| 마이크로서비스 아키텍처(MSA)의 확산은 도메인별 독립 배포와 무중단 확장이라는 강력한 이점을 제공하는 동시에, 수십·수백 개 서비스가 맞물린 환경에서 “로그는 남는데 원인은 알 수 없는” 운영 복잡성이라는 근본적인 과제를 안겨주고 있다. 이 과제의 해법으로 주목받는 관찰 가능성(Observability)은 단순한 모니터링을 넘어, 로그(Logs)·메트릭(Metrics)·분산 추적(Tracing)이라는 3대 축을 통해 시스템 내부 상태를 외부 출력만으로 정확히 추론할 수 있는 능력을 의미한다. 여기에 도메인 주도 설계의 경계 컨텍스트(Bounded Context) 개념을 접목하면, CPU 점유율과 같은 기술 지표를 넘어 ‘주문 실패율’, ‘결제 처리 소요 시간’처럼 비즈니스 언어로 시스템을 바라보는 도메인 지향 관찰 가능성을 실현할 수 있다. 구현 측면에서는 벤더 종속 문제를 해소하는 OpenTelemetry 표준을 중심으로, Loki·Grafana·Tempo·Prometheus로 구성된 LGTM 오픈소스 스택이 비용 효율성과 통합 편의성을 모두 갖춘 현실적 선택지로 부상하고 있다. 실제 현장에서도 분산 추적 ID 전파 체계를 구축한 이후 장애 원인 식별 시간을 5분 이내로 단축한 사례가 보고되고 있어, Observability의 실질적 효과가 검증되고 있다. 다만 과도한 로깅에 따른 비용 폭증, 무의미한 알람 반복이 초래하는 운영 피로, 그리고 도입을 개발 후반으로 미루는 관행은 반드시 경계해야 할 안티패턴이다다. 결국 진정한 Observability란 복잡한 분산 시스템 속에서도 비즈니스가 의도한 대로 동작하는지를 투명하게 들여다볼 수 있는 통찰력이며, 이를 개발 초기부터 설계에 내재화하는 조직만이 장애에 흔들리지 않는 안정적인 서비스 운영 역량을 선제적으로 확보할 수 있다. |
1. 들어가는 말
마이크로서비스 아키텍처(Microservices Architecture, 이하 MSA)는 현대 소프트웨어 개발의 표준으로 자리 잡으며 도메인별 독립적 배포, 무중단 확장성, 그리고 기술 스택의 다양성이라는 강력한 이점을 제공하고 있다. 그러나, 이러한 유연성의 이면에는 필연적으로 운영 복잡성이 비약적으로 증가한다. 모놀리식(Monolithic) 아키텍처 시절에는 로그 파일 몇 줄을 검색하는 것만으로도 문제의 원인을 파악할 수 있었지만, 수십, 수백 개의 서비스가 유기적으로 연결된 MSA 환경에서는 단 하나의 사용자 요청이 수많은 서비스 간의 네트워크 호출로 파편화된다.
운영 현장에서는 “로그는 남는데 원인은 알 수 없는” 상황이 빈번하게 발생한다. 장애 리포트에는 명확한 근거 대신 ‘네트워크 일시적 지연 추정’, ‘특정 서비스의 간헐적 오류 추정’과 같은 불확실한 단어들이 난무하게 된다. 이러한 문제의 근본적인 해결책으로 대두된 것이 바로 관찰 가능성(Observability)이다. Observability는 단순한 모니터링(Monitoring)을 넘어, 시스템의 외부 출력(Logs, Metrics, Traces)만으로 내부의 상태를 얼마나 잘 이해할 수 있는지를 나타내는 척도이다.
본 글에서는 MSA와 도메인 주도 설계(Domain-Driven Design, 이하 DDD)의 관점을 결합하여, 단순한 도구의 도입을 넘어 비즈니스 가치를 보호하고 운영 효율성을 극대화할 수 있는 Observability 표준화 전략과 구현 방안을 논의하고자 한다.
2. Observability의 개념과 3대 핵심 축
Observability는 제어 이론에서 유래한 개념으로 시스템의 내부 상태를 외부의 출력값만으로 얼마나 잘 추론할 수 있는지를 의미한다. 현대적인 클라우드 네이티브 환경에서 Observability는 다음의 3대 핵심 축(Pillars)으로 구성된다.
[도표1] Observability의 3대 핵심 축
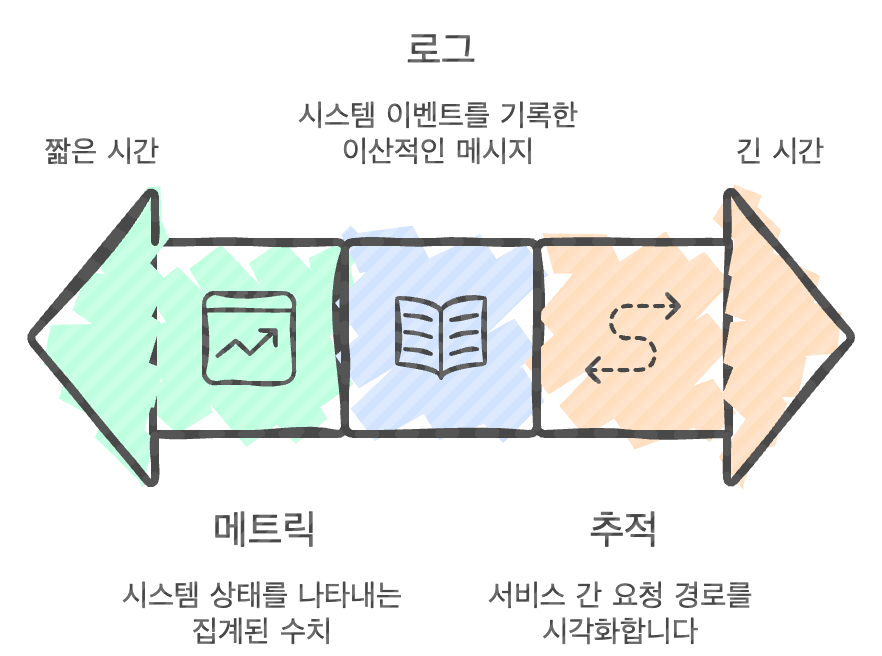
2.1 Logs (로그)
로그는 시스템에서 발생하는 이벤트를 시간 순서대로 기록한 이산적인 메시지이다. 장애 발생시 개발자가 가장 먼저 확인하는 ‘진실의 원천(Source of Truth)’이며, 문제의 문맥(Context)을 파악하는 데 결정적인 단서를 제공한다. MSA 환경에서는 텍스트 기반의 비정형 로그보다는 기계가 파싱하고 분석하기 쉬운 JSON 형태의 구조화된 로그(Structured Log)가 필수적이다.
2.2 Metrics (메트릭)
메트릭은 일정 시간 동안 수집된 데이터의 집계된 수치 정보이다. CPU 사용률, 메모리 점유율, 초당 요청 수(RPS, Requests Per Second), 응답 시간 등이 이에 해당한다. 로그와 달리 대량의 데이터를 효율적으로 저장하고 처리할 수 있어, 시스템의 전반적인 건강 상태를 나타내는 대시보드 구성이나 장기적인 트렌드 분석에 적합하다. 대표적인 분석 프레임워크로는 서비스 관점의 RED 메서드와 리소스 관점의 USE 메서드가 있다.
- RED 메서드 : Rate(요청 비율), Error(오류율), Duration(응답 시간)
- USE 메서드 : Utilization(사용률), Saturation(포화도), Errors(오류)
2.3 Tracing (분산 추적)
분산 추적(Distributed Tracing)은 MSA 환경에서 가장 중요한 요소 중 하나로 사용자 요청이 여러 마이크로서비스를 거쳐 처리되는 전체 경로를 시각화한다. 각 호출 구간을 Span이라 하며, 전체 경로를 Trace라고 한다. 이를 통해 서비스 간의 호출 관계를 파악하고, 전체 트랜잭션 중 어느 구간에서 병목이나 오류가 발생했는지를 정밀하게 식별할 수 있다.
3. DDD 관점에서의 도메인 지향 Observability
기술적인 Observability 도구만으로는 비즈니스의 상태를 온전히 파악하기 어렵다. DDD의 전략적 설계를 Observability에 적용함으로써 기술 지표와 비즈니스 성과를 연결하는 ‘도메인 지향 관찰 가능성’을 확보해야 한다.
3.1 Bounded Context와 Observability 경계 정의
DDD의 핵심 개념인 Bounded Context는 도메인 모델의 적용 범위를 정의한다. Observability 역시 이 경계를 따라야 한다. 주문(Order), 결제(Payment), 배송(Delivery) 등 각 Bounded Context는 독립적인 모니터링 대시보드와 알림 규칙을 가져야 하며, 이는 해당 도메인을 담당하는 팀의 책임 범위와 일치해야 한다. 예를 들어, 결제 서비스의 응답 지연이 주문 서비스의 실패로 이어지더라도 근본적인 관찰과 해결의 책임은 결제 Bounded Context 내에서 이루어져야 한다.
3.2 도메인 지향 관찰 가능성 (Domain-Oriented Observability)
마틴 파울러(Martin Fowler)가 주창한 도메인 지향 관찰 가능성은 비즈니스 로직 내에 관찰 코드를 통합하는 방법론이다. 단순히 “DB 연결 실패”와 같은 기술적 로그를 남기는 것을 넘어, “재고 부족으로 인한 주문 실패”와 같은 비즈니스 의미가 담긴 로그를 남겨야 한다.
Domain Probe 패턴
도메인 로직이 로깅 프레임워크나 메트릭 라이브러리에 직접 의존하게 되면 비즈니스 코드가 기술 코드로 오염된다. 이를 방지하기 위해 ‘Domain Probe’라는 인터페이스를 정의하고, 도메인 객체는 비즈니스 언어로 이 인터페이스를 호출하도록 설계한다.
| [도표2] Domain Probe 패턴 예시 |
|---|
| // Bad Practice: 도메인 로직에 기술 코드 혼재 public void checkout(Cart cart) { if (cart.isEmpty()) { logger.warn(“Cart is empty, traceId=” + span.currentTraceId()); // 기술 종속 return; } // … } |
| // Good Practice: Domain Probe 패턴 적용 public void checkout(Cart cart) { if (cart.isEmpty()) { checkoutProbe.emptyCartAttempted(cart.getCustomerId()); // 비즈니스 언어 return; } // … } |
비즈니스 언어의 보존 측면
- Bad (기술 중심) : logger.warn(…)은 “이 상황을 로그 파일에 기록해라”라는 기술적 명령입니다. 개발자가 코드를 읽을 때 “로그를 남기네?”라는 인프라적인 생각을 먼저 하게 만든다.
- Good (도메인 중심) : emptyCartAttempted(…)는 “장바구니가 비어있는 상태에서 결제를 시도했다”라는 비즈니스 사건(Event) 자체를 설명한다. 기획자나 현업 담당자가 코드를 봐도 무엇을 검증하는지 바로 이해할 수 있는 ‘공통 언어’를 사용한다.
관심사의 분리 측면
- 기술 종속성 제거 : span.currentTraceId() 같은 코드가 도메인 서비스에 들어오는 순간, 이 서비스는 특정 모니터링 라이브러리(예 : Sleuth, Zipkin) 없이는 테스트하거나 실행하기 어려워진다.
- 유연한 확장성 : 만약 나중에 “비어있는 장바구니 결제 시도 시 로그만 남기지 말고, 마케팅 팀에 알림을 보내자”라는 요구사항이 추가된다면 어떻게 될까요?
- Bad: checkout 메서드 안에 알림 발송 로직을 추가한다. (도메인 로직 오염)
- Good: checkout 메서드는 그대로 두고, checkoutProbe의 구현체 내부만 수정하거나 모니터링 시스템에서 해당 이벤트를 구독하면 된다.
3.3 유비쿼터스 언어와 도메인 메트릭
메트릭의 이름 역시 도메인 전문가와 개발자가 공유하는 유비쿼터스 언어(Ubiquitous Language)를 사용해야 한다. 일반적인 기술 메트릭 외에 다음과 같은 도메인 특화 메트릭을 정의하여 비즈니스 가시성을 확보해야 한다.
- cart.abandonment.rate : 장바구니 이탈률
- payment.failure.rate : 결제 실패율 (PG사 오류 포함)
- order.processing.duration : 주문 접수부터 처리 완료까지의 비즈니스 소요 시간
4. MSA 환경에서의 구현 전략과 도구 생태계
성공적인 Observability 구축을 위해서는 표준화된 기술 스택과 일관된 구현 전략이 필수적이다.
4.1 OpenTelemetry 표준 채택
과거에는 애플리케이션 성능 관리(APM, Application Performance Management) 벤더마다 독자적인 에이전트와 데이터 포맷을 사용하여 특정 솔루션에 종속되는 벤더 락인(Vendor Lock-in) 문제가 심각했다. 이를 해결하기 위해 CNCF(Cloud Native Computing Foundation) 산하의 OpenTelemetry(이하 OTel) 프로젝트가 로그, 메트릭, 트레이싱 수집을 위한 전 세계적인 표준으로 자리 잡았다.
- 벤더 중립적 표준 SDK 및 API : OTel은 특정 상용 솔루션에 의존하지 않는 표준 인터페이스를 제공한다. 개발자는 코드 수정 없이 설정만으로 데이터 전송 대상을 자유롭게 변경할 수 있다.
- OTel Collector의 중앙 제어 : Collector를 활용하면 애플리케이션에서 발생한 원시 데이터를 필터링, 가공, 샘플링한 후 Jaeger, Prometheus, Datadog 등 원하는 백엔드로 동시 전송(Multi-export) 할 수 있다.
- W3C Trace Context 준수 : 분산 추적의 상호 운용성을 위해 OTel은 W3C 표준 헤더를 사용하여 서로 다른 기술 스택 간에도 끊김 없는 컨텍스트 전파를 보장한다.
- 도입 비용 및 리스크 절감 : 표준화된 수집 체계는 향후 상용 솔루션 교체 비용을 획기적으로 낮추며 클라우드 네이티브 환경에서의 데이터 주권을 사용자에게 돌려준다.
4.2 중앙 집중식 로깅 전략
수십 개의 컨테이너에서 발생하는 로그를 개별적으로 확인하는 것은 불가능하다. 로그 표준화는 다음 3단계를 통해 완성된다.
- 로그 형식 표준화 : 모든 마이크로서비스가 공통된 JSON 포맷으로 로그를 출력하도록 라이브러리 차원에서 강제한다.
- 분산 트레이싱 연계 : 로그에 반드시 traceId와 spanId를 포함시켜, 로그 분석 도구(예: Kibana, Grafana)에서 특정 트랜잭션과 관련된 모든 로그를 한 번에 검색할 수 있게 한다.
- 중앙 집중식 수집 : Fluentd나 Fluent Bit와 같은 수집기를 통해 로그를 중앙 저장소(Elasticsearch, Loki)로 전송한다.
4.3 분산 추적 구현
Spring 생태계에서는 과거 Spring Cloud Sleuth가 표준이었으나, 현재는 Micrometer Tracing과 OpenTelemetry로 전환되는 추세이다. 분산 추적 구현 시 가장 큰 난관은 Context Propagation(문맥 전파)이다.
- HTTP 호출 : WebClient나 FeignClient 사용 시 자동으로 헤더에 Trace ID가 주입되도록 설정해야 한다.
- 비동기 메시징 : Kafka나 RabbitMQ를 사용할 경우, 메시지 헤더를 통해 Trace ID를 전파하고 Consumer 측에서 이를 다시 복원하여 추적을 이어가는 것이 핵심이다.
4.4 메트릭 수집 및 알람
Micrometer 라이브러리를 통해 애플리케이션 내부 지표를 수집하고, Prometheus가 이를 주기적으로 스크래핑(Pull 방식)하는 구조가 일반적이다. 알람 설정 시에는 ‘발생 빈도’가 아닌 ‘영향도’를 기준으로 해야 한다. 예를 들어, 단순한 에러 로그 1건 발생이 아니라, 일정 시간 동안 에러율이 임계치를 초과할 때 알람을 발송하는 것이 운영 피로도를 줄이는 핵심이다.
4.5 도구 생태계와 참조 아키텍처
현재 시장에는 다양한 Observability 도구가 존재하며, 조직의 규모와 비용, 기술 역량에 따라 적절한 스택을 선택해야 한다.
[도표3] Observability 솔루션 스택별 상세 비교
| 구분 | 오픈소스 LGTM 스택 | 전통적 ELK 스택 | 상용 APM(SaaS) |
| 주요 구성 | Grafana, Loki, Tempo, Mimir | Elasticsearch, Logstash, Kibana | Datadog, New Relic, Honeycomb |
| 데이터 통합성 | 매우 높음- 동일 UI 내 연결 | 높음- 인덱스 기반 연결 | 최상- 완전 통합 플랫폼 |
| 운영 비용 | 저렴- S3 등 객체 스토리지 활용 | 높음- 고성능 인덱스 서버 필요 | 매우 높음- 데이터 처리량 기반 |
| 검색 성능 | 메타데이터 기반- 필터링 위주 | Full-text 검색 최강 | 분석 및 시각화 최적화 |
| 추천 대상 | 비용 효율적 표준화를 원하는 팀 | 대규모 로그 분석이 필요한 조직 | 운영 인력이 부족한 초기 스타트업 |
오픈소스 LGTM 스택
Grafana Labs가 주도하는 오픈소스 스택으로, 최근 가장 각광받고 있는 조합이다. 비용 효율성이 뛰어나며, 도구 간의 통합이 매우 매끄럽다.
- Loki(Logs) : 로그 데이터를 저장, 인덱싱을 최소화하여 비용을 절감하고, 메타데이터 기반 검색에 최적화됨
- Grafana(Visualization) : 모든 데이터를 시각화하는 통합 대시보드
- Tempo(Traces): 고성능 분산 추적 저장소, S3와 같은 객체 스토리지를 백엔드로 사용 가능
- Mimir / Prometheus(Metrics): 대규모 시계열 데이터 저장 및 쿼리
ELK 스택
전통적인 강자로 Elasticsearch, Logstash, Kibana의 조합이다. 강력한 전문 검색(Full-text Search) 기능이 장점이나, 리소스 사용량이 많고 운영 비용이 높은 편이다.
상용 솔루션 (Datadog, New Relic)
SaaS(Software as a Service) 형태로 제공되며, 설치와 설정이 간편하고 강력한 기능을 즉시 사용할 수 있다. 다만 데이터 처리량에 따른 비용이 기하급수적으로 증가할 수 있어 비용보다 운영 편의성이 중요한 경우 선택된다.
5. 실무 적용 시 고려사항
5.1 주요 안티패턴과 고려사항
Observability를 도입할 때 흔히 범하는 실수를 피하기 위해 다음 사항을 유의해야 한다. 첫째, 모든 것을 로깅하려는 유혹을 경계해야 한다. 과도한 로깅은 저장 비용 폭증과 노이즈 증가로 이어지며 정작 중요한 신호를 묻히게 만든다. 둘째, 알람 피로(Alert Fatigue)를 주의해야 한다. 의미 없는 알람이 반복되면 운영팀은 진짜 장애 신호에 둔감해진다. 셋째, Observability를 사후 작업으로 미루어서는 안 된다. 개발 초기부터 설계에 내재화하지 않으면 나중에 도입하는 비용은 몇 배로 늘어난다.
5.2 실전 적용 사례
사례 1: 럭스로보 ‘모디팩토리’의 로그 표준화
Kubernetes 기반의 Go 마이크로서비스 환경에서 ELK 스택을 구축한 사례이다. 초기에는 로그 파편화로 고생했으나, 게이트웨이 단계에서 traceId를 생성하여 모든 서비스로 HTTP 헤더를 통해 전파하도록 아키텍처를 개선했다. 이를 통해 Kibana에서 단 하나의 ID 검색만으로 전체 트랜잭션 흐름을 파악할 수 있게 되어 장애 대응 시간을 획기적으로 단축했다.
사례 2: Leaphop의 OpenTelemetry 전환기
Spring Cloud Sleuth와 Zipkin을 사용하다가 OpenTelemetry와 Jaeger 조합으로 전환한 사례이다. WebClient 사용 시 Trace ID가 누락되는 문제를 해결하기 위해 필터를 커스터마이징하고, Kafka Consumer에서도 컨텍스트를 복원하는 팩토리를 적용했다. 결과적으로 “로그는 있는데 원인은 모르는” 상태에서 벗어나 장애 발생 시 원인 구간을 5분 이내에 식별할 수 있는 체계를 갖추었다.
5.3 마치며
MSA 환경에서 Observability는 선택이 아닌 생존을 위한 필수 요소이다. Logs, Metrics, Tracing이라는 3대 축을 유기적으로 통합하고, 여기에 DDD의 Bounded Context 개념을 적용하여 비즈니스 관점의 모니터링 체계를 구축해야 한다.
기술적으로는 OpenTelemetry 표준을 준수하여 벤더 종속성을 탈피하고, LGTM 스택과 같은 현대적인 도구를 활용하여 비용 효율성을 확보하는 것이 중요하다. 하지만, 도구보다 더 중요한 것은 “우리가 무엇을 보고자 하는가?”에 대한 명확한 정의이다. 시스템의 CPU 점유율보다 ‘주문 실패율’이, 메모리 사용량보다 ‘사용자 경험 응답 시간’이 더 중요한 지표임을 잊지 말아야 한다.
Observability는 특정 도구의 도입으로 완성되는 결과물이 아니라, 모든 개발 단계에서 질문을 던지고 답을 찾는 ‘공학적 접근’의 산물이다. ‘시스템이 왜 이렇게 동작하는가?’라는 질문에 데이터로 즉각 답할 수 있는 역량은 분산 시스템의 복잡성을 통제 가능한 영역으로 이끌어낸다. 결국 관찰 가능성을 내재화한 조직만이 속도(Agility)와 안정성(Stability)이라는 양립하기 어려운 가치를 동시에 추구할 수 있을 것이다.
참고문헌
- Martin Fowler, “Domain-Oriented Observability“, martinfowler.com.
- CNCF, “OpenTelemetry Documentation“, opentelemetry.io.
- MSAP.ai, “MSA 모니터링 및 로깅: Observability“.
- Grafana Labs, “Observability Survey Report 2025“, grafana.com.
- 럭스로보, “MSA 환경에서 로그를 기반으로 Observability 확보하기“, ithub.tistory.com.
- Leaphop, “MSA 지옥에서 살아남기: Observability 구축기”, blog.leaphop.co.kr.
- Elastic, “The 3 pillars of observability: Unified logs, metrics, and traces“, elastic.co.
- Paul, “OpenTelemetry란 무엇인가?“, medium.com.
- Velog, “Grafana를 사용해 MSA 서버 모니터링 구축하기 (Loki, Tempo, Prometheus)”, velog.io.
- Chris Richardson, “Pattern: Microservice Architecture“, microservices.io.
- Eric Evans, “Domain-Driven Design: Tackling Complexity in the Heart of Software“, fabiofumarola.github.io.
- Sam Newman, “Building Microservices: Designing Fine-Grained Systems“, O’Reilly Media.