
“사자 그림을 그려줘” 라고 요청하면 멋진 사자를 그려주지만, “정면을 응시하는 사자를 그려줘”라고 하면 여전히 옆모습이나 뒷모습의 사자가 나오는 경우가 많습니다.
Stable Diffusion을 사용해보신 분이라면 이런 답답함을 경험해보셨을 겁니다. 원하는 자세, 구도, 레이아웃을 텍스트로 설명하는 것은 생각보다 훨씬 어렵고, 결국 수십 번의 재생성을 반복하게 됩니다.
ControlNet은 바로 이 문제를 해결하기 위해 등장했습니다.
1. ControlNet 소개
1). 핵심 주장
ControlNet은 대규모 사전학습된 text-to-image diffusion model에 공간 조건 제어를 추가하는 신경망 구조입니다. 여기서 공간 조건 제어란 사용자가 생성될 이미지의 공간적 배치, 구조, 형태 등을 정밀하게 제어할 수 있는 조건부 입력을 의미합니다.
기존 text-to-image diffusion model의 근본적인 한계는 텍스트 프롬프트만으로는 정확한 공간적 구성을 제어하기 어렵다는 점입니다. 자세뿐만 아니라 배경이나 인물까지도 모두 무작위로 생성되기 때문에 생성되는 이미지가 원하는 구도와 자세를 갖도록 하는 것은 어렵습니다. 해결 방법은 그저 이미지를 많이 생성해보는 것뿐입니다.
ControlNet은 이러한 문제를 해결하기 위해 추가 조건 이미지(Canny edge, human pose skeleton, segmentation map, depth map 등)를 통해 세밀한 공간 제어를 가능하게 합니다. 핵심 아이디어는 상용 수준의 대규모 diffusion model의 파라미터를 freeze하고, 이를 학습 가능한 복사본(trainable copy)와 연결하여 다양한 조건부 제어를 학습하는 것입니다.
2). 아키텍처
ControlNet의 architecture는 세 가지 핵심 구성요소로 이루어집니다.
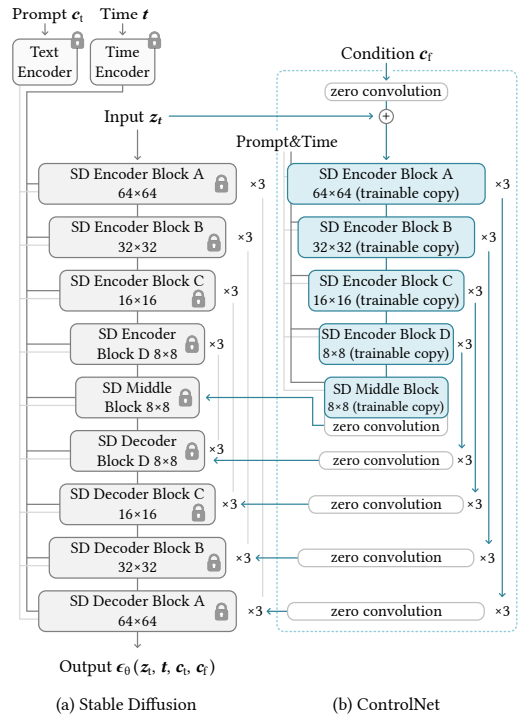
(1) 고정된 사전학습 모델과 학습 가능한 복사본
ControlNet은 대규모 사전학습 모델(Stable Diffusion)의 encoding layer를 두 부분으로 분리합니다. 첫 번째는 고정된 매개변수(Θ)로, 수십억 장의 이미지로 학습된 원본 모델의 매개변수를 그대로 동결합니다. 두 번째는 학습 가능한 복사본(Θc)으로, 원본 인코더를 그대로 복제하여 조건부 제어 학습에 사용합니다.
이러한 구조 덕분에 사전학습 모델의 품질과 능력을 보존하면서도, 대규모 사전학습 백본을 재사용하여 강건한 특징 추출이 가능해집니다.
수식으로 표현하면, 기존 신경망 블록이 다음과 같이 동작할 때:
y=F(x;Θ)
ControlNet은 다음과 같이 확장됩니다.
yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
여기서 c는 조건 벡터, Z(⋅;⋅)는 zero convolution layer를 의미합니다.
(2) Zero Convolution Layers
Zero convolution은 ControlNet의 가장 독창적인 설계 요소입니다. 이는 가중치와 편향이 모두 0으로 초기화된 1×1 합성곱 계층으로, 학습 가능한 복사본과 고정된 모델을 연결하는 역할을 합니다.
초기 학습 단계에서는 다음과 같은 효과가 나타납니다:
Z(c;Θz1)=0 and Z(⋅;Θz2)=0
따라서 첫 학습 단계에서는
yc=y
즉, 조건이 추가되기 전과 완전히 동일한 출력이 나옵니다.
이를 통해 세 가지 중요한 효과를 얻을 수 있습니다. 첫째, 유해한 잡음 방지로 학습 초기에 무작위 잡음이 사전학습 모델의 은닉 상태를 손상시키는 것을 막습니다. 둘째, 사전학습 백본(backbone) 보호를 통해 학습 가능한 복사본이 원본 모델의 능력을 완전히 유지한 채로 학습을 시작할 수 있습니다. 셋째, 점진적 매개변수 성장으로 zero에서 시작하여 점진적으로 매개변수가 의미 있는 값으로 성장합니다.
(3) U-Net 통합
Stable Diffusion의 U-Net 구조에 ControlNet을 적용하는 방식은 다음과 같습니다. 인코더 블록은 4가지 해상도(64×64, 32×32, 16×16, 8×8)에서 각각 3번씩 반복되어 총 12개의 인코딩 블록을 구성하고, 중간 블록은 1개의 중간 처리 블록으로 구성됩니다. 이렇게 생성된 각 인코더 블록과 중간 블록의 출력은 U-Net의 스킵 연결과 중간 블록에 직접 추가되는 방식으로 통합됩니다.
3). Diffusion Model 대비 장점
(1) Catastrophic Forgetting 방지
일반적인 fine-tuning은 제한된 task-specific 데이터(<50K)로 대규모 사전학습 모델을 직접 fine-tuning하면 과적합과 catastrophic forgetting이 발생한다는 점입니다. 예를 들어, Stable Diffusion은 LAION-5B(50억 이미지)로 학습되었지만, 특정 조건(깊이, 포즈 등)을 위한 데이터셋은 보통 10만 장 규모로 약 5만 분의 1 수준에 불과합니다.
ControlNet은 이러한 문제를 해결하기 위해 고정된 매개변수로 원본 모델의 지식을 완전히 보존하고, Zero convolution으로 학습 초기의 gradient 불안정성을 제거합니다. 또한 학습 가능한 복사본이 task-specific control만 학습하도록 설계되어 있습니다.
(2) 데이터 확장성과 강건성
ControlNet은 다양한 데이터셋 크기에서 강건한 성능을 보입니다.
- 소규모 데이터셋 (<1K): 모델이 붕괴하지 않고 기본적인 의미 파악 가능
- 중간 규모 데이터셋 (~50K): 고품질 결과 생성
- 대규모 데이터셋 (>1M): 산업 수준 성능 달성
실제 실험 결과를 보면, 깊이-이미지 변환 과제에서 20만 학습 샘플만으로도 1,200만 장 이상의 이미지로 학습된 Stable Diffusion V2 깊이-이미지 모델과 거의 구별 불가능한 결과를 생성했습니다(사용자 연구 정밀도: 0.52 ± 0.17).
(3) Multiple Condition 합성
ControlNet의 또 다른 강점은 여러 조건을 동시에 적용할 수 있다는 점입니다. 별도의 복잡한 가중치 조정이나 선형 보간이 필요 없이, 단순히 여러 ControlNet의 출력을 Stable Diffusion에 더하기만 하면 됩니다. 예를 들어, 포즈와 깊이 정보를 동시에 제어하여 더욱 정밀한 이미지 생성이 가능합니다.
4). 기여도
(1) 구조적 혁신
- Zero convolution mechanism: 신경망 가중치 초기화의 새로운 접근법 제시
- Locked-copy paradigm: 대규모 사전학습 모델을 효율적으로 재사용하는 일반적인 프레임워크
- Stable training protocol: 제한된 데이터로도 대규모 모델을 안정적으로 fine-tuning 가능
(2) 실용적 영향
ControlNet은 8가지 조건 유형을 지원합니다: Canny 엣지 검출, Hough 선분 검출, 사용자 스케치, 인체 관절점(OpenPose), 의미론적 분할(ADE20K), 표면 법선 맵, 깊이 맵, 만화 선화. 이러한 다양한 조건 지원을 통해 실무에서 즉시 활용 가능한 수준의 제어력을 제공합니다.
(3) Prompt-Free Generation Capability
ControlNet의 흥미로운 특징 중 하나는 텍스트 프롬프트 없이도 조건 이미지만으로 의미를 파악하여 고품질 이미지를 생성할 수 있다는 점입니다. 이는 학습 시 50%의 텍스트 프롬프트를 빈 문자열로 대체하는 전략을 통해 달성되었으며, 모델이 조건 이미지에서 직접 내용의 의미를 인식하도록 학습됩니다.
실제로 네 가지 프롬프트 설정(프롬프트 없음, 불충분한 프롬프트, 상충하는 프롬프트, 완벽한 프롬프트)에서 모두 강건한 성능을 유지했습니다. 이는 ControlNet이 단순히 텍스트에 의존하는 것이 아니라, 조건 이미지 자체에서 의미를 추출할 수 있음을 보여줍니다.
2. 구글 코랩(Google Colab) 환경에서 ControlNet 추론 실습
지금까지 ControlNet의 핵심 개념과 구조적 특징, 그리고 기존 확산 모델 대비 장점을 살펴보았습니다. 이론적 배경을 이해했으니, 이제 실제로 사전학습된 ControlNet 모델을 구글 코랩(Google Colab) 환경에서 직접 실행해보며 그 강력함을 체험해보겠습니다.
ControlNet이 제공하는 8가지 조건 유형 중, 이번 실습에서는 Canny 엣지와 Scribble 모델을 사용하여 테스트 이미지로 추론을 수행해보았습니다.
1). 파일 준비
먼저 필요한 파일들을 준비해야 합니다. ControlNet의 코드는 공개되어 있으므로, https://github.com/lllyasviel/ControlNet에서 저장소를 git clone하거나 파일로 다운로드하여 구글 드라이브에 업로드합니다.
다음으로 사전학습된 모델을 준비합니다. https://huggingface.co/lllyasviel/ControlNet에서 필요한 모델 파일을 다운로드하여 models 폴더에 저장합니다. 이번 실습에서는 control_sd15_canny.pth와 control_sd15_scribble.pth 두 모델을 사용했습니다.
마지막으로 추론에 사용할 테스트 이미지를 준비합니다. 저는 Freepik에서 무료 라이선스 이미지를 다운로드하고, 그림판에서 직접 선으로 간단하게 그린 그림을 test_imgs 폴더에 저장했습니다.

2). 환경 설정
구글 코랩에는 기본적인 라이브러리가 이미 설치되어 있지만, ControlNet 추론을 위해서는 몇 가지 추가 라이브러리를 설치해야 합니다. 특히 추론 시 GPU 메모리가 약 20GB 이상 필요하므로, 이번 실습에서는 A100 GPU를 사용했습니다.
필요한 라이브러리 설치 후, 구글 드라이브를 마운트하고 작업 디렉토리를 설정합니다.
| # 구글 드라이브 연동 from google.colab import drive drive.mount(‘/content/drive’) import osmydrive_path = ‘/ControlNet’ # 코드가 있는 폴더 지정 gg_drive_path = os.path.join(‘/content/drive/MyDrive’, mydrive_path) # 작업 디렉토리 변경 os.chdir(gg_drive_path) # 필요 라이브러리 설치 !pip install -q \ pytorch-lightning==1.5.0 \ open_clip_torch==2.0.2 |
3). 추론 코드 실행(Canny 조건)
추론을 위한 주요 설정값들을 지정합니다. 테스트 이미지의 경로, 텍스트 프롬프트, 생성할 이미지 개수, 시드값 등을 원하는 대로 설정할 수 있습니다.
설정이 완료되면 추론 코드를 실행합니다. ControlNet은 입력 이미지의 구조적 정보(엣지, 스케치 등)를 추출하고, 이를 조건으로 사용하여 텍스트 프롬프트에 맞는 새로운 이미지를 생성합니다.
| import cv2 import einops import numpy as np import torchfrom PIL import Imagefrom pytorch_lightning import seed_everything from annotator.util import resize_image, HWC3 from annotator.canny import CannyDetector from cldm.model import create_model, load_state_dict from cldm.ddim_hacked import DDIMSampler import config import os # 모델 로드apply_canny = CannyDetector() model = create_model(‘./models/cldm_v15.yaml’).cpu() model.load_state_dict(load_state_dict(‘./models/control_sd15_canny.pth’, location=’cuda’), strict=False) model = model.cuda()ddim_sampler = DDIMSampler(model) # 입력 설정 input_image = cv2.imread(‘test_imgs/big_tree.jpg’) # 이미지 경로 input_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2RGB) # OpenCV는 BGR이므로 RGB로 변환 prompt = “Christmas, a giant decorated Christmas tree, glowing lights, snowflakes falling, warm holiday atmosphere, cinematic lighting” # 생성할 이미지 설명 a_prompt = “best quality, masterpiece, ultra-detailed, realistic lighting, highly detailed background, soft snow, warm tone, holiday illumination, photorealistic, vibrant color, depth of field” # 추가 품질 프롬프트 n_prompt = “longbody, lowres, bad anatomy, bad hands, missing fingers” # 피하고 싶은 요소들 num_samples = 4 # 생성 이미지 개수 image_resolution = 512 # 생성 이미지 해상도 ddim_steps = 20 # Diffusion 단계 수(클수록 품질↑, 속도↓) strength = 1.0 # 입력 이미지(조건)의 영향력 (1이면 강하게, 0에 가까우면 약하게) scale = 9.0 # CFG scale: 프롬프트 준수 정도(높을수록 프롬프트에 충실) seed = 42 # 랜덤 시드(이미지 재현성 확보) eta = 0.0 # DDIM η (일반적으로 0 유지) — 0이면 deterministic sampling low_threshold = 100 # Canny low threshold: 감지 민감도(낮을수록 더 많은 edge) high_threshold = 200 # Canny high threshold: edge 확정 기준(높을수록 강한 edge만 사용) # 추론 with torch.no_grad(): img = resize_image(HWC3(input_image), image_resolution) H, W, C = img.shape detected_map = apply_canny(img, low_threshold, high_threshold) detected_map = HWC3(detected_map) control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0 control = torch.stack([control for _ in range(num_samples)], dim=0) control = einops.rearrange(control, ‘b h w c -> b c h w’).clone() seed_everything(seed) cond = {“c_concat”: [control], “c_crossattn”: [model.get_learned_conditioning([prompt + ‘, ‘ + a_prompt] * num_samples)]} un_cond = {“c_concat”: [control], “c_crossattn”: [model.get_learned_conditioning([n_prompt] * num_samples)]} shape = (4, H // 8, W // 8) model.control_scales = [strength] * 13 samples, _ = ddim_sampler.sample(ddim_steps, num_samples, shape, cond, verbose=False, eta=eta, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond) x_samples = model.decode_first_stage(samples) x_samples = (einops.rearrange(x_samples, ‘b c h w -> b h w c’) * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8) # 결과 저장 (자동 넘버링) os.makedirs(‘outputs’, exist_ok=True) for i in range(num_samples): result = Image.fromarray(x_samples[i]) filename = f’outputs/output_test{i+1}.png’ result.save(filename) print(f”결과 이미지가 {filename}에 저장되었습니다.”) |
4). 추론 결과
(1) Canny 조건
실제 추론 결과를 살펴보겠습니다. 초록빛이 짙은 푸릇푸릇한 나무 사진을 입력 이미지로 사용하고, 이를 눈으로 뒤덮인 겨울 나무로 변환하고자 했습니다. 이를 위해 “Christmas, a giant decorated Christmas tree, glowing lights, snowflakes falling, warm holiday atmosphere, cinematic lighting”이라는 프롬프트를 입력했습니다.
그 결과, 원본 이미지(좌)의 구조적 특징을 유지하면서 프롬프트를 반영한 4가지 변형 이미지(우)가 생성되었습니다. 나무의 전체적인 형태와 가지의 배치는 원본과 동일하게 유지되면서도, 크리스마스 분위기의 장식과 눈, 조명 효과가 자연스럽게 추가된 것을 확인할 수 있습니다.

(2) Scribble 조건
Scribble 모델을 사용한 추론 과정도 Canny와 거의 동일합니다. 다만 사전학습 모델을 control_sd15_scribble.pth로 변경하고, 입력 이미지로는 선(line)으로 그려진 스케치 이미지를 사용한다는 점이 다릅니다.
Scribble 모델은 Canny 엣지에 비해 더 자유로운 형태의 스케치에서도 작동하므로, 사용자가 직접 그린 러프한 스케치만으로도 원하는 이미지를 생성할 수 있다는 장점이 있습니다. 실제로 생성된 결과 이미지들을 보면, 간단한 선화 스케치가 디테일한 크리스마스 트리 이미지로 변환된 것을 확인할 수 있습니다.
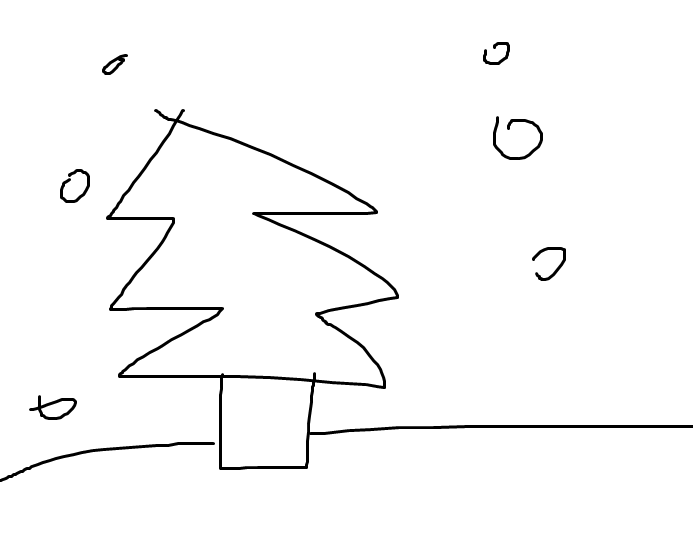
<원본>

<생성 이미지>
그림판으로 대충 그린 간단한 스케치가 겨울 분위기가 짙은 크리스마스 트리 이미지로 변환되었습니다. 다만 흥미로운 점은, 제가 그린 삼각형 형태의 트리를 모델이 나무로 정확히 인식하지 못하고 눈이 쌓인 건축물이나 구조물로 해석했다는 것입니다. 이는 Scribble 조건이 매우 추상적인 형태에서 작동하기 때문에, 프롬프트와 스케치의 명확성이 결과에 큰 영향을 미칠 수 있음을 보여줍니다.
마무리
이번 글에서는 ControlNet의 핵심 아이디어와 구조적 특징을 살펴보고, 실제로 구글 코랩 환경에서 추론을 수행해보았습니다. ControlNet은 Zero Convolution Layers라는 독창적인 메커니즘을 통해 대규모 사전학습 모델의 지식을 보존하면서도 새로운 조건부 제어를 효과적으로 학습할 수 있음을 보여주었습니다.
특히 텍스트만으로는 표현하기 어려웠던 정확한 공간적 구성, 자세, 레이아웃 등을 조건 이미지를 통해 직관적으로 제어할 수 있다는 점에서 큰 의미가 있습니다. 단순히 “나무 그림”을 생성하는 것을 넘어, “이 나무의 형태를 유지하면서 겨울 분위기로”와 같은 세밀한 제어가 가능해진 것입니다.
ControlNet의 등장으로 text-to-image 생성 모델은 단순한 창작 도구를 넘어 실용적인 디자인 도구로 한 걸음 더 나아갔습니다. 여러분도 직접 다양한 조건 유형(포즈, 깊이, 분할 등)을 실험해보며 ControlNet의 가능성을 탐구해보시기 바랍니다.
참고문헌
논문
- Zhang, L., Rao, A., & Agrawala, M. (2023). Adding Conditional Control to Text-to-Image Diffusion Models. arXiv preprint arXiv:2302.05543.
공식 저장소
- GitHub: https://github.com/lllyasviel/ControlNet
- Hugging Face: https://huggingface.co/lllyasviel/ControlNet
기타 자료
- Stable Diffusion: https://github.com/Stability-AI/stablediffusion