
본 문서는 MySQL 8.0.0 부터 최신 MySQL 8.0.43 버전의 MySQL 8.0 Release Notes 의 Optimizer Notes 부분을 정리해서 중점적으로 SQL 튜닝에 사용할 수 있는 특성을추출해서 예제를 통해서 설명했다. Oracle SQL 튜닝에 이해가 있지만 MySQL 에는 처음 접하신 분들에게 도움이 될 것이다.
예제 소스: GitHub – wikibook/realmysql80
대상 버전: MySQL 8.0.x
목차
1. Hints
2.인덱스
2.1 descending indexes
2.2 function index
2.3 invisible index
3.common table expressions
4.Skip Scan Range Access Method
5.Window Functions
6.Hash join
7.Lateral Derived Tables
8. 8.0이후에 추가된 optimizer_switch
8.1 subquery_to_derived=off/on
8.2 prefer_ordering_index=on
8.3 derived_condition_pushdown=on
1.Hints
MySQL 8.0 에서는 오라클과 유사한 힌트를 제공한다.
오라클 공식문서 10.9.3 Optimizer Hints 부분을 보면 /*+ */ 형식의 힌트문법을 사용한다 .
이런 힌트는 예전 force index 와 달리 에러 발생 위험이 없다 .
Join-Order , Table-Level, Index-Level, Subquery, Naming Query Blocks 등 다양한 힌트가 있다 .
그중 많이 사용하는 힌트 위주로 예제를 통해서 알아보자.
아래 SQL를 보시면 e->d 순서로 실행되고 있다 .

위에 사항에서 JOIN_ORDER 힌트를 사용해서 드라이빙 테이불 순서교체를 했다 .
Oracle 의 leading 과 같은 힌트다.

MERGE,NO_MERGE HINT 사용 예제:
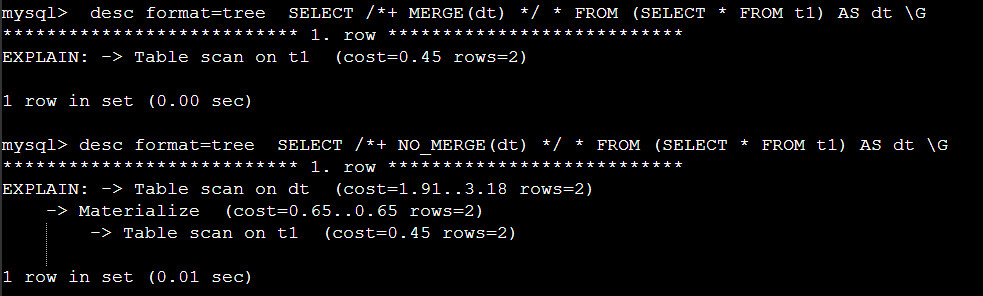
다음과 같이 할수도 있다 . 힌트 중 상당부분은 아래 optimizer_switch 내용을 SQL 레벨에서 임시 변경한다
- session 레벨에서 임시적으로 파라미터를 변경했다.
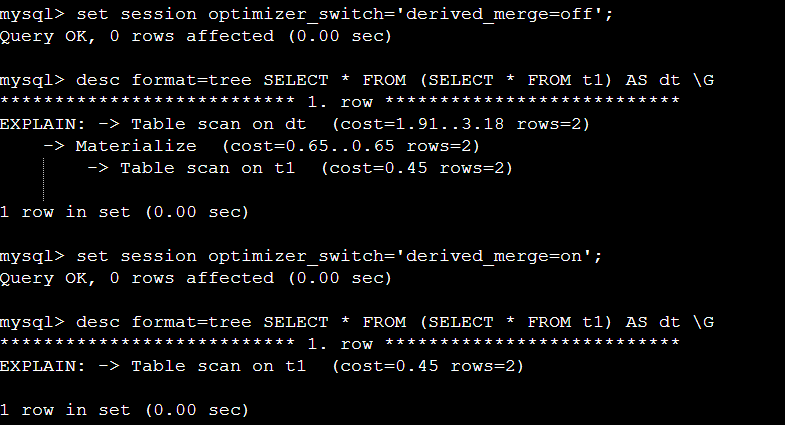
2. 힌트를 사용해서 위에 동일한 효과를 얻었다.
다만 힌트는 SQL 레벨에서 파라미터를 컨트롤 할 수 있어서 범위를 최소화 할 수 있다.
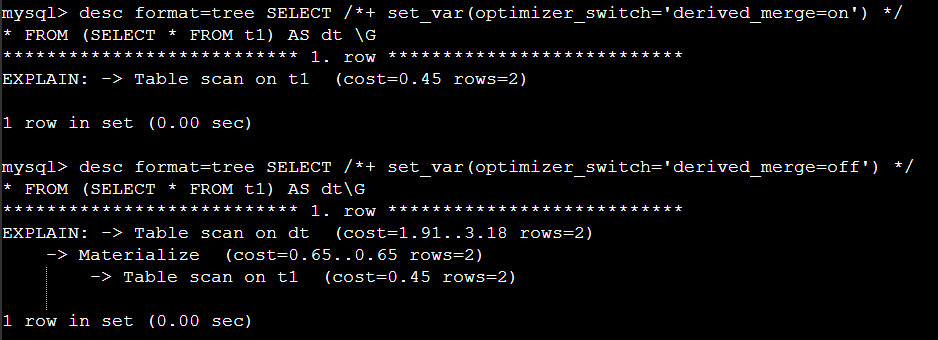
여러 힌트 중 제일 강력한 힌트 set_var 이다 ,임시적으로 SQL 레벨에서 파라미터를 변경할수 있다 .
2.인덱스
1). descending indexes
아래 와 같이 desc 인덱스 생성 후 테스트 결과다 .
여기서 생성된 idx_emp_n2 인덱스를 사용하지 않았다.
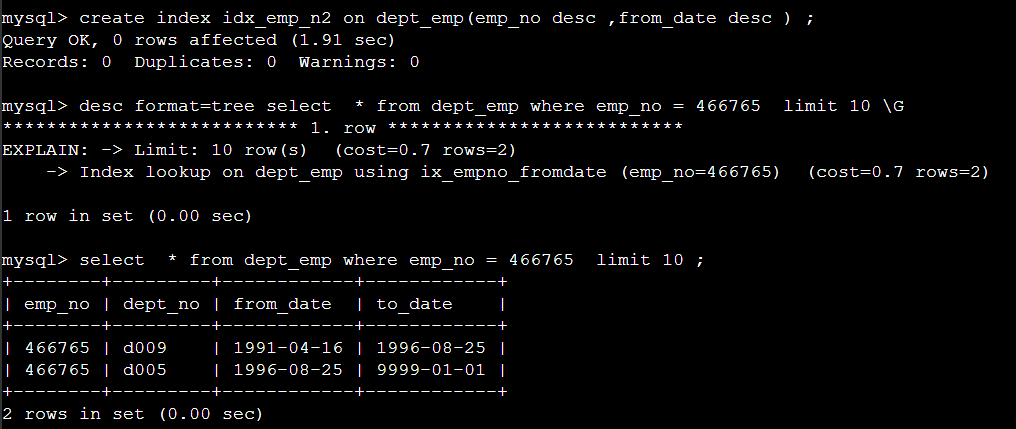
/*+ index(dept_emp idx_emp_n2) */ hint 를 사용하여서 위에서 생성된 인덱스를 사용하게 한다.
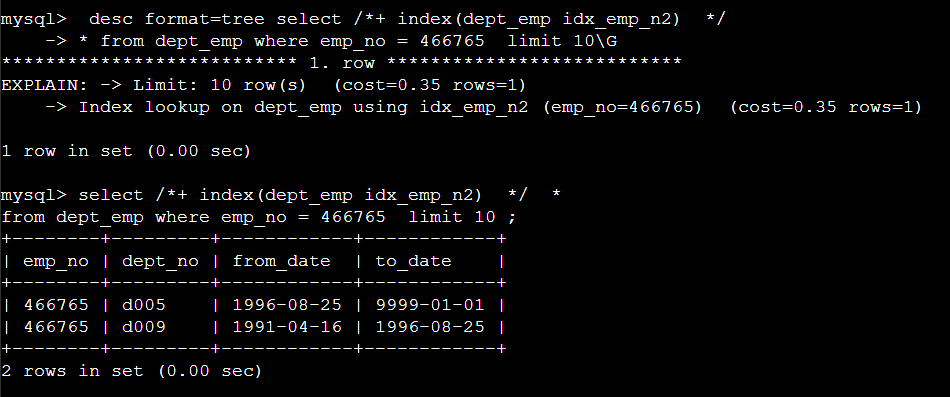
2). function index
MySQL 5.7 까지는 함수 인덱스를 지원하지 않아서 대체 방법으로 가상화 컬럼을 생성 후 ,그 컬럼에 인덱스를 생성하는 방법을 사용하기도 했다 .
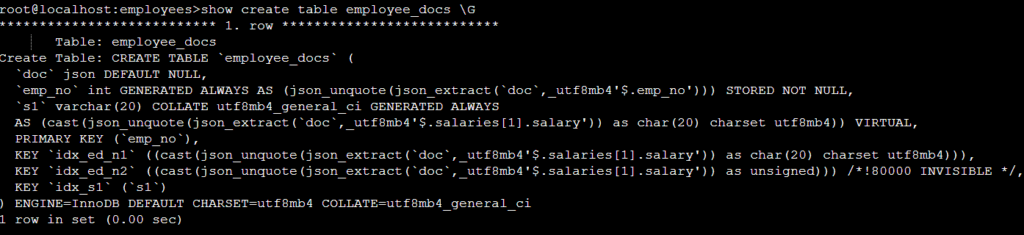
예를 들면 아래 테이블 중 emp_no 컬럼은 가상화로 된 컬럼이다.
5.7 에서는 이렇게 s1 란 컬럼을 가상화 컬럼으로 생성하고 ,이 컬럼에 인덱스를 생성했다.
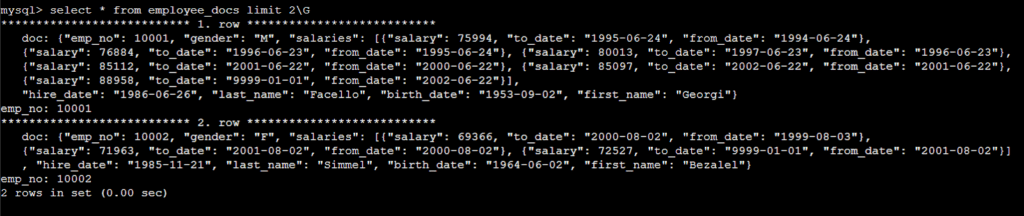
employee_docs 테이블의 데이터다 .
MySQL 8.0 부터는 별도 가상화 컬럼 생성이 필요없이 바로 함수 인덱스를 생성할 수가 있다 .
인덱스 idx_ed_n1 생성했는데 데이터 타입은 char 이다 .

그리고 아래 처럼 넘버타입을 입력하면 인덱스를 사용하지 못한다.

varchar 타입으로 입력하면 인덱스를 사용할수 있는걸 확인할 수 있다.

위에 처럼 함수인덱스를 사용하려면 데이터 타입이 무조건 동일해야 한다.
3). invisible index
invisible index 주로 인덱스는 주로 특정SQL에만 사용하고 싶을 때 생성하고 아래처럼 set_var함수를 사용해서 적용하면 된다.
1. 인덱스 idx_ed_n2 를 invisible 로 생성한다.
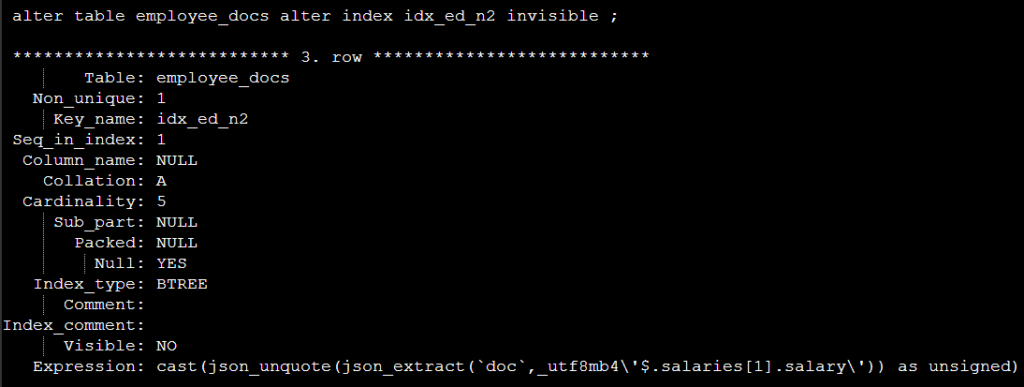
실행계획 확인 시 인덱스를 사용하지 못하고 테이블을 풀스캔을 한다 .

2. /*+ set_var(optimizer_switch=’use_invisible_indexes=on’) */ 힌트를 사용해서 인덱스를 사용한다 .

3. common table expressions —> with SQL
5.7 에는 with 문을 지원 하지 않는다 . 8.0 부터 지원을 해서 SQL을 더 다양하게 작성할 수 있게 되었다 .
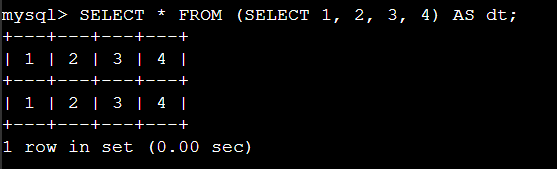
한번에 인라인뷰 컬럼명을 지정 할 수 있다.
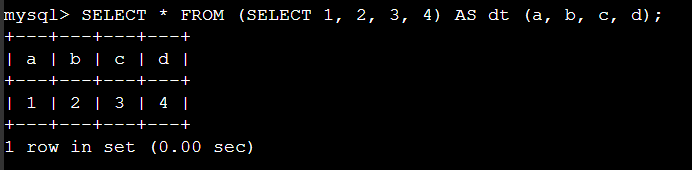
with 문 사용 예제:
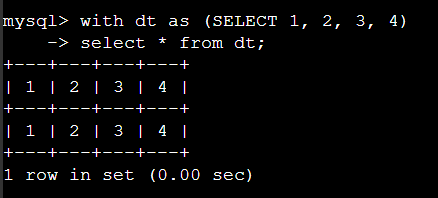
with 에서 컬럼명 지정 하는 예제:
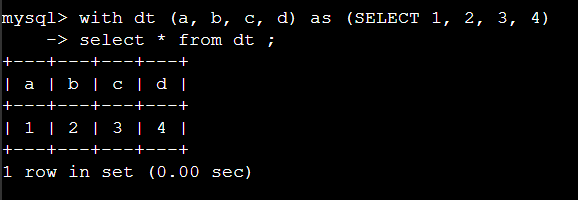
with 문을 사용하면서 힌트로 query block 단위로 컨트롤 할 수 있다 .
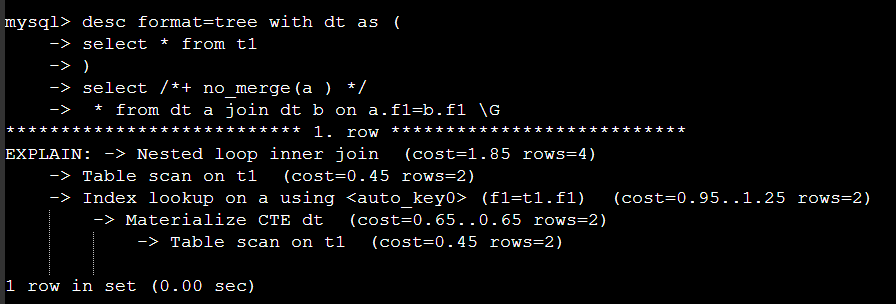
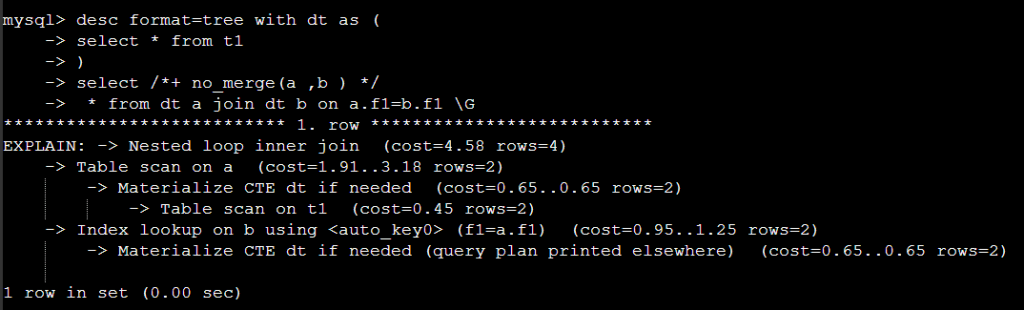
힌트를 사용해서 실행계획을 변경 할 수 있다 .
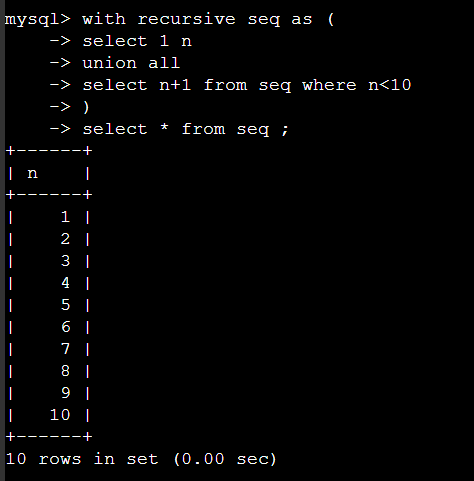
아래는 with 문을 사용해서 1부터 10 까지 추출예제다.
4.Skip Scan Range Access Method
8.0 부터는 skip index scan 을 지원한다 .
여기서 중요한것은 covering index 이기능을 사용하려면 where 조건이나 select 컬럼 모두 인덱스에 포함할때만 가능하다.
CREATE TABLE t1 (f1 INT NOT NULL, f2 INT NOT NULL, PRIMARY KEY(f1, f2));
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO t1 SELECT f1, f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 40 FROM t1;
ANALYZE TABLE t1;
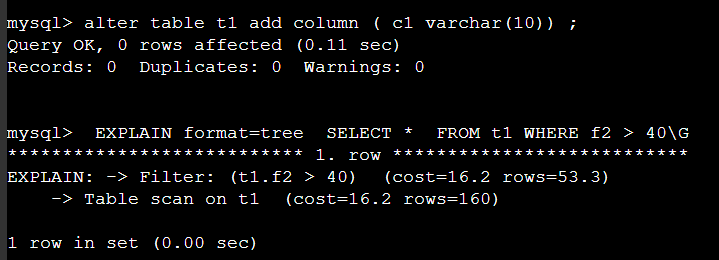
실행계획을 확인하니 skip index 를 사용할 수 있다.

다만 아래처럼 컬럼 추가 후 전체 컬럼을 조회 하면 skip scan 은 발생하지 않는다 .
여기서 중요한것은 Covering index 이다.
5. Window Functions
8.0 부터 다양한 window function 을 지원한다 .
row_number() over() , rank ,dense_rank,lead,lag, sum ,min ,max 등등 다양하다.
문법도 다른DB 하고 동일하여서 여기서 생략하겠다 .
6. Hash join
MySQL 8.0.18 부터 hash join 을 지원한다 .
관련 주요 파라미터는 optimizer_switch=’block_nested_loop=on/off’
hash join 필수 전제 조건은 block_nested_loop=on 이다.
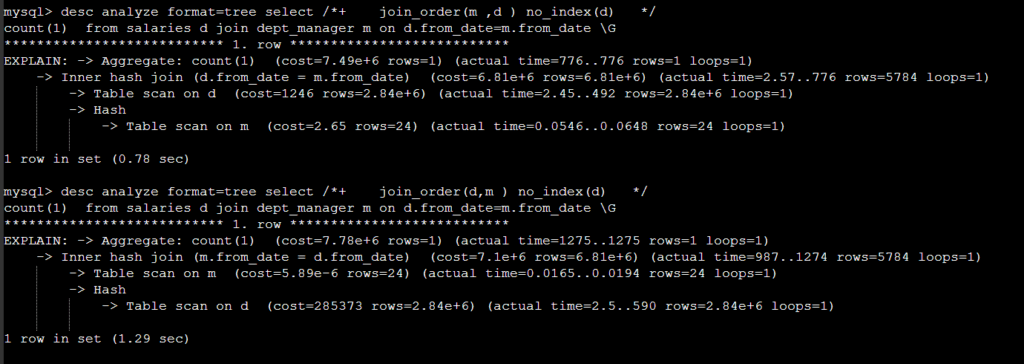
튜닝시 필요한 힌트는 set_var(join_buffer_size,xxxx) , join_order(a,b) 등으로 예상된다 .
그리고 MySQL 8.0.18 부터 desc/explain format=tree Oracle/PostgreSQL
유사한 실행계획이 추가되었다.
이전 버전에는 nested loop 만 지원하여 TRADITIONAL 실행계획으로 충분히 커버가 가능했지만, hash join 이 추가되면서 다양한 join 방식에 대하여 대응하기 위해 format=tree 방식이 추가된 것으로 추측한다.
hash join 의 핵심은 작은 테이블로 hash 계산을 하는 것이다.
7. Lateral Derived Tables
8.0.14 부터 지원하는 Lateral join , OLTP SQL 에 강력한 튜닝방법 중 하나다 .
특히 아래와 같이 부분 처리 SQL 형식에는 적합한 튜닝방법이다.
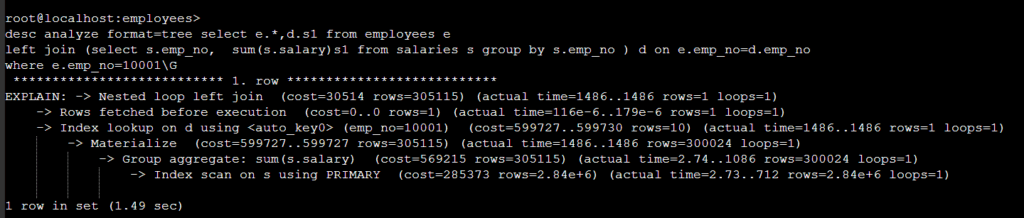
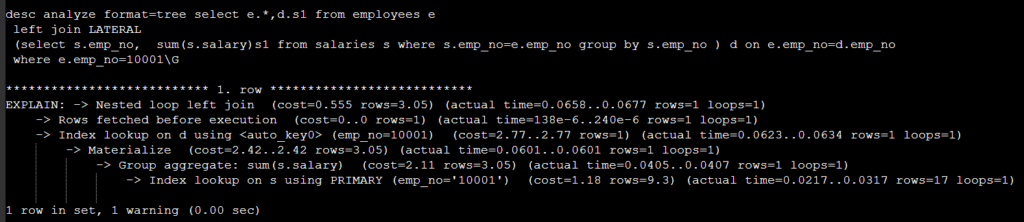
위 SQL의 문제는 d 에서 불필요한 내용을 group by 를 했다는 것이다 . lateral 을 사용해서 개선해 보자 .
8. 8.0이후에 추가된 optimizer_switch 대하여
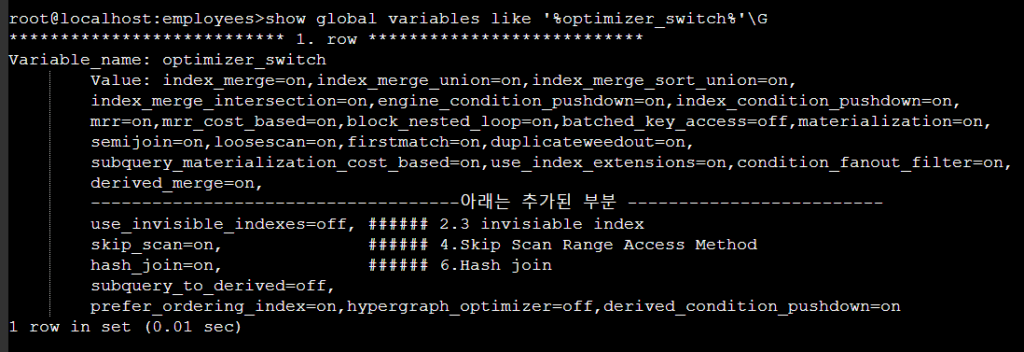
1). use_invisible_indexes=off, ###### 2.3 invisible index
skip_scan=on, ###### 4.Skip Scan Range Access Method
hash_join=on, ###### 6.Hash join
위 3개에 대해서는 이미 2.3,4,6 에서 다뤘다.
subquery_to_derived=off/on 서브쿼리를 인라인뷰로 변환여부이다 .
예제: 아래 2개의 예제에서는 desc 만 사용했고, 예전처럼 desc format=tree 형식의 실행계획을 추출하지 않았다.
그 원인은 desc 만 사용하면 show warnings\G 시 변환되어 SQL 의 전체가 추출되지만, desc format=tree 이것을 사용하면 show warnings\G 시 전체 SQL 추출되지 않는다 .
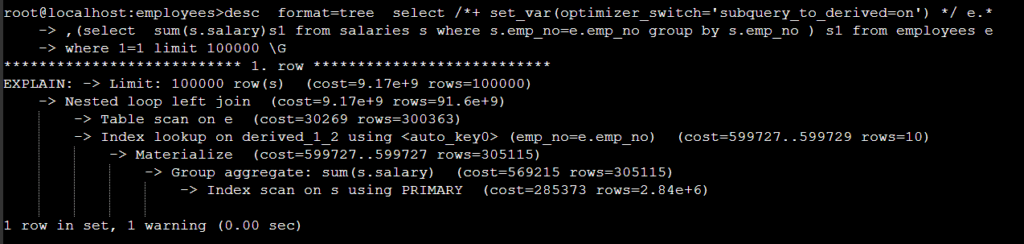
show warnings\G 실행시 SQL 추출되지 않는다.

전체 변환된 SQL 를 추출하기 위해서 desc + show warnings\G 으로 실행한다.
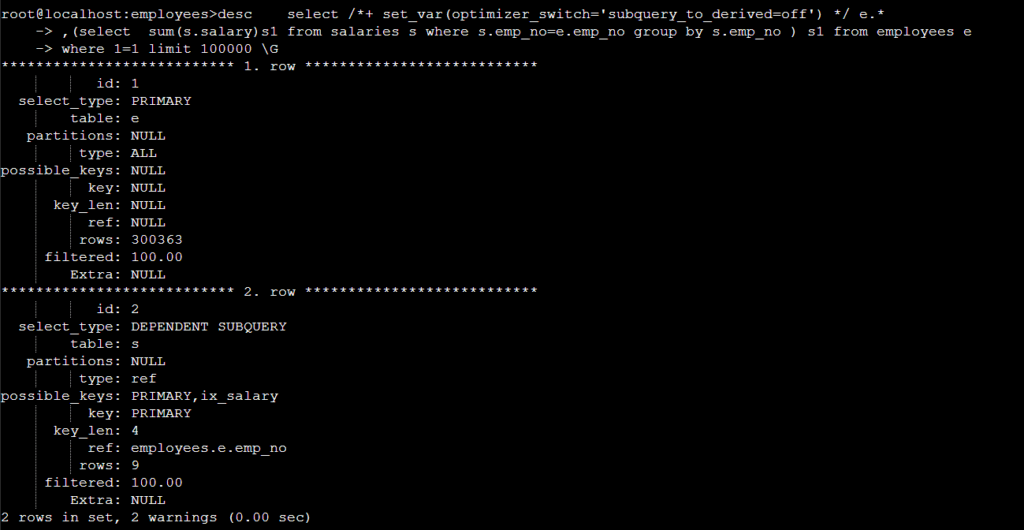
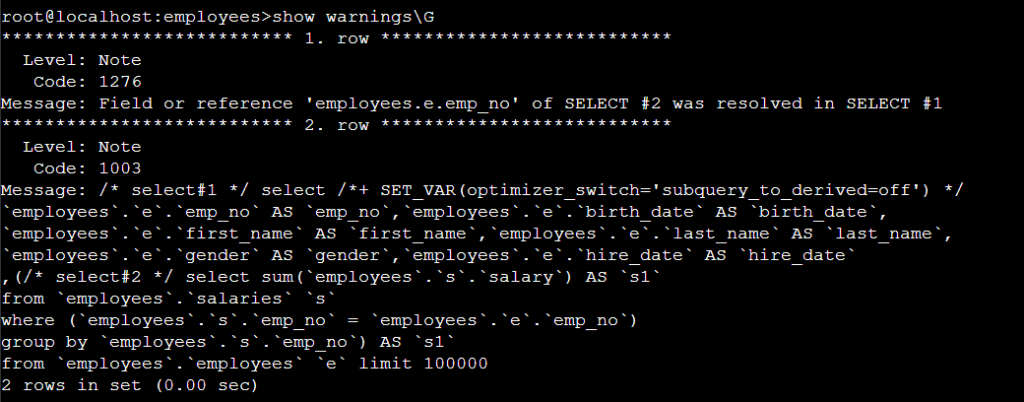
show warnings\G 실행 시 아래와 같이 SQL 출력된다 .
subquery_to_derived=off 시에는 변환 되지 않았다 .
/*+ set_var(optimizer_switch=’subquery_to_derived=on’) */ 힌트로 SQL 레벨로 파라미터를 변경한다 .
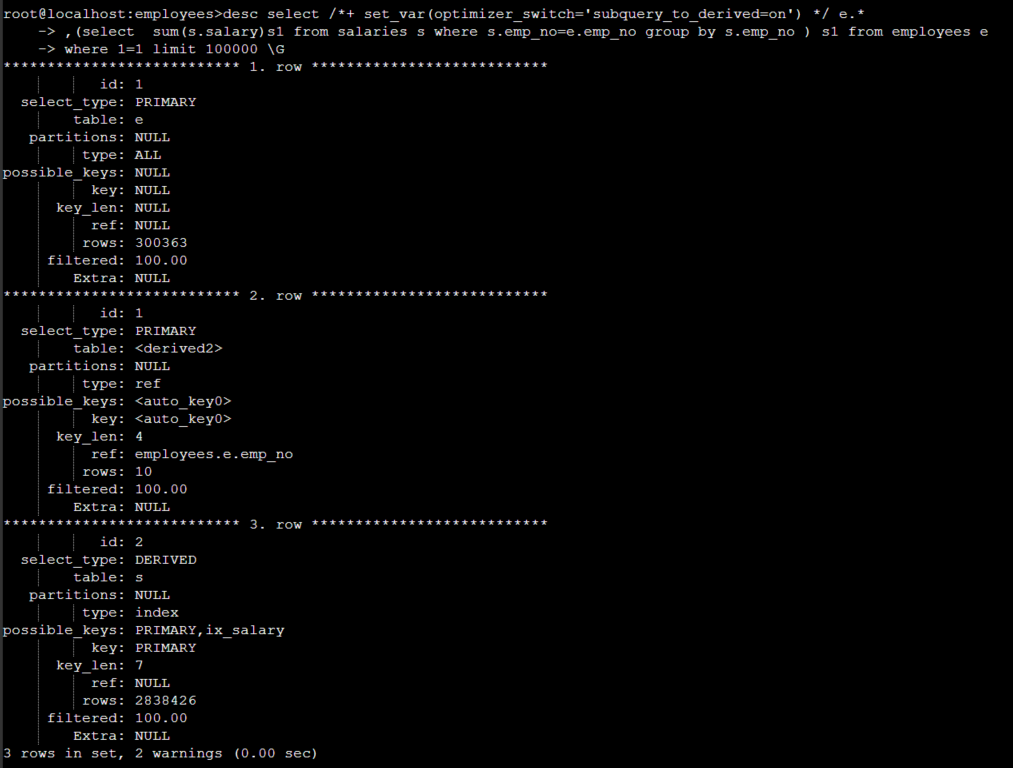
show warnings\G 실행 시 변환된 SQL 출력 되는 걸 확인할 수 있다 .
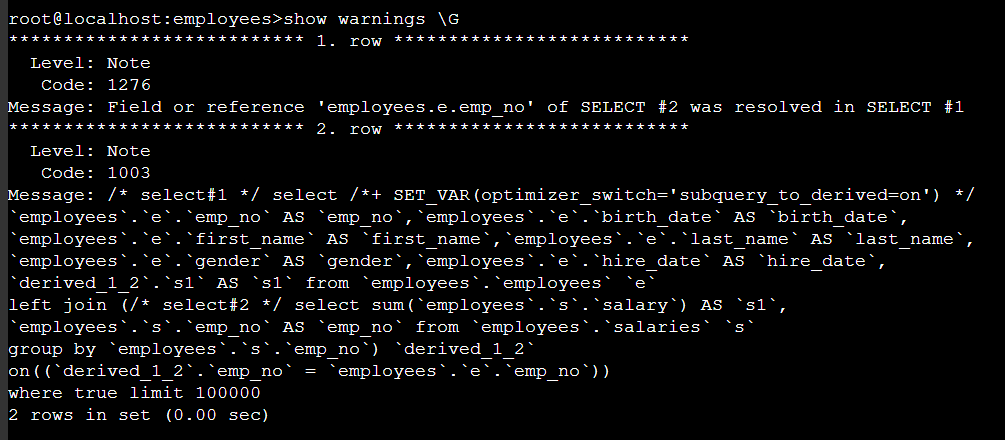
위 subquery_to_derived=on 변경된 SQL 된 것을 보면 DEPENDENT SUBQUERY 가 left join 으로 변경된 것을 확인할 수 있다.
다만 여기에 대해서 성능 상향이 어느정도 있는지는 의문이고 , 이론 상 DEPENDENT SUBQUERY 호출이 엄청 많을 때는 유리할 수 있다 .
OLTP 시스템의 경우는 off 로 하는 것이 좋아 보인다 . 디폴트값도 off 다 .
2). prefer_ordering_index=on
MySQL CBO가 이전에는 order by xx limit 10 같이 limit 에 있는 값이 작을때 order by 의 Using filesort 값을 제거하는쪽을 선택했다 ,현재는 이값을 수동으로 변경가능하게 했다 .
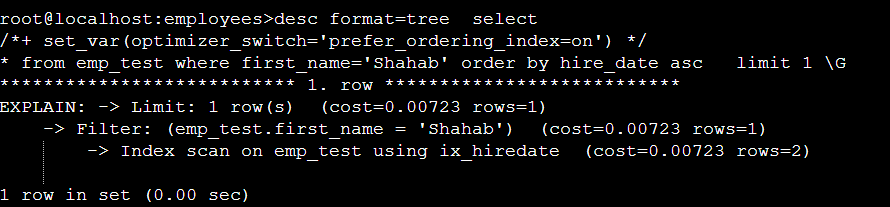
아래2개 SQL 은 prefer_ordering_index=on/off 시 limit 1/limit 100000 에 대해서 실행계획이 변화는 부분이다 .
limit 1 의 실행계획:
limit 1000000 의 실행계획:

위 2개 SQL 를 비교해보면 LIMIT 1 시에 index scan 으로 실행되었다 .
prefer_ordering_index=off 시에는 limit 1/1000000 변화가 있어도 무조건 ref/range 인덱스를 선택한다 .
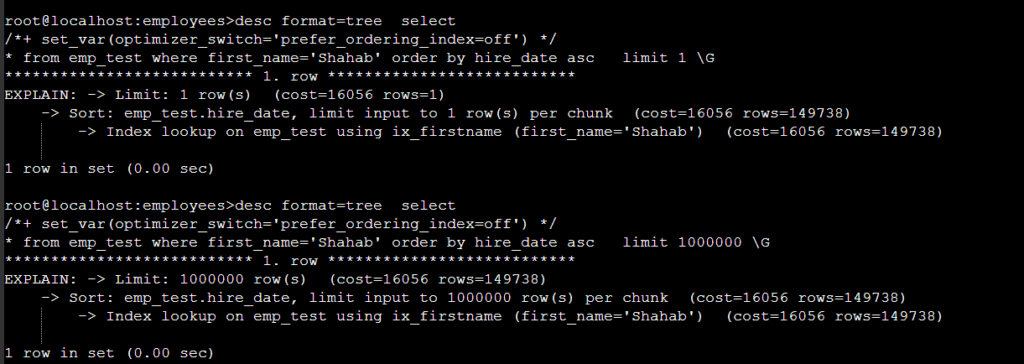
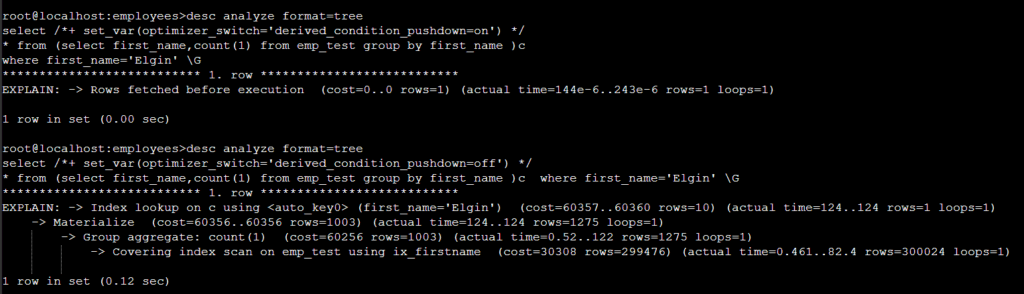
3). derived_condition_pushdown=on
merge 가 되지 않는 view 에 상수 조건을 push down 할수 있는지 여부를 정하는 변수다 .
앞으로도 새로운 기능이나 활용 팁이 생기면 예제와 함께 지속적으로 공유드릴 예정입니다.
읽어주셔서 감사합니다.