전통적인 C 나 Java, 최근의 Python 을 이용한 개발 뿐만 아니라 오라클, PostgreSQL 등의 DB 작업에서 가장 많이 작성되는 것 중 하나는 ‘비교(Comparison)’ 구문이다.
이러한 비교는 동등 (Equality), 부정 (Inequality Not Equal), 부등 (Inequality) 등으로 나눌 수 있는데, 문자열의 비교에서는 많은 경우 아스키코드 (ASCII) 또는 유니코드가 사용된다.
‘a’ 의 아스키 코드는 [97] 이고 ‘a⎵‘ 의 아스키코드는 [97, 32] 이다. 두 문자열의 아스키코드가 다르므로 일반적인 비교 연산에서 아스키 코드를 사용하여 비교한다면 두 문자의 비교결과는 ‘FALSE’ 가 된다.
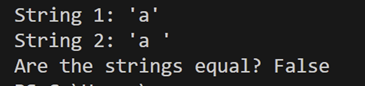
[그림 1] Python 에서의 문자열 비교
데이터베이스에서의 문자열 비교
그렇다면 DB 에서도 동일한 결과가 나오는지 확인해보자.
최근 오픈소스 DB의 강자로 떠오르고 있는 PostgreSQL 에서의 비교 결과는 다음과 같다.
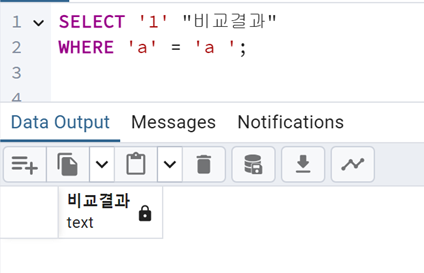
[그림 2] PostgreSQL 에서의 문자열 비교
PostgreSQL 에서도 이전의 Python 의 결과와 마찬가지로 ‘a’ <> ‘a⎵‘ 로 판단하는 것을 확인할 수 있다.
그렇다면, DBMS 점유율1위를 차지하고 있는 Oracle 에서는 어떠한 결과가 나오는지 확인해보자.
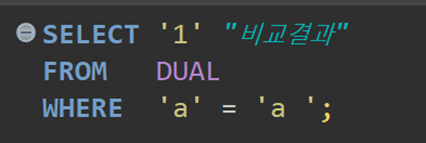
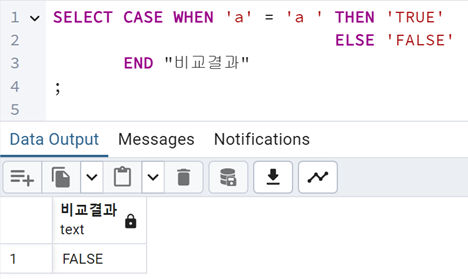
[그림 3] Oracle 에서의 문자열 비교
놀랍게도 Oracle 에서는 ‘a’ = ‘a⎵‘ 라고 판단하고 있는 결과를 보여주고 있다.
다음의 테스트를 진행하면서 조금 더 확인해보도록 하자.
테스트 시나리오는, CHAR 와 VARCHAR2 타입을 가지고 있는 두개의 테이블을 만들고, 지정된 길이보다 작은 값을 넣었을 때 어떠한 결과가 나오는지를 확인할 것이다.
Oracle에서의 문자열 비교 테스트 준비
- 테이블 생성

- 데이터 입력
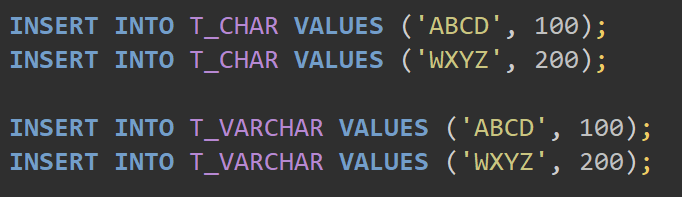
[그림 4] Oracle 에서의 문자열 비교 테스트 준비
1의 스크립트를 이용하여 CHAR(5) 자리와 NUMBER 타입을 가지는 테이블 T_CHAR 와 VARCHAR2(5) 자리와 NUMBER 타입을 가지는 T_VARCHAR 를 만들었다.
2의 스크립트를 이용하여 데이터를 입력하였는데 문자열을 ‘ABCD’, ‘WXYZ’ 만을 입력하였으므로 T_CHAR 에는 ‘ABCD⎵’ , ‘WXYZ⎵‘ 가 저장되었을 것이다.
Oracle에서의 문자열 비교
- T_CHAR 에서 테스트

[그림 5] Oracle에서의 문자열 비교 첫 번째 테스트 쿼리
아래의 결과를 미리 보지 말고 위의 쿼리를 실행할 때, 어떠한 결과가 나올지 잠시 고민해본 후 결과를 확인해보기 바란다.
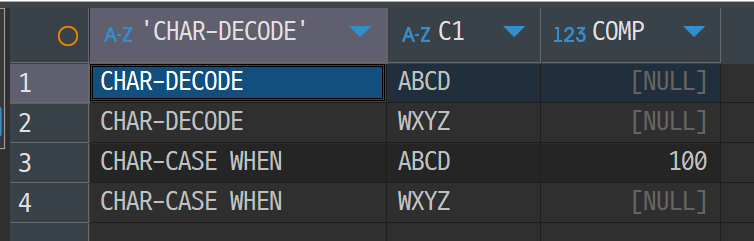
[그림 6] Oracle에서의 문자열 비교 첫 번째 테스트 결과
위는 3의 쿼리 결과이다. 생각했던 결과와 어느정도 일치했는지 비교해보자
- T_VARCHAR 에서 테스트

[그림 7] Oracle에서의 문자열 비교 두 번째 테스트 쿼리
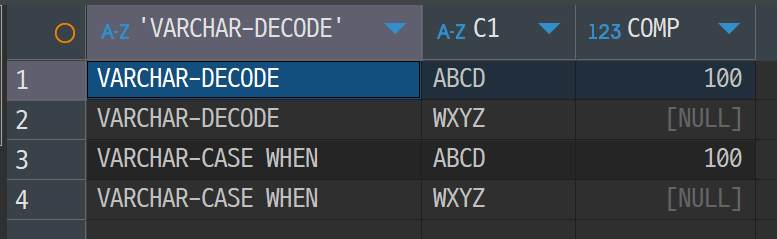
[그림 8] Oracle에서의 문자열 비교 두 번째 테스트 결과
위 테스트는 크게 두 가지의 차이점을 보이고자 한다.
하나는 CHAR 와 VARCHAR 의 차이이고, 또 하나는 DECODE 와 CASE WHEN 에서의 차이이다.
먼저 3의 결과를 살펴보면, CASE 문으로 ‘ABCD’ 와의 값을 비교했을 때 TRUE 가 된 것을 확인할 수 있다. 4의 결과에서는 VARCHAR2 데이터타입이므로 ‘ABCD’ 가 그대로 입력되었을 것이고 DECODE 와 CASE 문 모두 동일한 결과값을 보이고 있다.
지금까지 몇가지 사례를 소개하였는데, 이제 그 이유를 알아보자.
COMPARISON SEMANTICS
오라클에는 크게 두가지의 Comparison Semantics 를 소개하고 있는데, 내용은 다음과 같다.
 |
| Blank-Padded Comparison Semantics를 사용할 때, 두 값의 길이가 다르면 Oracle은 먼저 더 짧은 값의 끝에 공백을 추가하여 길이를 같게 합니다. 그런 다음 Oracle은 두값을 문자별로 첫 번째 다른 문자가 나올 때까지 비교합니다. 첫 번째 다른 위치에 더 큰 문자가 있는 값이 더 큰 것으로 간주됩니다. 두 값에 다른 문자가 없는 경우 동일한 것으로 간주됩니다. 이 규칙은 두 값이 후행 공백의 개수만 다를 경우 동일하다는 것을 의미합니다. Oracle은 비교에서 두 값이 모두 CHAR, NCHAR 데이터 유형의 표현식, 텍스트 리터럴 또는 USER 함수에서 반환된 값일 때만 Blank-Padded Comparison Semantics 를 사용합니다. NonPadded Semantics 를 사용하면 Oracle은 두 값을 문자별로 첫 번째 다른 문자까지 비교합니다. 해당 위치에 더 큰 문자가 있는 값이 더 큰 것으로 간주됩니다. 길이가 다른 두 값이 더 짧은 값의 끝까지 동일하면 더 긴 값이 더 큰 것으로 간주됩니다. 길이가 같은 두 값에 다른 문자가 없으면 값이 같다고 간주합니다. Oracle은 비교되는 데이터 유형이 하나 또는 두개 모두 VARCHAR2 또는 NVARCHAR2일 때 NonPadded Semantics 를 사용합니다. |
처음 예시를 들었던 ‘a’ = ‘a⎵’ 가 되는 이유가 WHERE 조건에서 텍스트 리터럴을 사용했고, 이에 오라클은 Blank-Padded Comparison Semantics 를 적용했기 때문이다.
Blank-Padded 와 Nonpadded 를 적용했을 때 비교 결과는 다음과 같다.

[그림 9] Oracle 에서의 Comparison Semantics 에 따른 결과 비교
이제 처음 살펴보았던 SELECT ‘1’ “비교결과” FROM DUAL WHERE ‘a’ = ‘a⎵‘ 의 결과가 ‘1’ 이 나온 것은 Blank-Padded Semantics 가 적용되었기 때문이라는 것은 알게 되었다.
DECODE vs. CASE
오라클 데이터베이스를 사용하는 환경에서 쿼리를 작성할 때 아주 유용하게 사용되는 함수로 DECODE가 있다. 다만, 이것은 ANSI 표준이 아닌 오라클 자체 함수이기 때문에, 타 DBMS 로 전환할 때는 일반적으로 CASE 문으로 대체하여 사용하게 된다. 즉, 대부분의 경우에서 DECODE 의 로직은 CASE 로 대체되어야 하나, 그렇지 않을 수도 있다는 것을 위의 사례에서 확인할 수 있었다.
그렇다면 어떻게 DECODE 와 CASE 문의 결과가 다를 수 있는지 그 이유도 계속해서 알아보도록 하자.
DECODE 구문의 COMPARISON SEMANTICS
 If expr and search are character data, then Oracle compares them using nonpaddedcomparison semantics. expr과 search가 문자 데이터인 경우 Oracle은 nonpadded comparison semantics 를 사용하여 이를 비교합니다. |
오라클 매뉴얼의 DECODE 설명에 따르면, DECODE 구문의 첫번째, 두번째 인자가 모두 문자열이면 DECODE 는 Nonpadded Comparison Semantics를 적용한다고 한다.
CHAR vs. VARCHAR2
지금까지 살펴본 사례 중 조금은 어색한 결과를 보여준 것은 모두 텍스트 리터럴을 사용하거나 CHAR 데이터타입이 사용되어 그 결과로 Blank-Padded Comparison 이 적용되 었을 때 발생한 것이다. 그렇다면 ‘계속 CHAR 데이터 타입을 사용해야 하는 것인가?’ 에 대해 다수의 오라클 관련 저서의 저자이자 오라클 엔지니어인 ‘Thomas Kyte’ 는 어떤 의견을 가지고 있는지 한번 살펴보도록 하자.
ASK TOM 에 이와 비슷한 질문에 그의 답변이 있는데 다음과 같다.
| It is for these reasons the fixed-width storage, which tends to make the tables and related indexes much larger than normal, coupled with the bind variable issue— that I avoid the CHAR type in all circumstances. I cannot even make an argument for it in the case of the one-character field, because in that case it is really of no material difference. The VARCHAR2(1) and CHAR(1) are identical in all aspects. There is no compelling reason to use the CHAR type in that case, and to avoid any confusion, I “just say no,” even for the CHAR(1) field. (출처 Char Vs Varchar – Ask TOM) 고정 너비 저장소는 테이블과 관련 인덱스를 정상보다 훨씬 크게 만드는 경향이 있고, 바인드 변수 문제와 결합되어, 저는 모든 상황에서 CHAR 유형을 피합니다. 1문자 필드의 경우에도 옹호할 수 없는데, 그 경우에도 실제 아무런 차이가 없기 때문입니다. VARCHAR2(1)과 CHAR(1)은 모든 면에서 동일합니다. 1문자 필드의 경우에도 CHAR 유형을 사용해야 할 이유가 없으며, 혼란을 피하기 위해 CHAR(1) 필드에 대해서도 “그냥 안 한다”고 말합니다. |
결론
이번 글에서 이야기 하고자 하는 것은, 사용하는 DBMS 의 특성에 따라 같은 로직/쿼리의 실행결과가 달라질 수 있다는 부분이다. DBMS 의 동시성 제어의 특성에 따라 같은 UPDATE문을 실행한다고 해도 Oracle 과 SQL Server의 결과가 달라지는 것 처럼, 같은 비교 구문을 실행할 때에도 사용하는 DBMS 에 따라 결과가 달라질 수 있다는 것은 개발자가 알고 있어야 하는 또 하나의 숙제가 될 수도 있을 것이다.
분명 이유가 있어 CHAR 데이터타입을 만들었을 것이고 Blank-Padded Comparison Semantics 도 적용을 하겠지만, Python 등의 개발언어와도 차이가 발생하고 PostgreSQL 등의 타 DBMS 와 다른 결과가 나오는 것을 어떻게 받아들여야 하는 것일까?
개인적인 결론은 CHAR 의 지양과 VARCHAR2의 사용이다.
쿼리의 조건에서 문자 리터럴을 사용하지 않고, 불필요한 공백이 들어가지 않도록 하는 것도 방법일 수 있겠으나 그것은 작은 부분이고, 상식적이고 일반적인 결과를 도출하기 위해서는 가능한 CHAR 데이터타입의 사용을 지양하는 것이다.
위 사례에도 나와 있지만, VARCHAR2 데이터 타입을 사용할 때는 개발언어와 타 DBMS와 비교해봐도 동일한 결과를 얻을 수 있으며, 또한 그 결과가 일반적인 상식에서 크게 벗어나지 않는다.
다만, 공공기관 프로젝트를 수행할 때에는 CHAR 로 정의되어 있는 표준도메인, 표준용어를 적용해야 하므로 오라클과 티베로를 사용하는 공공프로젝트에서는 위와 같은 Comparison Semantics 와 DECODE 와 CASE 문의 차이가 있다는 점은 알고 있어야 할 것이다.
[참고문헌]
1. Oracle Manual (sql-language-reference)
2. 네이버 카페 – 디비안