‘법률적 판단과 심의를 수행하는 범용 공공기관’ (예: 행정심판위원회, 분쟁조정위원회, 징계위원회, 인허가 심사기관 등)을 대상으로 AI 에이전트 인프라 구축 과정을 기술함.
1. 프로젝트 비전: “저부가가치 반복 업무 개선을 통한 업무 생산성 향상”
문제 정의: “폭증하는 사건, 한정된 심사 인력”
기관은 국민의 권리 구제와 공정한 법 집행을 위해 존재한다. 그러나 매년 접수되는 심사/청구 건수는 폭증하는 반면, 이를 검토할 전문 인력은 한정적이다. 심사관들은 방대한 증거 기록 열람, 법령 검색, 사실관계 정리 등 물리적인 서류 작업에 매몰되어, 정작 가장 중요한 ‘법리적 판단’에 쏟을 시간이 부족한 실정이다.
심사관들의 생성형 AI 사용은 업무에 전혀 사용하지 않는 심사관들부터 파워유저까지 다양하며, 생성형 AI에게 법리적인 심층 검토를 기대하기 보다는 단순한 사실관계 정리, 판례 검색 등 저부가가치 반복 업무를 개선하여 업무 생산성을 높이는 데 있다.
도입 목표: “최고의 행정 전문가를 ‘디지털’로 복제하다”
본 프로젝트의 목표는 단순히 챗봇을 도입하는 것이 아니다. 기관의 숙련관이 가진 노하우와 판단 논리를 학습한 ’70B급 AI 에이전트’를 구축하여, 내부적으로는 업무 생산성을 극대화하고 외부적으로는 대국민 행정 서비스의 질을 혁신하는 것이다.
핵심 구축 과제(Technical Goals)
| 구축 과제 | 구축 내용 |
| 고성능 연산 인프라 | 70B 모델의 실시간 추론(Inference)과 파인튜닝(Fine-tuning)을 감당할 GPU 클러스터 구축 |
| 법률 특화 sLLM | 한국어 법률 용어와 행정 논리에 특화된 Open Source LLM(70B) 기반 자체 모델 개발 |
| 대규모 벡터 저장소 | 수십만 건의 비정형 판례/결정례를 벡터화하여 검색할 Enterprise Vector DB 구축 |
2. 시스템 아키텍처: “강력한 지능(Brain)을 중심으로 한 통합 플랫폼”
현재 대부분의 공공기관은 물리적 망 분리 정책으로 인해 내부망(업무망)과 외부망(인터넷)이 단절되어 있다. 이로 인해 내부의 방대한 행정 데이터가 대국민 서비스에 활용되지 못하고 고립되어 있으며, 공무원들은 외부의 최신 AI 기술(ChatGPT 등)을 업무에 도입하지 못하는 ‘이중 제약’ 상황에 처해 있다.
현재 담당관들은 내부망 PC에서 문서를 작성하다가 AI의 도움이 필요하면 인터넷망 PC로 전환하여 ChatGPT 등을 사용하고 있다.
| 제약 사항 | 세부 내용 |
| 업무 비효율 | 내부 데이터를 외부 AI에 입력하기 위해 수동으로 타이핑하거나, USB/망연계 승인을 기다려야 하는 워크플로우의 단절이 발생함 |
| 보안 리스크 | 인터넷망 PC에서 외부 AI 사용 시, 업무 편의를 위해 무의식적으로 민감 정보(이름, 사건번호 등)를 입력할 위험이 상존함 |
| 데이터 활용 한계 | 내부망에 축적된 방대한 행정 데이터(재결서, 노하우)는 인터넷이 차단되어 있어 외부 AI가 전혀 학습하거나 참조할 수 없음 |
물리적 망분리 환경(내부/외부)은 존재하지만, AI 에이전트는 이를 관통하여 하나의 통합된 지능으로 기능하다.
| 구성 요소 | 내용 |
| The Brain (Intelligence Core) | 70B On-Premise sLLM(Specialized Large Language Model, 내부망): 인터넷 연결 없이도 우리 기관 소관 법령, 내부 심사 지침, 비공개 선례를 완벽히 학습한 ‘법률 특화 두뇌’ |
| The Workflow (Dual Interface) | • Officer Agent (내부망): 심사관의 PC에서 사건 기록을 독해하고, 쟁점을 추출하여 [심사 보고서] 초안을 작성함• Public Agent (외부망): 법률 용어가 낯선 국민에게 청구서 작성을 도와주고, 진행 상황을 알기 쉽게 설명함 |
| The Secure Bridge | 외부의 신청 데이터를 내부로 안전하게 반입하고, 내부의 심사 결과를 비식별화하여 외부로 통지하는 자동화된 데이터 파이프라인 |
하드웨어(H/W) 아키텍처: “AI 전용 고밀도 서버 구성”
| 구분 | 도입 사양 (Spec) | 선정 사유 |
| GPU 서버 | NVIDIA H200 (141GB) x 2EA (또는 L40S x 4EA) | • 70B 모델의 원활한 추론을 위해 최소 140GB 이상의 VRAM 필요• H200은 대역폭이 높아 다수 사용자 동시 접속(Concurrency) 처리에 유리함 |
| CPU/RAM | Intel Xeon Platinum / 1TB RAM | • 벡터 DB의 인메모리 검색 속도 보장 및 대용량 데이터 전처리용 |
| Storage | NVMe SSD 10TB (All-Flash) | • 수십만 건의 PDF 문서 파싱 및 벡터 인덱싱을 위한 고속 I/O 필수 |
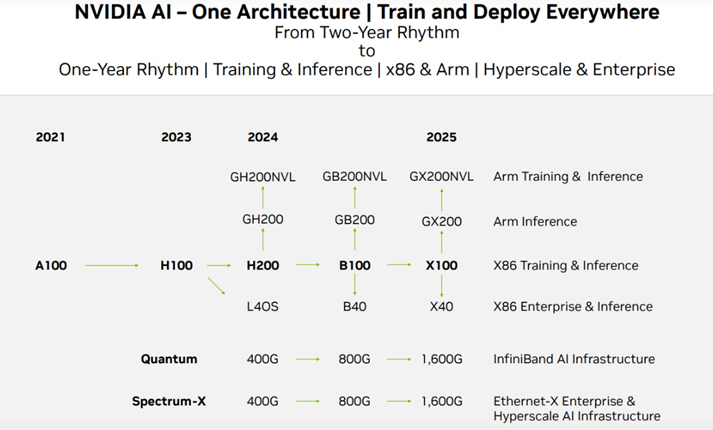
📊 NVIDIA 주요 GPU 아키텍처 비교표

NVIDIA GPU 로드맵
- Hopper (H100, H200): “거대 AI 학습 전용” (HBM 메모리 탑재, 그래픽 기능 없음)
- Blackwell (B100, B200): “Hopper의 뒤를 잇는 차세대 초거대 AI 학습/추론 아키텍처“
- Ada Lovelace (L40S, RTX 4090): “AI 추론(서비스) 및 그래픽/3D 특화” (GDDR6 메모리 탑재, 가성비 좋음)
| 구분 | Hopper | Ada Lovelace | Blackwell |
| 대표 모델 | H100 / H200 | L40S / RTX 4090 / RTX 6000 Ada | B200 / GB200 |
| 주요 용도 | 초거대 AI 학습(Training) 및 HPC | AI 추론(Inference), 3D 렌더링, 시뮬레이션 | 차세대 AI 학습 및 추론 (최상위) |
| 메모리 타입 | HBM3 / HBM3e | GDDR6 / GDDR6X | HBM3e |
| 메모리 용량 | H200: 141GB | L40S: 48GB | B200: 192GB |
| 특징 (Architecture) | • 4세대 Tensor Core • DPX 명령어(다이나믹 프로그래밍) | • 3세대 RT Core • 4세대 Tensor Core • DLSS 3.0 | • 2세대 Transformer Engine • 5세대 Tensor Core • 칩-투-칩 설계 (CoWoS) |
| 포지션 | 현세대 AI 학습 플래그십 | 다목적 Workhorse H100 부족시 대안으로 많이 사용됨 | 차세대 AI 플래그십 |
📊 LLM 모델 크기별 구성 가능 GPU 비교
LLM 모델을 구성할 수 있는 최대 크기는 VRAM 용량과 메모리 속도에 의해 결정된다. 특히 L40S는 추론에 강한 반면, H200/B200은 고속 메모리(HBM)를 사용하여 대규모 학습에 최적화되어 있다.
| GPU 모델 | VRAM 용량 / 타입 | 추론 (Inference) – Max Size | 학습 (Training) – Max Size |
| L40S | 48GB GDDR6 | ~70B (4-bit 양자화 기준) | ~34B (QLoRA, LoRA 등 PEFT 기준) |
| H200 | 141GB HBM3e | ~180B 이상 (8-bit/FP8 기준) | ~100B (단일 GPU Full Fine-tuning 기준) |
| B200 | 192GB HBM3e | ~250B 이상 (8-bit/FP8 기준) | Trillion Scale (GB200 클러스터 기준) |
※ VRAM(Video RAM)은 GPU 전용 메모리로 성능과 처리 가능한 데이터의 한계를 결정하는 전용 작업 공간이자 고속 데이터 파이프라인이다. 요구 VRAM보다 작은 VRAM으로 LLM을 구동하는 것은 가능하지만, 성능 및 품질 저하라는 대가를 수반하는 트레이드 오프 과정이다.
| [LLM이 필요로 하는 VRAM 용량 계산]LLM의 표준 학습 정밀도인 **FP16 (16비트)**는 파라미터 1개당 2바이트를 차지한다.70B 모델 요구량=70 Billion×2 Bytes/Parameter1024≈136.7 GB따라서 136.7GB가 필요한 70B 모델은 48GB VRAM의 L40S에서 그대로 구동될 수 없다. 70B 모델을 48GB VRAM 환경에서 구동하기 위해서는 모델의 정밀도를 4비트(4-bit) 로 압축하는 양자화 기술(예: QLoRA, AWQ)이 필수적으로 적용된다.4비트 양자화 적용 요구량 (INT4 기준)4비트(4-bit) 양자화는 파라미터 1개당 0.5바이트를 차지한다.70B 모델 요구량(4-bit)=70 Billion×0.5 Bytes/Parameter1024≈34.2 GB L40S의 전체 VRAM 48GB에서 34.2GB를 제외하면 약 13.8GB의 공간이 남는다. 이 잔여 공간(13.8GB)은 LLM 추론에 필수적인 KV Cache (Attention Key/Value 값 저장) 및 RAG(검색 증강 생성)에 사용되는 Context 길이를 확보하는 데 충분한 공간이 된다. |
소프트웨어(S/W) 테크 스택 (Tech Stack)
오픈소스 생태계의 검증된 기술과 상용 솔루션의 안정성을 결합한 하이브리드 스택을 적용
| 구분 | 도입 사양 (Spec) | 선정 사유 |
| Base Model | 오픈소스 70B (한국어 파인튜닝 버전) | • 파라미터(매개변수)가 700억 개(70 Billion)인 거대언어모델(LLM)• 주로 Meta(페이스북)의 Llama(라마) 시리즈가 이 사이즈를 표준으로 채택하면서, 현재 AI 업계에서 “개인이나 기업이 직접 돌릴 수 있는 마지노선이자, 고성능의 기준점”으로 통함 |
| Vector DB | Milvus 또는 postgreSQL | • 10억 개 이상의 벡터를 처리할 수 있는 대용량 분산 처리 아키텍처 지원 |
| Framework | LangChain (Orchestration) + SGLang (Serving) | • SGLang을 통해 추론 속도를 2배 이상 가속화하고, LangChain으로 복잡한 ReAct 에이전트 로직 구현 |
파라미터가 700억 개(70B/72B)인 거대언어모델(LLM)은 현재 오픈소스 진영의 플래그십 모델로 간주된다. 가장 대표적인 경쟁 모델인 Llama 3와 Qwen 2.5를 비교한다.
| 구분 | 70B급 LLM (일반적 특징) | Llama 3 70B (Meta) | Qwen 2.5 72B (Alibaba) |
| 개발사 | 오픈소스 생태계 주도 기업 | Meta (페이스북) | Alibaba Cloud |
| 출시 시점 | 2024년 주력 모델 | 2024년 4월 | 2024년 6월 (2.5 버전) |
| 파라미터/VRAM | 고도의 추론 능력을 위한 필수 크기 | 700억 개 | 720억 개 |
| 최소 하드웨어 | 4비트 양자화 시 40GB ~ 48GB VRAM 필요 (H100 1장 또는 고성능 48GB GPU) | H100 1장 (양자화 시) | H100 1장 (양자화 시) |
| 핵심 강점 | 광범위한 커뮤니티 지원, 가장 많은 파인튜닝 레퍼런스 및 라이브러리 호환성 | 코딩, 수학 능력, 논리적 추론에서 Llama를 능가하며, 한국어 포함 다국어 성능이 매우 뛰어남. | |
| 기술적 특징 | 전통적인 LLM의 표준으로 통용되며, 가장 안정적인 성능을 보임. | RadixAttention 및 백엔드 최적화로, 복잡한 RAG나 Structured Output(JSON 강제)에 유리함. | |
| 주요 활용 용도 | 범용적인 챗봇 서비스, 안정적인 온프레미스(On-Premise) RAG 시스템 구축 | 에이전트(Agent) 자동화, 복잡한 데이터 분석 및 추론 워크로드 | |
- 70B급 모델은 성능(지능)과 구축 가능성(하드웨어)의 균형을 맞춘 최적의 선택이며, Llama가 안정성과 범용성의 표준이라면, Qwen은 고성능 추론 및 복잡한 워크플로우에 특화된 모델로 경쟁하고 있다.
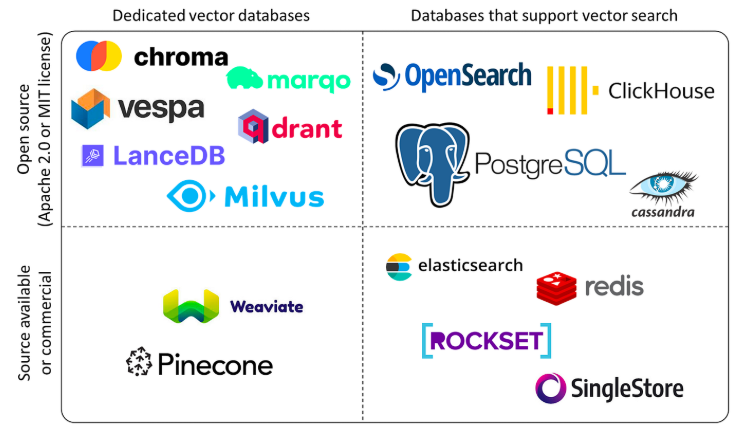
(Vector Database Landscape)
벡터 데이터베이스(Vector DB)를 선택할 때는 단순히 속도뿐만 아니라, 구축하려는 서비스의 특성과 기존 인프라와의 연동성을 복합적으로 고려해야 한다.
| 고려사항 | 내용 | 전용 벡터 데이터베이스(Milvus/Qdrant) | 확장형/통합형 벡터 데이터베이스(pgvector/Elasticsearch) |
| 데이터 모델 | 순수 벡터 DB (전용)를 선택할지, 기존 DB의 확장 기능을 선택할지 결정해야 한다. | 벡터 검색 성능 및 대규모 처리에 집중 | 기존 데이터와 벡터 데이터의 통합 관리에 유리 |
| 필터링 기능 | 벡터 검색 전후에 메타데이터(시간, ID, 사용자 정보 등)를 얼마나 효율적으로 필터링할 수 있는가? | Qdrant가 Payload Filtering에서 강력함. | pgvector는 SQL 기반의 정교한 필터링이 가능함. |
| 확장성 및 아키텍처 | 데이터 용량 증가에 따라 서버를 얼마나 쉽게 수평 확장(Scale-out)할 수 있는가? | Milvus가 스토리지와 컴퓨팅이 분리된 아키텍처로 수평 확장에 유리함. | pgvector는 PostgreSQL 클러스터 구조에 종속됨. |
| 운영 환경 및 비용 | 클라우드 서비스(Managed Service) 지원 여부 및 자체 구축(Self-hosting)의 난이도와 유지보수 비용. | 비교적 전문적인 지식이 필요함. | Elasticsearch는 이미 운영 중인 경우가 많아 비용 절감 가능. |
| 데이터 무결성 | 트랜잭션(Transaction)이나 데이터 무결성(ACID)이 서비스에 필수적인가? | 트랜잭션 지원이 제한적이거나 없음. | pgvector는 PostgreSQL의 ACID를 그대로 상속받아 강력함. |
- 벡터 데이터베이스 선택은 대규모 처리와 유연한 확장이 강점인 전용 DB(Milvus/Qdrant) 와 기존 인프라에 통합 관리가 용이한 확장형 DB(pgvector/Elasticsearch) 중 서비스 특성에 맞춰 결정해야 한다.
주요 Vector Database 비교
| 구분 | Milvus | Qdrant | pgvector | Elasticsearch |
| 유형 | Pure Vector DB (전용) | Pure Vector DB (전용) | RDBMS 확장 (PostgreSQL) | 검색 엔진 확장 (Search Engine) |
| 주요 기술 스택 | Go, Python, C++ (클라우드 네이티브) | Rust (매우 높은 성능 효율) | C (PostgreSQL 코어) | Java |
| 최대 강점 | 대규모 분산 처리, 스토리지/컴퓨팅 분리 구조로 유연한 확장성 | – 저렴한 비용, 스타트업에 적합- 고급 필터링 및 낮은 지연 시간 | ACID 트랜잭션 및 기존 SQL 인프라와의 완벽한 통합 | 하이브리드 검색 (키워드 + 벡터) 및 기존 사용자 기반이 방대함 |
| 적합 환경 | 10억 단위 이상의 대규모 데이터, 클라우드 환경의 고성능 벡터 검색 | 메타데이터를 정교하게 결합한 고성능 RAG 시스템 구축 | 금융, 법률 등 데이터 무결성이 중요한 환경 | 기존 Elastic Stack을 사용하며, 통합 검색 플랫폼을 구축할 때 |
| 주요 약점 | 복잡한 아키텍처로 자체 구축 및 관리가 까다로움 | Milvus 대비 분산 확장 구성이 복잡할 수 있음 | 대규모 인덱싱 시 전용 DB 대비 성능 제약이 있음 | 벡터 전용 DB 대비 메모리 및 I/O 효율성이 낮음 |
LLM 서비스 아키텍처 (Application → Orchestration → Data/Model → Infrastructure)
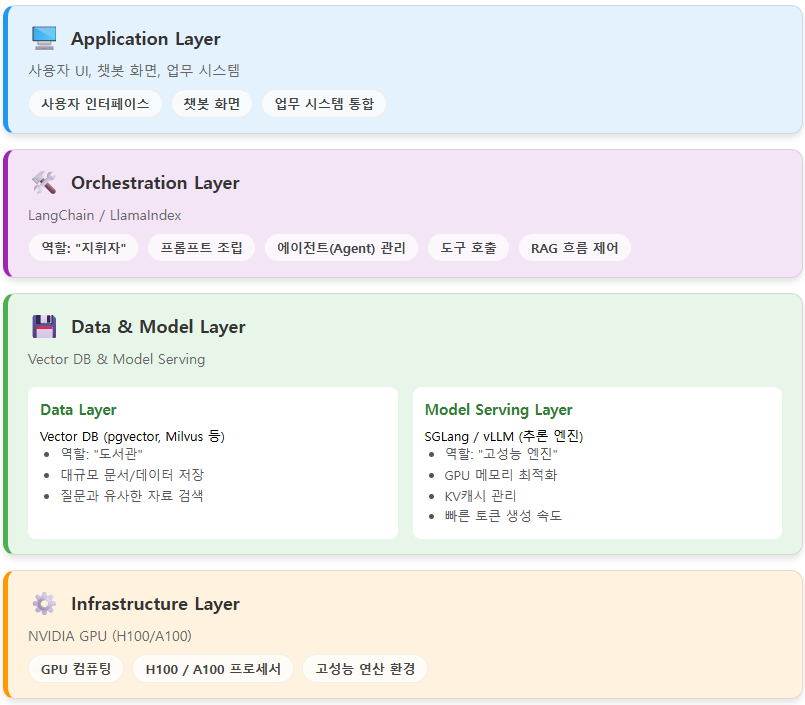
LangChain과 SGLang/vLLM은 LLM 서비스 아키텍처에서 각각 제어(Control)와 실행(Execution)을 담당하는 상호 보완적인 프레임워크이다.
| 계층 | 내용 |
| 오케스트레이션 계층 | LangChain과 같은 프레임워크가 외부 도구와 모델 사용 순서를 관리함→ 비즈니스 로직, 프롬프트 관리, RAG, 메모리 관리 |
| 추론/서빙 계층 | SGLang과 같은 엔진이 LLM의 실제 연산 성능을 최적화하여 답변 속도를 높임→ 모델 로딩, KV 캐시 최적화, 토큰 생성 속도 가속 |
| 데이터 계층 | RAG를 위한 벡터 데이터베이스가 LLM에 지식을 제공함 |
3. 핵심 구축 전략
핵심 1: LLM 최적화 전략 – “법률 전문가 모델(Legal-LLM) 파인튜닝”
Base Model 선정 및 한계 극복
| 구분 | 내용 |
| 선정모델 | Meta Llama 3 70B or QWEN 2.5 72B |
| 이유 | • 7B 모델은 복잡한 법리 추론에 한계가 있고, 405B 모델은 단일 서버 구축이 어려움• 70B는 성능과 구축 용이성의 Sweet Spot임 (최상위 추론 성능과 ‘현실적인 온프레미스 구축 및 운영비용’ 사이의 균형점)※ 70B 파라미터 규모는 복잡한 법리 추론, 다단계 사고(Multi-step Reasoning), 미묘한 뉘앙스 파악 등 고도의 지적 작업을 수행하는 데 필수적인 최소 규모로 여겨진다. 13B 이하의 소형 모델은 복잡한 논리 구성에서 오류(환각)를 보일 확률이 높다. |
| 과제 | 기본 모델은 한국 행정 용어(“각하”, “기각”, “인용”)의 뉘앙스를 정확히 모름 |
단계별 학습 파이프라인 (Training Pipeline)
| Step | 내용 |
| Step 1 | 데이터셋 구축 (Instruction Dataset Construction)• 내부의 결정서/재결서 5만 건을 (질문, 답변, 근거) 형태의 Q&A 쌍으로 변환• 예시 Input: “청구인이 청구 기간을 3일 넘겼을 때 처분은?” -> Output: “행정심판법 제OO조에 의거, 요건 불충족으로 ‘각하’해야 함.” |
| Step 2 | 효율적 미세조정 (PEFT – QLoRA)• 전체 파라미터를 다 학습하면 비용이 과다하므로, QLoRA (Quantized Low-Rank Adaptation) 기술을 적용함• GPU 메모리 사용량을 1/4로 줄이면서도, 법률 도메인 지식을 효과적으로 주입함 |
| Step 3 | 성능 평가 (Legal-Bench Eval)• 학습된 모델이 법률 추론을 제대로 하는지, 변호사/심사관이 참여하는 **RLHF (인간 피드백 강화 학습)**를 통해 검증함 |
핵심 2: RAG(검색 증강) 인프라 – “환각 없는 근거 제시”
Vector DB 구축 전략: “모든 문서를 벡터(좌표)로 변환”
LLM이 아무리 똑똑해도 최신 사건 기록은 모른다. 이를 보완하기 위해 벡터DB(Qdrant 등) 기반의 고성능 벡터 검색 시스템을 구축한다.
• 임베딩 모델 (Embedding Model): 한국어 법률 문장에 특화된 BGE-M3-Korean 모델을 사용한다. (긴 문맥 처리 및 의미 검색에 탁월)
• 청킹 전략 (Chunking Strategy): 문서를 단순히 자르는 게 아니라, ‘조항 단위’, ‘판결 요지 단위’로 의미 있게 분할하여 저장한다.
하이브리드 검색 (Hybrid Search) 구현
단순 벡터 유사도 검색(Semantic Search)만으로는 “제89조 1항”과 같은 정확한 키워드를 놓칠 수 있다. 이를 방지하기 위해 Dense Vector와 Sparse Vector를 모두 지원하는 Qdrant를 사용하여 단일 저장소 내에서 하이브리드 검색을 구현한다.
| 검색 방식 | 역할 | 기술 스택 |
| Dense Retrieval | “거주 요건을 어긴 사례”와 같은 의미 기반 검색 | Qdrant (Dense Vector) |
| Sparse Retrieval | “소득세법 시행령 제154조”와 같은 정확한 용어 검색 | Qdrant (Sparse Vector / SPLADE) |
| Reranking | 두 검색 결과를 합쳐서 가장 적합한 순서로 재정렬 | Reciprocal Rank Fusion (RRF)(Qdrant 내장 기능) 또는 Cross-Encoder |
- Dense Vector: 0이 거의 없고, 모든 공간이 실수(Float) 값으로 빽빽하게 채워진 상태 (단어의 의미와 관계를 압축해서 표현)
- Sparse Vector: 대부분의 값이 0으로 채워져 있고, 특정 단어가 있는 위치만 1(또는 가중치)인 상태 (단어의 유무를 따짐)
추론 엔진 (Inference Engine) 최적화
구축된 LLM이 복잡한 법리 추론(Reasoning)과 정형화된 문서 생성을 빠르고 정확하게 수행하기 위해 SGLang 엔진을 도입한다.
• RadixAttention 기술 (캐시 재사용): 에이전트가 ‘검색-추론-생성’의 다단계 사고 과정을 거칠 때, 중복되는 프롬프트(시스템 프롬프트, 참조 법령 등)의 KV 캐시를 자동으로 재사용한다. 이를 통해 긴 법률 문맥을 유지하면서도 vLLM 대비 최대 5배 빠른 에이전트 구동 속도를 확보함
• 구조화된 생성 (Structured Decoding): 심사 보고서나 API 호출용 JSON 데이터 등 엄격한 형식이 요구되는 법률 문서를 생성할 때, 정규표현식(Regex)과 파서(Parser)를 통해 문법 오류 없이 100% 정해진 포맷대로 출력하도록 제어함
핵심 3: 데이터 파이프라인 & 보안 아키텍처
ETL 및 데이터 전처리 자동화
비정형 데이터(HWP, PDF)를 AI가 이해할 수 있는 포맷으로 변환하는 ETL(Extract, Transform, Load) 파이프라인을 구축한다.
• Unstructured.io / Apache Airflow: 주기적으로 내부 파일 서버를 스캔하여, 새로 생성된 결정문을 자동으로 텍스트로 추출하고 개인정보를 마스킹(비식별화) 한 후 Vector DB에 적재함
LLM Ops (운영 관리) 플랫폼
AI 모델은 구축보다 운영이 중요하다. 모델의 성능을 모니터링하고 지속적으로 개선하기 위한 MLOps 플랫폼을 도입한다.
| LangSmith /MLflow | Trace | “왜 AI가 이 사건을 ‘기각’이라고 판단했지?” -> 추론 과정(Chain of Thought)을 단계별로 로그로 남겨 심사관이 역추적 가능하게 함 |
| Eval | 답변 품질에 대한 심사관의 피드백(좋아요/싫어요)을 수집하여 다음 재학습 데이터로 활용 |
물리적/논리적 보안 구성 (Security Architecture)
[망 분리 환경을 고려한 인프라 배치도]
| 내부망 (Secured Zone) | DMZ (Bridge Zone) |
| • GPU Server Farm: LLM 모델 및 Vector DB 구동 (인터넷 차단)• Private Repository: 학습 데이터 및 모델 가중치 파일 저장소 | • API Gateway: 외부망의 REST API 요청을 받아 내부망으로 중계 (TLS 암호화)• Data Sanitizer: 오고 가는 데이터의 악성 코드 및 민감 정보 필터링 모듈 |
※ RBAC (Role-Based Access Control): 심사관의 직급이나 담당 분야에 따라 열람 가능한 데이터 범위를 벡터 DB(Qdrant) 레벨에서부터 통제 (Multi-tenancy 지원)
내부망 (Secured Zone)
내부망은 외부의 직접적인 접근이 차단되며, 가장 높은 보안 수준을 유지해야 하는 중요 시스템과 데이터가 위치하는 영역이다.
GPU Server Farm (LLM 모델 및 Vector DB 구동)
- 역할: LLM의 학습 및 추론(Inference)을 수행하며, 모델 구동에 필요한 Vector Database를 운영한다.
- 보안 특징: 인터넷 차단이 필수적이다. 외부로부터의 직접적인 코드 주입이나 데이터 유출 경로를 원천 차단한다.
Private Repository (학습 데이터 및 모델 가중치 파일 저장소)
- 역할: AI 모델 학습에 사용되는 민감한 데이터와, 학습을 통해 생성된 모델의 가중치 파일 등 핵심 지적 자산을 안전하게 저장한다.
- 보안 특징: 외부 접근이 엄격히 통제되며, 내부 사용자도 접근 권한이 최소한으로 제한된다.
DMZ (Bridge Zone)
DMZ (Demilitarized Zone) 또는 Bridge Zone은 내부망과 외부망 사이에 위치하여, 외부 사용자의 접근을 허용하면서도 내부망을 보호하는 완충 지대 역할을 한다. 외부의 요청을 받아 검증 및 처리 후 내부망으로 안전하게 중개하는 기능을 담당한다.
API Gateway
- 역할: 외부망으로부터 들어오는 REST API 요청을 받아 유효성을 검증하고, 요청을 내부망의 서비스(예: GPU Server Farm의 LLM 추론 API)로 안전하게 중계한다.
- 보안 특징:
- TLS 암호화를 적용하여 통신 구간의 데이터를 보호한다.
- 인가되지 않은 접근을 차단하고, 요청에 대한 속도 제한(Rate Limiting) 등의 기능을 수행하여 내부망 보호를 위한 1차 방어선 역할을 한다.
Data Sanitizer (데이터 필터링 모듈)
- 역할: DMZ를 통과하여 오고 가는 데이터에 대해 악성 코드 및 민감 정보를 필터링하고 소독하는 역할을 수행한다.
- 보안 특징:
- 외부에서 들어오는 입력 데이터(프롬프트 등)에 악성 코드가 포함되어 있는지 검사하고 제거한다.
- 내부망에서 외부로 전송되는 응답 데이터에 민감 정보(개인 정보 등)가 포함되어 있는지 검사하여 유출을 방지한다.
핵심 4: 지능형 심사 지원기능 구현
심사관들의 업무 패턴(초급~파워유저)과 목표(저부가가치 업무 자동화, 생산성 향상)를 명확히 정의한다. 이 방향성은 ‘AI를 통한 대체(Replacement)’가 아닌 ‘증강(Augmentation)’ 전략으로, 실무 적용 성공 확률이 매우 높은 접근이다.
초급 사용자에게는 ‘쉬운 접근성’을, 파워유저에게는 ‘유연성’을 제공하면서, 동시에 ‘환각(Hallucination)’을 억제하는 기능이 필수적이다.
지능형 검색 및 요약 (RAG 기반)
- 하이브리드 검색 (Qdrant 활용): 앞서 논의한 대로 키워드(사건 번호, 법령 조항)와 의미(유사 판례 내용)를 동시에 검색하여 정확도 확보.
- 출처 명시 (Grounding): 답변 생성 시, 참조한 판례나 심사 매뉴얼의 원문 링크(Citation)를 반드시 제공하여 심사관이 사실 관계를 즉시 검증할 수 있도록 함.
- 타임라인 자동 생성: 복잡한 사건 기록에서 날짜와 행위(출원, 보정, 거절 등)를 추출하여 시간 순서대로 시각화/요약.
문서 작성 및 비교 자동화
- 템플릿 기반 초안 작성: ‘거절 결정서’, ‘보정 요구서’ 등 정형화된 문서 양식을 선택하면, 요약된 사실관계를 채워 넣어 초안(Draft)을 자동 생성.
- 문서 비교 (Diff View): 출원인의 보정서와 원출원서를 비교하여 변경된 청구항이나 내용을 하이라이트 표시.
사용자 수준별 맞춤형 UI
- 원클릭 프롬프트 (초급용): 복잡한 지시어 입력 없이 “유사 판례 찾기”, “요약하기” 등 버튼 클릭만으로 결과 도출.
- 프롬프트 랩 (파워유저용): 심사관이 직접 프롬프트를 수정하고, 자신만의 프롬프트를 저장하여 재사용하거나 동료와 공유하는 기능.
4. 기대 효과: “실체 있는 AI 시스템 확보”
본 인프라 구축을 통해, 기관은 단순히 외부 API를 빌려 쓰는 것이 아니라, 자체적인 AI 모델, 데이터 저장소, 운영 플랫폼을 소유하게 된다. 이는 향후 어떤 법률/규정 변화에도 유연하게 대응할 수 있는 ‘디지털 자생력’을 의미한다.
AI 기반 심사 업무 증강 시스템 구축의 성공을 측정하기 위한 정량적 성과 지표(KPI)는 크게 1. 업무 효율성 및 생산성, 2. 시스템 정확성 및 품질, 3. 디지털 자생력 및 보안 세 가지 영역으로 나누어 설정할 수 있다.
| 영역 | KPI (정량적 성과 지표) | 측정 방법 및 목표 | 기대 효과 |
| 1. 업무 효율성 및 생산성 (증강) | 문서 초안 작성 시간 단축률 | AI 기능(템플릿 기반 초안 작성) 사용 전후의 ‘거절 결정서’, ‘보정 요구서’ 등 정형 문서 초안 작성 소요 시간 비교.목표: 평균 작성 시간 30% 이상 단축 | 저부가가치 업무 자동화를 통한 심사관의 시간 확보 및 처리 물량 증대. |
| 심사관 1인당 일일 처리 문서 수 증가율 | AI 시스템 도입 전후의 심사관별 최종 처리 완료 문서 수 비교.목표: 일일 처리 문서 수 15% 이상 증가 | 생산성 향상 목표 달성 및 심사 적체 해소 기여. | |
| 지능형 검색 및 요약 활용 빈도 | 유사 판례 찾기’, ‘타임라인 자동 생성’ 기능의 일일/주간 사용자당 평균 클릭 및 사용 횟수. | 심사관 업무 패턴에 AI 기능이 성공적으로 통합되고 있음을 확인. | |
| 2. 시스템 정확성 및 품질 (환각 억제) | 정보 검색(RAG)의 정확도(Recall/Precision) | 심사관이 AI 답변에 제시된 ‘출처 명시(Citation)’를 검증했을 때, 답변 내용과 출처 원문이 일치하는 비율.목표: 95% 이상의 사실 관계 일치율 달성 | 환각(Hallucination) 억제 및 심사관의 AI 답변에 대한 신뢰도 확보. |
| 모델 피드백 참여율 (RLHF 데이터 확보율) | 심사관이 AI 답변에 대해 ‘좋아요/수정 제안’ 버튼을 클릭하는 비율(총 사용 건수 대비).목표: 일일 사용 건수의 10% 이상 피드백 참여 유도 | 지속적인 모델 개선 파이프라인의 활성화 및 도메인 특화 데이터 확보. | |
| 3. 디지털 자생력 및 보안 (자생력) | 외부 API 종속성 제로화 | 시스템 운영에 외부 LLM/Vector DB 등 상용 클라우드 서비스 API를 사용하지 않는 비율. 목표: 100% 자가 운영 (0% 외부 종속) | 법률/규정 변화에 대한 유연한 대응력 및 ‘디지털 자생력’ 확보. |
| 보안 통제 준수율 (RBAC 적용 범위) | 직급 및 담당 분야별로 데이터 열람 권한이 벡터 DB 레벨에서 정확하게 통제되는 데이터 항목의 비율.목표: 100% 중요 데이터에 대한 접근 통제 적용 | 데이터 거버넌스 및 보안 규정 준수를 통한 민감 정보 유출 리스크 최소화. |
참고문헌
- NVIDIA GPU 아키텍처, https://www.nvidia.com/ko-kr/data-center/technologies/hopper-architecture/
- Vector DB classification https://www.infracloud.io/blogs/vector-databases-beginners-guide/
- NVIDIA Data Center Roadmap: https://www.servethehome.com/nvidia-data-center-roadmap-with-gx200nvl-gx200-x100-and-x40-ai-chips-in-2025/