화 AI 구현과 운영 효율 측면에서 최적임으로 이를 활용하기로 결정하였다.
동일한 조건을 LLM Directory: All Local LLMs List에 입력하면 다음과 같이 모델이 추천된다.
| 튜닝 방식 | 적합 모델 크기 | 추천 모델 |
| Full Fine-tuning | 3~4B | Phi-4-mini, Qwen2.5-3B, Llama 3.2 3B, Gemma 3 4B 등 |
| LoRA | 20~32B | Qwen3-32B, Qwen3-30B-A3b, GPT-OSS 20B 등 |
| QLoRA | 20~32B | Qwen3-32B, Qwen3-30B-A3b, Mistral-Large-24087 등 |
[표2] Fine-tuning 학습 방법에 따른 모델 추천
Full Fine-tuning을 통해 학습할 경우, 3~4B 모델을 추천하는데, 이는 도메인 이해력과 추론 성능을 확보하는데 한계가 있어 A100 단일 GPU에서는 Full Fine-tuning이 적절하지 않음을 확인할 수 있다.
반면, LoRA/QLoRA의 경우 30~32B 모델이 추천되며, 그 중 30B 모델은 32B 모델보다 실무 적용에 있어서 VRAM 부담과 연산 효율 측면에서 더 안정적이고, 도메인 특화 능력과 성능 차이가 거의 없어 A100 단일 GPU에서 LoRA/QLoRA 기반 30B 모델이 적합함을 확인할 수 있다.
나. 데이터 준비
sLLM을 도메인 특화 AI로 만들기 위한 두 번째 핵심 단계는 데이터 준비다. 아무리 좋은 모델을 선정하고 최신 튜닝 기법을 사용하더라도, 고품질의 데이터 없이는 원하는 성능을 달성할 수 없다. 이 단계는 데이터 수집, 데이터 정리 (클리닝), 데이터 레이블 지정 (포맷팅)의 세부 과정으로 구성된다.
- 데이터 수집 (Data Collection)
파인튜닝 목적에 맞는 도메인 특화 데이터를 확보하는 과정이다. sLLM이 학습할 특정 지식, 스타일, 또는 태스크를 반영하는 원천 데이터를 수집한다. 데이터의 양적 규모뿐만 아니라 질적 적합성도 중요하므로 이를 신경써서 수집해야 한다.
- 데이터 정리 (Data Cleaning)
수집된 원천데이터를 정제하여 학습에 적합한 형태로 만드는 과정으로 노이즈 제거, 일관성 확보, 개인정보 비식별화 등을 통해 데이터 품질을 확보한다.
- 노이즈 제거: 불필요한 HTML 태그, 특수 문자, 반복되는 구문, 중복된 문장 등 제거
- 일관성 확보: 오타, 문법 오류, 사실과 다른 정보(Factual Errors)를 교정하고, 데이터의 명칭 및 형식의 일관성 유지
- 개인 정보 비식별화: 학습 데이터에 포함된 민감한 개인 식별 정보를 제거하거나 대체하여 법적, 윤리적 문제 방지
- 데이터 레이블 지정 (Data Labeling / Formatting)
정리된 데이터를 sLLM이 학습할 수 있는 입력-출력(프롬프트-응답) 쌍 형태로 변환하는 과정으로 모델이 학습해야 할 핵심정보만 남기고, 입력-출력 쌍의 길이를 효율적으로 조정하여 훈련 속도와 정확도를 높인다.
- 지도 학습 형식으로 변환: 대부분의 파인튜닝은 지도 학습(Supervised Fine-Tuning, SFT) 형태로 이루어지므로, 데이터를 모델이 따라 할 수 있는 질문(프롬프트)과 정답(응답)의 구조로 변환한다.

[그림6] 지도 학습 형식으로 변환
- 명령어 튜닝 포맷 (Instruction Tuning Format) : 사용자의 명령어를 이해하고 그에 따라 적절한 응답을 생성하도록 학습시키는 과정으로 모델에 입력되는 데이터가 모델이 특정 형식으로 학습할 수 있도록 규격화된 포맷을 가지게 구조화하는 과정이다. Alpaca, ChatML 등 다양한 포맷이 있으며 주로 Alpaca 포맷 구조가 주로 사용된다.

[표3] Alpaca 포맷 구성 요소 및 예시
다. 훈련/파인튜닝
[그림7] 파인튜닝 프로세스 개요(출처: 생성형 AI 파인튜닝 실무 시리즈: Fine-tuning GPT 실무 완벽 가이드)
- 파인튜닝 (Fine-Tuning)
파인튜닝은 모델의 가중치를 업데이트하여 도메인 특화 능력을 부여하는 핵심 과정으로, 자원 효율성의 측면에서 sLLM 도입 시 주로 PEFT (Parameter-Efficient Fine-Tuning) 기반의 LoRA/QLoRA가 사용되지만, Full Fine-Tuning 또한 프로젝트의 목표 및 가용 자원에 따라 사용된다.

[표4] 7B 모델 기준 파인튜닝 기법 비교
파인튜닝 기법 선택 후 실제 하드웨어에 적용하여, 최적의 성능을 달성하기 위해 하이퍼파라미터 검색, 훈련, 디버깅의 과정을 거친다.
- 하이퍼파라미터 검색: 모델 학습의 성능과 안정성을 극대화하는 최적의 설정 값(학습률, 배치 크기 등)을 결정하는 과정
- 모델 학습: 모델 파라미터를 실제 업데이트하고 도메인 특화 지식을 주입하는 과정 (Full Fine-Tuning, LoRA, QLoRA 등)
- 디버깅 : 훈련 중 발생하는 기술적 문제 (메모리 부족, Loss 발산 등)를 식별 및 해결하여 학습의 안정성을 확보하는 과정
| 단계 | 설명 | 모델 내 적용 방식 (예시) |
| ① 모델 로딩 및 가중치 조정 | – 선택한 sLLM(Llama 7B)을 GPU 메모리에 로딩- 학습 방법에 따라 가중치 조정 (LoRA, QLoRA : 가중치 고정) | Llama 7B (고정) |
| ② LoRA 어댑터 삽입 | – 모델 내부의 핵심 계산 영역(Attention Layer의 Q/K/V 행렬 등)에 매우 작은 크기의 두 개 행렬(어댑터 A, B) 을 추가적으로 삽입- Full Fine-tuning의 경우 모든 파라미터가 학습하므로 이 단계 제외 | LoRA A 행렬 + LoRA B 행렬 (업데이트 대상) |
| ③ 하이퍼파라미터 설정 | – 하이퍼파라미터 검색을 통해 최적화된 학습률과 배치 크기 등을 설정하여 학습 환경을 정의 | Learning Rate: Batch Size: 8 (VRAM 한계 내에서 최대치 설정) |
| ④ 모델 학습 | – 준비된 조세심판 데이터를 모델에 주입해 학습 진행 (Full Fine-tuning)- 준비된 조세심판 데이터를 모델에 주입하고, 오직 삽입된 LoRA 어댑터(A, B)만을 타겟으로 SFT(지도 학습) 진행 (LoRQ, QLoRA) | Loss가 최소화되도록 어댑터 A, B의 값만 반복적으로 조정 |
| ⑤ 디버깅 및 모니터링 | – 훈련 중 Loss 값의 추이를 모니터링하고, 메모리 부족(OOM) 등의 문제가 발생하면 적합한 대응을 통한 디버깅 수행 | OOM 발생 시 Batch Size를 4로 즉시 수정 |
| ⑥ 최종 모델 저장 | – 훈련이 완료된 후, 업데이트된 작은 LoRA 어댑터 파일만 별도로 저장하고, 어댑터 파일을 원본 모델에 결합하여 도메인 특화 sLLM 완성 | 7B 모델 파일 (수십 GB) + LoRA 파일 (수십 MB) |
[표5] 단계별 파인튜닝 방법
파인튜닝은 학습 방식에 따라 적용 범위와 자원 요구량이 상이하다. 사용 가능한 환경과 목표에 맞는 방법을 선택하여, 최적의 조건에서 파인튜닝을 수행해야 한다.
① Full Fine-tuning
모델의 모든 파라미터를 업데이트하여 도메인 특화 능력을 학습하는 방법이다. 모든 파라미터를 학습하므로 학습 범위가 넓고, 파인튜닝 구조가 단순하다.
장점
- (데이터셋 맞춤 학습) 모델의 모든 파라미터를 학습시켜 특정 분야에 대해 최적화된 답변 생성 및 제공
- (단순한 구조) 추가 장치 (어댑터 모듈, 양자화 구조, PEFT 관리 코드 등) 없이 모델 그대로 학습
단점
- (막대한 비용) 모델 전체 크기에 비례하는 막대한 VRAM과 연산 자원이 필요해 인프라 구축 비용이 높음
- (높은 학습 소요 시간) 모든 파라미터를 학습하므로 학습시간이 많이 소요됨 (수일에서 1~2주 이상)
- (치명적 망각) 특정 도메인에 맞춰 모든 파라미터를 학습하므로 기존 일반 언어 능력을 일부 상실할 가능성이 있음
막대한 비용과 치명적 망각 문제 때문에 최근 sLLM 파인튜닝에서는 잘 쓰이지 않지만, 충분한 리소스가 있거나 최고 성능이 필요한 일부 특수 상황에서는 Full Fine-tuning이 여전히 사용된다.
② LoRA (Low-Rank Adaptation)
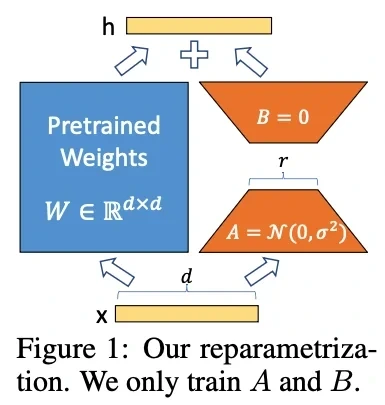
[그림8] LoRA의 개념도 (출처: LoRA: Low-Rank Adaptation of Large Language Models.,2021)
LoRA는 기존의 사전 학습 모델 가중치(W) 중 핵심적인 부분(W)은 고정한 채로, 학습이 필요한 가중치의 변화량(ΔW)을 A와 B라는 두 개의 저순위 행렬 (어댑터)로 분해하여 어댑터만 학습시키는 방식으로, 모델 전체를 업데이트 하지않고 특정 도메인에 맞춰 성능을 향상시키는 학습 방법이다.
장점
- (낮은 비용·고효율) 어댑터만 학습하기 때문에 Full Fine-tuning 대비 VRAM 사용량과 연산량이 적음 (Llama3 8B 기준 Tesla T4(15GB) 으로 학습 가능)
- (빠른 학습 및 학습 관리) 학습해야 할 파라미터 수가 매우 적어 학습 속도가 빠르고 여러 도메인별 학습 버전을 모듈처럼 관리 가능 (Llama 3 8B 기준, 10만 개 데이터 학습 9분 20초 소요)
- (원본 모델 보존) 가중치를 고정하고 일부 파라미터만 근사하기에 기본 언어 능력 손상 없음
- (단순한 구조) 모델 구조를 변경하지 않고 어댑터만 추가하기에 적용 난이도 낮음
단점
- (복잡한 패턴 학습 한계) 작은 보조 모듈만으로 모든 복잡한 패턴을 표현하기 어렵기 때문에 최대 성능이 제한됨
- (적용 범위 제한) 모델 내부 특정 핵심 레이어에만 적용하기에 모델 전체를 균등하게 조정하는데 제약있음
- (대형 모델 로딩) 모델 자체가 GPU에 올라가야 하므로 VRAM 요구량이 큼 (Llama2 7B 기준 약 30~40GB 필요)
가벼운 어댑터만 학습하므로 자원 부담이 적고 빠르게 도메인 특화 학습이 가능해 sLLM 파인튜닝에서 자주 사용되지만, 아주 세밀한 문장 구조나 복잡한 도메인 지식 학습에 한계가 있다.
③ QLoRA (Quantized Low-Rank Adaptaion)
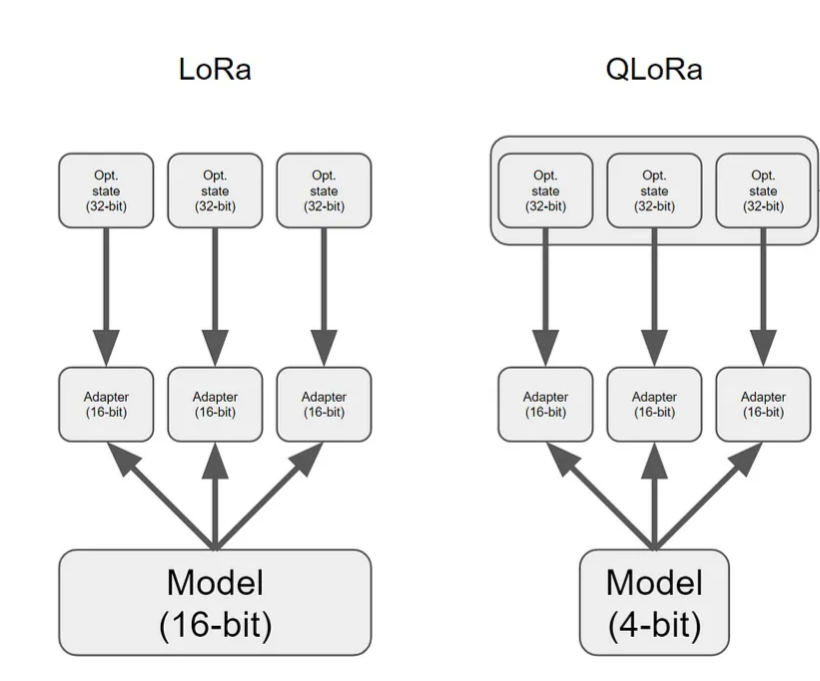
[그림9] LoRA & QLoRA (출처: QLoRA Black Boxed: A Brief Summary | by Zul Ahmed | Medium)
QLoRA는 기존 LoRA 구조는 그대로 유지하면서, 원본 모델의 가중치를 저정밀도 형태(주로 4bit)로 양자화하여 GPU 메모리 탑재한 뒤, LoRA 어댑터만 고정밀도(FP16/BF16 등)로 학습하는 파인튜닝 기법이다. 양자화된 가중치는 학습 중 업데이트되지 않기 때문에, 메모리 사용량을 크게
절약하면서도 성능 손실을 최소화할 수 있다.
| 기법 | 설명 | 특징 |
| NF4 (NormalFloat4) | 4비트 양자화, 부호+지수+정규화 기반 | 기본적으로 가장 널리 사용됨, 오류가 적고 정밀도 유지에 유리 |
| Double Quantization (DQ) | 양자화 상수(스케일 등)를 다시 양자화하여 메모리 절감 | NF4와 결합 시 메모리 효율 증가, 단일 GPU에서도 큰 모델 학습 가능 |
| FP4 / FP8 | 부동소수점 기반 양자화, 4~8비트 사용 | FP4: 메모리 절감, FP8: 정밀도 보장, 일부 성능 손실 가능 |
| FP4‑DQ / NF4‑DQ | FP4 또는 NF4 + 이중 양자화 | Double Quantization을 결합하여 메모리 효율 최대화 |
| Int4 / Int8 | 정수형 기반 양자화 | 하드웨어 친화적, GPU 연산 효율 높음, 단 일부 모델에서는 성능 저하 |
| Mixed Precision | 일부 레이어는 FP16, 일부는 4비트 양자화 | 성능 유지 + 메모리 절약 균형 |
| GPTQ (Quantization Aware) | 사전 학습된 모델 가중치를 후처리 양자화 | QLoRA에 직접 결합 가능, 더 큰 모델에서도 단일 GPU 학습 가능 |
[표6] QLoRA의 양자화 옵션
QLoRA는 4비트 NF4 양자화를 기본으로 사용하지만, 필요에 따라 FP4, Int4, Mixed Precision 등 다양한 양자화 기법과 결합할 수 있어 VRAM 요구량과 성능을 유연하게 조절할 수 있다.
장점
- (낮은 하드웨어 요구량) 모델 전체를 양자화해 단일 GPU에서도 대형 모델 학습 가능 (Llama3 8B 기준 7~10GB GPU에서 학습 가능)
- (LoRA 장점 계승) 원본 모델 보존, 단순한 구조, 도메인 모듈화 등 LoRA의 장점을 계승함
- (메모리 관리 최적화) 학습 도중 Paged Optimizer 등 메모리 관리 기법을 통해 VRAM 폭주를 방지하고 안정적으로 학습
단점
- (미세 성능 저하) 양자화로 인한 저비트 표현으로 인해 Full Fine-tuning이나 LoRA 대비 성능 저하 가능성 있음
- (계산 오버헤드) 역양자화 등 추가 연산으로 일부 상황에서 LoRA보다 학습 속도가 느려질 수 있음
- (구현 복잡도 증가) 양자화 방식 선택, 최적화기 설정, PEFT/LoRA 연동 등 추가 설정이 필요하며, VRAM 부족이나 역양자화 오류 등으로 학습중단이나 성능 예측이 어려워 디버깅 난이도가 높음
QLoRA는 LoRA의 장점을 계승하면서 대형 모델도 단일 GPU에서 학습 가능해 최근 sLLM 파인튜닝에서 널리 활용되지만, 양자화로 인한 미세한 성능 저하와 구현 복잡도가 존재한다.
+α 프루닝 (Pruning)
양자화 이후에도 sLLM의 최종적인 추론효율과 속도를 극대화하기 위해서 또 다른 경량화 전략인 프루닝(Pruning)도 고려해야 한다.
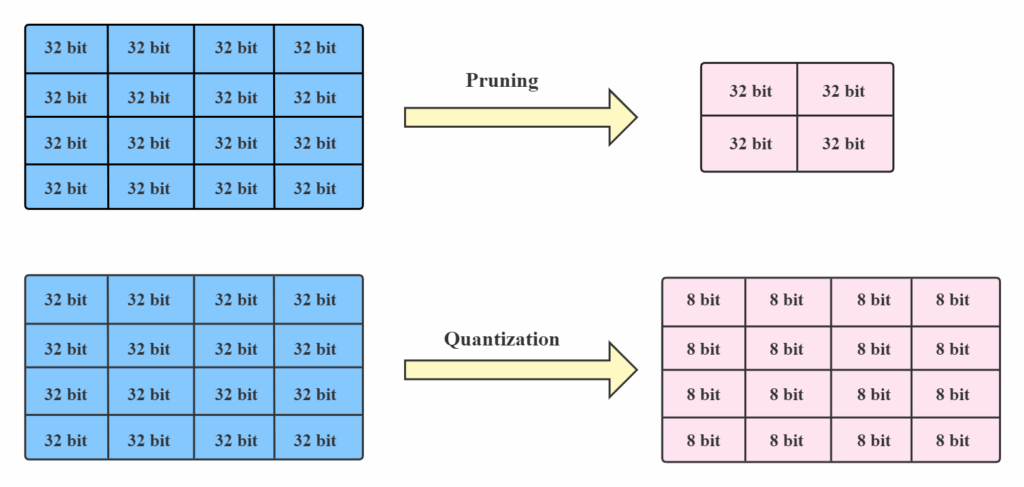
[그림10] Pruning (출처: Overview of NNI Model Compression — Neural Network Intelligence)
프루닝(Pruning)은 불필요한 파라미터를 제거해 모델 경량화와 추론 속도 향상을 달성하는 기술이다. 하지만 LoRA/QLoRA 적용 시 학습 도중에 이를 수행하면, 어댑터의 학습 공간이 줄어들어 성능 저하로 이어질 수 있다. 따라서 최적의 성능을 위해서는 반드시 학습이 완료된 후에 프루닝을 적용해야 한다.
| 프루닝 기법 | 설명 / 특징 |
| Structured Pruning | 레이어, 채널, 유닛 단위로 중요도 낮은 파라미터 제거. GPU 친화적, 추론 속도 향상 |
| Unstructured Pruning | 개별 가중치 수준에서 중요도 낮은 파라미터 제거. 자유도 높지만 LoRA/QLoRA 환경에서는 병합 및 추론 효율 |
| Magnitude Pruning | 절댓값 기준으로 작은 ΔW (LoRA) 또는 가중치(QLoRA) 제거. 간단하고 직관적, 일부 성능 손실 가능 |
[표7] LoRA/QLoRA 적용 시 적용 가능한 프루닝 기법
- 프롬프트 엔지니어링 (Prompt Engineering)
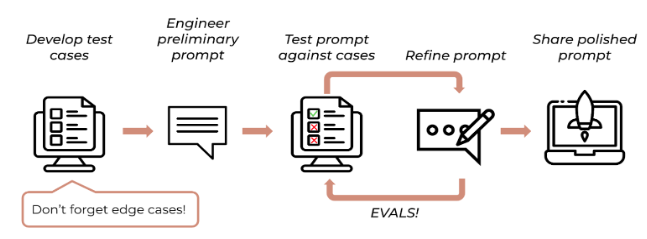
[그림11] 프롬프트 엔지니어링 프로세스 (출처: 클로드(Claude) 프롬프트 엔지니어링 완벽 가이드 | 프롬프트해커 대니)
프롬프트 엔지니어링은 모델에게 원하는 방식으로 답변을 생성하도록 입력 문장을 설계하는 기법으로, 실무에서 높은 성능을 발휘하도록 이를 체계적으로 최적화하는것이 중요하다.
① 프롬프트 엔지니어링 단계별 프로세스
- Develop Test Cases
– 모델이 수행해야 하는 실제 태스크와 시나리오를 정의, 다양한 입력 예시와 기대 출력 형태를 포함
– 모델이 실제 업무에서 기대한 성능을 발휘하는지 사전에 검증할 수 있도록 기준을 마련
– 예시: “청구이유서를 요약해서 핵심 쟁점과 사건번호를 표로 정리하는 태스크” → 각 케이스마다 입력 문서와 기대 요약 형태 준비
- Engineer Preliminary Prompt
– 초기 프롬프트 설계, 모델이 수행할 작업과 형식, 제약 조건 포함
– 모델에게 정확한 작업 지시를 제공하여, 불필요한 해석 오류를 줄이고 일관된 출력 확보
– 예시: “아래 청구이유서 내용을 요약하고, 핵심 쟁점과 사건번호만 표로 정리하라”
- Test Prompt Against Cases ↔ Refine Prompt
– 초기 프롬프트를 테스트 케이스에 적용하고, 결과를 분석하여 반복적으로 수정
– 실제 케이스에서 예상과 다른 출력이 발생할 수 있으므로, 반복 개선을 통해 프롬프트 품질 향상
– 예시: 샘플 청구이유서 2~3개 적용 → 모델 출력 확인 → 문장 표현, 조건 등을 조정
- Share Polished Prompt
– 최종 검증 완료 후 안정적이고 반복 사용 가능한 프롬프트 확정 및 배포
– 표준화된 프롬프트를 제공하여, 업무 효율성과 일관성 확보
– 예시: 최종 요약 프롬프트 공유, 표준 사용 지침 마련
위 단계들을 통해 프롬프트의 구조와 방향성을 확립한 후, 실제 업무에 적용 가능한 구체적인 방법론을 적용하면 모델 출력의 일관성과 정확도를 더욱 높일 수 있다.
② 프롬프트 엔지니어링 방법론
| 구분 | 설명 | 적용 예시 |
| Instruction 기반 설계 | 모델에게 수행할 작업과 형식을 명확히 지시 | “다음 청구이유서를 5줄 요약하고, 핵심 쟁점과 사건번호만 표로 정리하라. 민감정보는 삭제” |
| Few-shot / Example 포함 | 입력에 샘플 사례를 제공하여 모델이 패턴을 학습하도록 유도 | 2~3개의 실제 청구이유서 요약 사례를 포함 → 모델이 유사한 구조로 요약하도록 학습 |
| Context / Constraint 명시 | 모델이 답변할 때 고려할 조건, 범위, 형식 명시 | “표 형식으로 출력, 각 사건번호별 요약 제공, 총 10줄 이내” |
| Iterative Refinement | 모델 출력 결과를 보고 프롬프트를 반복적으로 수정 | 초기 요약 출력 결과에서 불필요 문장 제거, 요약 방식 조정 → 반복 적용 후 최종 프롬프트 확정 |
[표8] 프롬프트 엔지니어링 방법론 및 예시
이처럼 체계적인 프롬프트 엔지니어링을 수행함으로써, sLLM이 실제 업무에서 요구되는 정확성과 일관성을 안정적으로 유지할 수 있고, 도메인 특화 AI를 실무에 완벽하게 적용할 수 있게 된다.
- 결론
지금까지 sLLM 기반 도메인 특화 AI를 구축하기 위한 파인튜닝 방법론을 체계적으로 살펴보았다. 모델 선정, 데이터 준비, Full Fine-tuning / LoRA / QLoRA 등 파인튜닝 방법론, 학습 후 프루닝 적용, 프롬프트 엔지니어링까지, 실무에서 sLLM을 효과적으로 활용하기 위한 핵심 과정을 단계별로 정리하였다. 이를 통해 실무 환경에서도 안정적이고 효율적인 도메인 특화 AI 구현이 가능함을 확인할 수 있었다.
최근 sLLM 도입 사례를 보면, 단순한 모델 경량화에 그치지 않고 특정 업무와 도메인에 맞춘 맞춤형 AI를 구현하려는 시도가 늘어나고 있다. 특히 학습 효율과 응답 신뢰도를 동시에 고려한 파인튜닝 전략은, 제한된 자원 환경에서도 실무적으로 유용하게 활용될 수 있다는 점을 보여준다. 따라서 각 조직과 환경에 맞는 파인튜닝 방법론을 찾아내어 실무에 적절히 적용해야 한다.
참고문헌
- LoRA: Low-Rank Adaptation of Large Language Models : https://arxiv.org/abs/2106.09685
- Fine-tuning LLaMA 3 with LoRA Adapters : https://aispectrum.io/llama-training
LoRAPrune: Structured Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning : https://arxiv.org/abs/2305.18403