
최근 저희 부서의 과거 입찰 문서를 벡터 데이터베이스(Vector Database)에 저장하고, 검색 증강 생성(RAG, Retrieval-Augmented Generation) 시스템을 구축했습니다. “신규 공고인 분석사업과 유사한 우리의 과거 사업은 무엇이 있나요?”라는 질문에 시스템은 자신 있게 답변했지만, 자세히확인해보니 완전히 다른 사업의 내용을 가져와 답변하는 경우가 있었습니다.
문제는 명확했습니다. 벡터 검색으로 가져온 문서들이 실제로는 연관성이 낮았고, 대형 언어 모델(LLM, Large Language Model)은 검색된 내용을 무비판적으로 수용해 그럴듯한 답변을 생성했습니다. 전통적인 RAG의 한계를 직접 체감할 수 있었습니다
이런 문제를 해결하기 위해 등장한 것이 바로 ‘RAG 2.0’이라 불리는 차세대 검색 증강 생성 기술들입니다. 2024년부터 본격적으로 주목받기 시작한 GraphRAG, Agentic RAG, CRAG(Corrective RAG) 등은 전통적 RAG의 한계를 극복하고 더 정확하고 신뢰할 수 있는 답변을 제공하기 위해 설계되었습니다. 이번 글에서는 이러한 RAG 2.0 기술들을 하나씩 살펴보겠습니다.
1. 전통적 RAG의 한계
먼저 전통적 RAG(Naive RAG라고도 불림)가 어떻게 작동하는지 간단히 살펴보겠습니다.

전통적 RAG의 작동 방식
- 문서 인덱싱: 문서를 청크(chunk)로 분할하고 임베딩(embedding) 모델로 벡터화하여 벡터 데이터베이스에 저장
- 검색: 사용자 질문을 벡터로 변환하고, 벡터 유사도를 기반으로 관련 문서 검색
- 생성: 검색된 문서를 컨텍스트로 LLM에 전달하여 답변 생성
이 방식은 간단하고 효과적이지만, 몇 가지 근본적인 한계가 있습니다:
검색 품질 문제: 벡터 유사도만으로는 실제 관련성을 정확히 판단하기 어렵습니다. 비슷한 단어를 사용하지만 완전히 다른 맥락의 문서가 검색될 수 있죠.
글로벌 질문 처리 실패: “이 데이터셋의 주요 주제는 무엇인가요?” 같은 전체 문서 코퍼스(corpus)에 대한 질문에는 제대로 답변하지 못합니다. 특정 문서 조각만 검색하기 때문입니다.
연결 관계 파악 불가: 여러 문서에 흩어진 정보를 연결해야 하는 복잡한 질문(예: “A 회사와 B 프로젝트의 관계는?”)에 취약합니다.
자기 검증 부재: 검색된 문서가 실제로 관련 있는지, 정확한지 스스로 판단하지 못합니다.
이러한 한계를 극복하기 위해 등장한 것이 바로 RAG 2.0 기술들입니다.
2. GraphRAG: 지식 그래프로 전체를 이해하다

GPT-4 Turbo를 사용하여 구축된 LLM 생성 지식 그래프.(출처: Microsoft Research)
GraphRAG란?
GraphRAG는 마이크로소프트 리서치(Microsoft Research)가 2024년 2월 발표하고 7월에 오픈소스로 공개한 기술로, 문서를 단순 벡터가 아닌 지식 그래프(Knowledge Graph) 형태로 인덱싱하는 혁신적인 접근법입니다.
전통적 RAG가 문서를 독립적인 조각들로 보는 반면, GraphRAG는 문서 내 개체(Entity)와 관계(Relationship)를 추출하여 그래프 구조로 표현합니다. 이를 통해 정보 간의 연결 관계를 파악하고, 전체 데이터셋에 대한 깊은 이해가 가능해집니다.
작동 원리
GraphRAG는 크게 두 단계로 작동합니다:
1단계: 인덱싱 (Indexing)
문서를 작은 단위(TextUnit)로 분할한 후, LLM을 사용하여:
- 개체 추출: 인물, 장소, 조직, 개념 등을 식별
- 관계 추출: 개체 간의 관계를 파악
- 클레임 추출: 중요한 주장이나 사실 정보 추출
추출된 정보는 지식 그래프로 구조화되며, 그래프 알고리즘을 통해 커뮤니티(Community)로 클러스터링됩니다. 각 커뮤니티는 서로 밀접하게 연관된 개체들의 집합이며, LLM이 각 커뮤니티에 대한 요약문을 생성합니다.
[문서] → [개체/관계 추출] → [지식 그래프] → [커뮤니티 탐지] → [커뮤니티 요약]
2단계: 쿼리 (Query)
사용자 질문에 따라 두 가지 검색 방식을 사용합니다:
로컬 검색 (Local Search): 특정 개체와 관련된 정보를 찾는 질문
- 예: “서울시가 발주한 정책 현안 관련 사업은?”
- 그래프에서 해당 개체를 찾아 주변 관계와 문서를 검색
글로벌 검색 (Global Search): 전체 데이터셋에 대한 질문
- 예: “우리 부서가 입찰하는 사업들의 주요 트렌드는?”
- 계층적 커뮤니티 요약을 활용하여 전체적 관점에서 답변
GraphRAG의 강점
마이크로소프트 연구팀의 벤치마크 결과, GraphRAG는 전통적 RAG 대비:
- 포괄성(Comprehensiveness): 70~80% 승률
- 다양성(Diversity): 정보의 다양한 측면을 다룸
- 토큰 효율성: 글로벌 질문 처리 시 2~3%의 토큰만 사용하면서도 더 나은 성능
특히 “점을 연결해야 하는(connect-the-dots)” 복잡한 질문에서 큰 강점을 보입니다.
실무 적용 시 고려사항
장점만 있는 것은 아닙니다. GraphRAG를 공부하면서 발견한 몇 가지 고려사항:
높은 비용: 인덱싱 과정에서 모든 문서에 대해 LLM을 여러 번 호출해야 하므로, 대규모 문서 처리 시 API 비용이 상당히 발생합니다. 공식 GitHub 저장소에도 “GraphRAG 인덱싱은 비용이 많이 들 수 있습니다”라는 경고가 명시되어 있습니다.

출처 : https://github.com/microsoft/graphrag
처리 시간: 초기 인덱싱에 시간이 오래 걸립니다. 하지만 한 번 구축하면 재사용이 가능합니다.
프롬프트 튜닝 필요: 도메인별로 최적의 결과를 얻으려면 개체 추출, 관계 정의 등의 프롬프트를 조정해야 합니다.
현재 GraphRAG는 GitHub에서 오픈소스로 제공되며, Python 라이브러리 형태로 쉽게 사용할 수 있습니다. 2024년 12월 GraphRAG 1.0이 정식 출시되면서 데이터 모델 단순화, 벡터 스토어 통합(LanceDB, Azure AI Search 지원) 등 개선이 이루어졌습니다.
3. Agentic RAG: 스스로 생각하는 검색
Agentic RAG란?
Agentic RAG는 2024년 하반기부터 본격적으로 주목받기 시작한 개념으로, **AI 에이전트(Agent)**를 RAG 파이프라인에 통합하여 검색 전략을 동적으로 수립하고 실행하는 방식입니다.
전통적 RAG가 “질문 → 검색 → 생성”이라는 고정된 파이프라인을 따른다면, Agentic RAG는 에이전트가 상황에 따라:
- 검색이 필요한지 스스로 판단
- 여러 데이터 소스 중 어디서 검색할지 선택
- 검색 결과가 불충분하면 재검색 또는 웹 검색 수행
- 복잡한 질문을 여러 단계로 분해하여 순차적으로 해결
작동 원리: ReAct 프레임워크
대표적인 구현 방식은 ReAct(Reasoning and Acting, 추론과 행동) 프레임워크입니다:

사용자 질문 입력
↓
에이전트가 질문 분석 및 계획 수립
↓
도구 선택 및 실행 (예: 벡터 검색, 웹 검색, 데이터베이스 쿼리)
↓
결과 평가(판단) 및 다음 행동 결정
↓
충분한 정보 수집 시 최종 답변 생성
신규 발주 된 서울시 교통 분석 사업에 대해 검토해달라는 요청을 예시로 들면 다음과 같습니다.
- 생각: “이 사업은 교통 관련이니 과거 교통 사업을 찾아야겠다”
- 행동: [Vector DB 검색: “교통 빅데이터”]
- 관찰: “5건 발견, 그 중 3건이 서울시” 생각: “서울시 사업이 많네. A사가 2건 수주했는지 확인해보자”
- 행동: [Graph 검색: “A사 + 서울시”]
- 관찰: “A사가 서울시 교통 사업 3건 중 2건 수주”
- 결론: “A사가 서울시에 강하다. 경쟁 전략 필요”
주요 특징
다중 데이터 소스 활용: 벡터 데이터베이스, 관계형 데이터베이스, 웹 검색, API 등을 상황에 맞게 선택
쿼리 라우팅(Query Routing): 질문 유형에 따라 적절한 검색 엔진이나 데이터베이스로 라우팅
자기 검증: 검색 결과의 품질을 평가하고 필요시 재검색
멀티 턴 상호작용: 한 번의 검색으로 끝나지 않고 여러 단계를 거쳐 정보를 수집
구현 도구
- LangGraph: LangChain 기반의 에이전트 워크플로우 구축 도구
- LlamaIndex: Agentic document workflows 지원
- AutoGen: 마이크로소프트의 멀티 에이전트 프레임워크
- CrewAI: 협업하는 AI 에이전트 시스템
노드(Node)와 엣지(Edge)로 워크플로우를 정의하는 방식이 직관적입니다. 다만 에이전트설계가 복잡해질수록 디버깅이 어려워질 수 있습니다.
4. CRAG: 스스로 오류를 수정하는 검색
CRAG란?
CRAG(Corrective RAG, 교정 검색 증강 생성)는 2024년 1월 arXiv에 발표된 기술로, 검색된 문서의 품질을 자체적으로 평가하고 교정하는 메커니즘을 추가한 RAG 방식입니다.
핵심 아이디어는 간단합니다: “검색된 문서가 정말 질문과 관련이 있는가?”를 스스로 검증하고, 관련성이 낮으면 웹 검색 등 대체 수단을 동원한다는 것입니다.
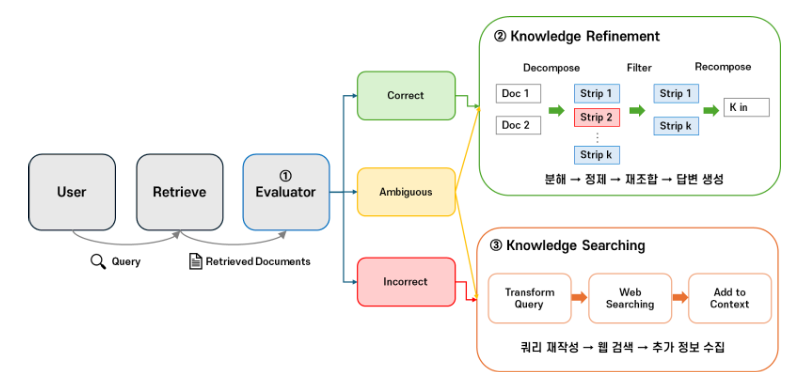
작동 원리
CRAG는 다음 세 가지 핵심 컴포넌트로 구성됩니다:
1. 검색 평가자 (Retrieval Evaluator)
검색된 각 문서에 대해 관련성 점수를 매기고, 신뢰도에 따라 세 가지 행동을 결정합니다:
- Correct (정확): 관련성이 높은 문서가 충분히 있음 → 문서 정제 후 사용
- Incorrect (부정확): 관련 문서가 거의 없음 → 웹 검색으로 대체
- Ambiguous (애매): 확신할 수 없음 → 문서 정제 + 웹 검색 병행
원 논문에서는 T5-large 모델을 파인튜닝하여 평가자로 사용했지만, 실무에서는 GPT-4나 Claude 같은 LLM으로도 구현 가능합니다.
2. 지식 정제 (Knowledge Refinement)
관련 있는 문서라도 불필요한 정보가 섞여 있을 수 있습니다. CRAG는 문서를 더 작은 “지식 스트립(Knowledge Strip)”으로 분해하고, 각 조각의 관련성을 재평가하여 핵심 정보만 추출합니다.
[검색 문서] → [분해] → [지식 스트립 1, 2, 3, …] → [관련성 평가] → [핵심 정보만 선별]
3. 웹 검색 확장
내부 데이터베이스만으로는 답을 찾을 수 없을 때, CRAG는 쿼리를 재작성(Query Rewriting)하여 웹 검색을 수행합니다. Wikipedia 같은 신뢰할 수 있는 소스에서 정보를 가져와 답변을 보강합니다.
성능 향상 효과
원 논문의 실험 결과:
- 짧은 형식 생성 작업: 전통적 RAG 대비 정확도 향상
- 긴 형식 생성 작업: Self-RAG 대비 개선
- 플러그 앤 플레이(Plug-and-Play): 기존 RAG 시스템에 쉽게 통합 가능
특히 CRAG의 장점은 모듈화입니다. 기존 RAG 파이프라인에 평가자 레이어만 추가하면 되므로, 점진적으로 시스템을 개선할 수 있습니다.
5. 한계와 향후 전망
RAG 2.0 기술들도 완벽하지는 않습니다. 공부하면서 느낀 몇 가지 한계:
여전히 존재하는 과제
비용과 지연시간: 더 나은 품질을 위해 더 많은 LLM 호출이 필요하고, 이는 비용과 응답 속도에 영향을 줍니다.
복잡성 증가: 시스템이 복잡해질수록 디버깅과 유지보수가 어려워집니다. “왜 이런 답변이 나왔지?”를 추적하기가 힘들어요.
평가의 어려움: 무엇이 “좋은” 답변인지 정의하고 측정하는 것 자체가 어려운 문제입니다.
도메인 특화 필요: 범용적으로 잘 작동하는 설정은 없습니다. 각 도메인에 맞게 튜닝이 필요합니다.
앞으로의 방향
2025년 현재, RAG 기술은 빠르게 진화하고 있습니다:
- 더 효율적인 그래프 구축: LazyGraphRAG 같은 경량화된 접근법
- 멀티모달 RAG: 텍스트뿐 아니라 이미지, 표, 차트까지 처리
- 에이전트 간 협업: 여러 특화 에이전트가 협력하는 시스템
- 설명 가능성 향상: 왜 이런 답변을 했는지 추적 가능한 시스템
전통적 RAG에서 출발하여 GraphRAG, Agentic RAG, CRAG까지, 검색 증강 생성 기술은 놀라운 속도로 발전하고 있습니다. 계속해서 쏟아지는 최신 연구와 오픈소스 프로젝트들을 공부하면서, LLM의 가능성이 단순히 더 큰 모델을 만드는 것이 아니라 어떻게 외부 지식과 결합하느냐에 달려 있다는 것을 실감했습니다.
RAG 1.0은 “검색”에 집중했다면, RAG 2.0은 “검증”에 집중합니다.
GraphRAG는 지식의 구조를, Agentic RAG는 검색의 적절성을, CRAG는 정보의 순도를 검증합니다. 이러한 기술들의 목표를 이루기 위해서는 결국 좋은 데이터를 확보하고, 적절한 평가 지표를 정의하며, 사용자의 피드백을 시스템에 반영하는 것이 필요합니다.
참고문헌
- Microsoft Research GraphRAG 공식 페이지: https://microsoft.github.io/graphrag/
- GraphRAG GitHub 저장소: https://github.com/microsoft/graphrag
- GraphRAG 논문: “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” (2024)
- CRAG 논문: “Corrective Retrieval Augmented Generation” arXiv:2401.15884 (2024)
- Agentic RAG Survey 논문: arXiv:2501.09136 (2025)
- Weaviate Blog: “What is Agentic RAG” (2024)
- IBM: “What is Agentic RAG?” (2024)
- LangGraph 공식 문서: https://langchain-ai.github.io/langgraph/